はじめに
AWS DynamoDBは、スケーラブルでフルマネージドなNoSQLデータベースサービスです。この記事では、DynamoDBの基本的な使い方について学び、実際にデータベースを構築・操作する手順を解説します。
これからDynamoDBを利用したアプリケーション開発を始める方に向けて、わかりやすく説明していきます。
DynamoDBについて
DynamoDBの主な特徴を整理します。まず、DynamoDBはフルマネージドであり、サーバーの管理が不要で、スケーリングやバックアップも自動で行われます。

また、DynamoDBは高いパフォーマンスを発揮し、固定のスループットを維持しながら必要に応じて柔軟にスケールします。
さらに、JSON形式でデータを保存でき、属性(カラム)を自由に追加できる柔軟なデータモデルが特徴です。
NoSQLとは
NoSQL(Not Only SQL)は、リレーショナルデータベースとは異なるデータベースの一種で、主に非構造化データや大規模なデータセットの管理に適しています。
NoSQLは、従来のSQL(Structured Query Language)を使わず、もしくは拡張してデータを管理するシステムの総称です。
以下では、NoSQLとSQLの違いに焦点を当てながら、NoSQLの特徴や利点について解説します。
NoSQLの特徴
スキーマレス(Schema-less)
NoSQLは固定のスキーマを持たず、データの形式を事前に定義する必要がありません。これにより、データの形式が変更された場合でも柔軟に対応でき、新しいデータタイプを簡単に追加できます。
スケーラビリティ(Scalability)
NoSQLデータベースは、水平スケーリング(サーバーの追加による性能向上)に適しており、クラウド環境や分散システムで効率的に運用できます。これに対し、SQLは通常、垂直スケーリング(サーバー性能の向上)を主とします。
引用画像:https://www.geeksforgeeks.org/types-of-nosql-databases/
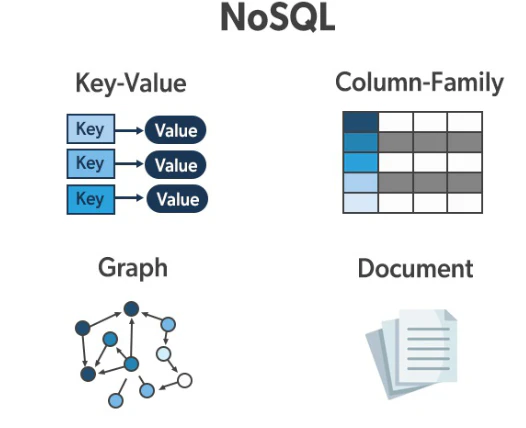
データモデルの多様性
NoSQLにはいくつかのデータモデルがあります。代表的なものには以下の4つがあります。
キーバリューストア:
RedisやAmazon DynamoDBなどがこれに該当し、シンプルにキーと値のペアを保存します。
ドキュメントストア:
MongoDBやCouchbaseはこのタイプで、JSON形式やBSON形式でデータを保存し、柔軟に扱えます。
グラフ型データベース:
Neo4jのように、ノードとエッジを使用してデータ間の関係性を重視して管理します。
カラム指向データベース:
Apache Cassandraなど、行ではなく列単位でデータを管理するため、特定の列を迅速に読み取ることが可能です。
柔軟なクエリ言語
NoSQLデータベースは、必ずしもSQLを使用せず、データベースごとに特有のクエリ言語を持つことがあります。例えば、MongoDBでは「MQL(Mongo Query Language)」が使われます。
SQLとの違い

引用画像:https://pt.linkedin.com/pulse/introdu%C3%A7%C3%A3o-nosql-jo%C3%A3o-victor-mar%C3%A7ura
スキーマの柔軟性
SQLデータベースでは、テーブルのスキーマを固定して定義する必要がありますが、NoSQLではスキーマレスのため、柔軟にデータを追加できます。
リレーションとデータの整合性
SQLはリレーショナルデータベースであり、データの整合性を重視したACIDトランザクションに対応しています。

一方、NoSQLは分散システムでの可用性やスケーラビリティを重視し、CAP定理に基づく設計がされています。
クエリの複雑さ
SQLデータベースは複雑なクエリが得意ですが、NoSQLはシンプルなクエリに適しており、特定のデータモデルに対して最適化されています。
スケーリングの方法
SQLは主に垂直スケーリングを前提としていますが、NoSQLは水平スケーリングに適しており、クラウドサービスでの運用に強みを持っています。
AWS DynamoDBの使い方とハンズオン手順
以下の手順でDynamoDBテーブルを作成し、データを操作します。
ステップ 1: DynamoDBテーブルの作成
まず、AWSコンソールにログインし、DynamoDBサービスを選択します。

そして「テーブルの作成」ボタンをクリックし、テーブル名としてUsersを入力し、プライマリキーとしてidを設定します。

このIDはユニークなユーザーを識別するために使用され、必要に応じて他の属性(例: name, emailなど)も設定します。

ステップ 2: DynamoDBにデータを追加
次に、作成したUsersテーブルを選択し、「項目の作成」ボタンをクリックしてユーザー情報を入力します。

例えば、idに1、nameにAlice、emailにalice@example.comというデータを追加します。これでDynamoDBにデータが追加されました。

ステップ 3: データの取得
次に、DynamoDBコンソールのUsersテーブルに戻り、テーブルの項目一覧が表示されるので、作成した項目を選択します。

追加したユーザー情報(例えばAlice)のデータが表示されます。
ステップ 4: データの更新
次に、Usersテーブルを選択し、更新したい項目(例: Aliceのデータ)を選択します。
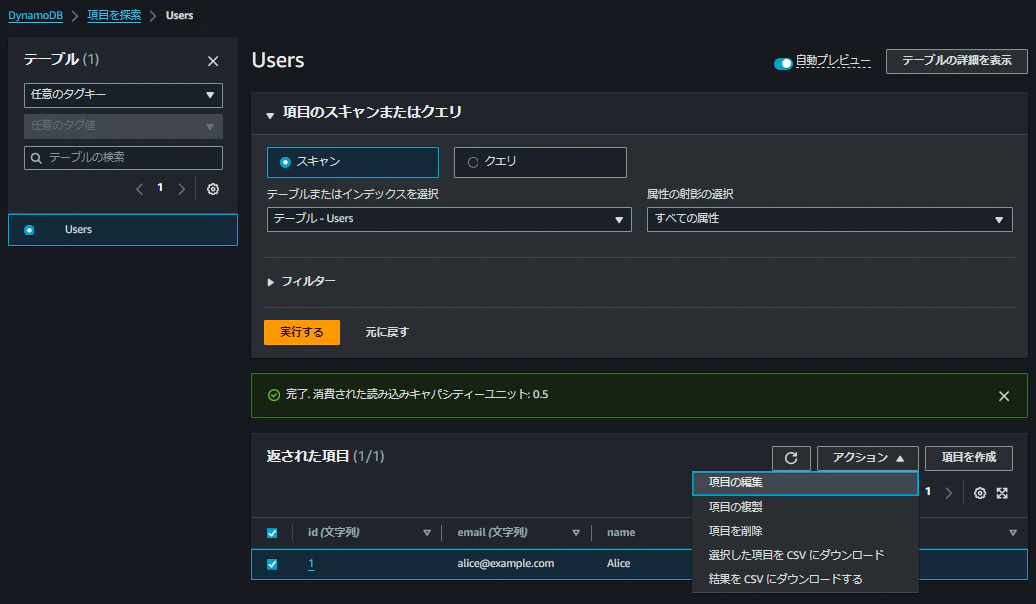
「項目の編集」をクリックし、必要な属性を変更します。
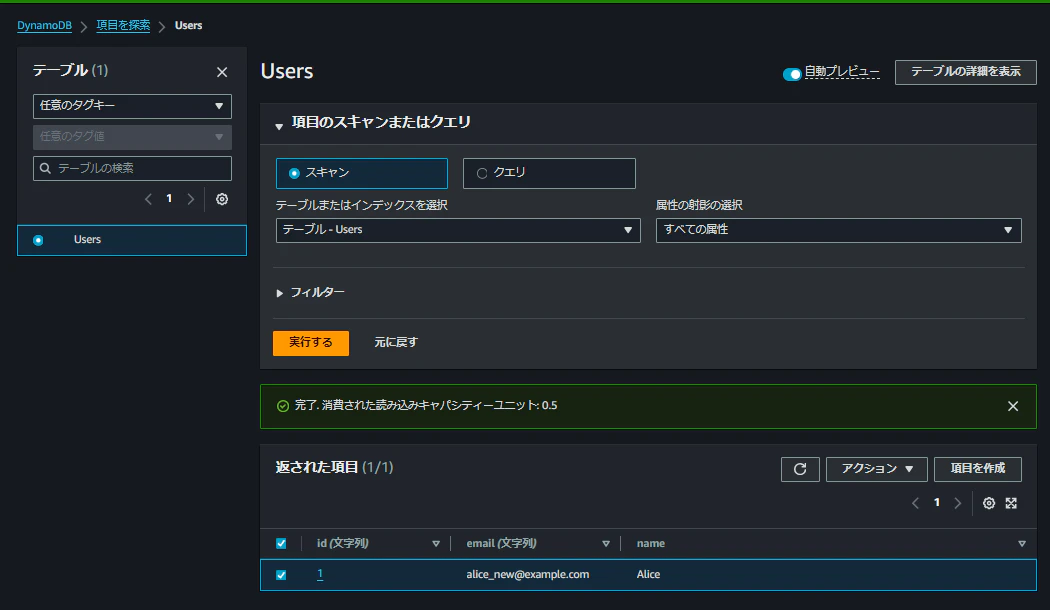
例えば、emailをalice_new@example.comに更新し、保存をクリックして変更を適用します。
ステップ 5: データの削除
最後に、更新したい項目(例: Aliceのデータ)を選択し、「項目の削除」をクリックして削除を確認します。

これでAliceのデータがDynamoDBから削除されます。

まとめ
DynamoDBを用いたデータベースの構築と操作について解説しました。DynamoDBはスケーラブルでフルマネージドなデータベースで、様々なユースケースに対応可能です。AWSの他のサービスと組み合わせて、実際のアプリケーションに活用してみてください。
DynamoDBの詳細な機能や最適な使用法を学んでいくことで、より高度なアプリケーションを開発できるようになります。
おまけ:NoSQLの主なユースケース
リアルタイムデータ分析
大量のデータを迅速に処理するため、NoSQLはIoTデバイスからのデータやリアルタイムでのフィードを扱うのに適しています。
柔軟なデータモデルが必要な場合
ソーシャルネットワーキングサイトやブログプラットフォームなど、異なるタイプのデータを持つアプリケーションで使用されます。
大規模データ
大量のトラフィックを処理するWebアプリケーション(例: FacebookやTwitter)では、NoSQLの水平スケーリングによってデータを効率的に処理できます。
参考文献