概要
この記事はServerless Advent Calendar 2020 10日目の記事です。
今年こそは自分もアドベントカレンダー楽しみたい!!と流れに乗じて初投稿です。
拙い点もあるかもしれませんがご容赦ください。
さて本題ですが、Serverless Framework、みなさん使っていますか?
私自身も最近業務でサーバーレスなマイクロサービスを開発する機会があり、そこでもServerless Frameworkを利用しました。
やはり簡単にリソースを管理できる点、またデプロイが1コマンドだけで完結する点も非常に便利ですね。
そんなServerless Frameworkですが、実際に開発、運用をするにあたって重要となる機能や設定がいくつかあります。
今回は、これからServerless Frameworkを使って開発を行いたい人に向けて、
私がServerless Frameworkを使っていて思った「これを知るとより良く使えるな」と思うポイントをいくつか紹介したいと思います。
これを知ることで、"はじめの一歩"の次の一歩が踏み出せるのでは、と思っています。
想定読者
- AWSに触れたことがある
- Serverless Frameworkに触れたことはある
- 実際のシステムでServerless Frameworkを利用するイメージがまだ湧かない
- IaCに興味がある
この記事で紹介すること
この記事では前述のような「Serverless Frameworkを使い始めたばかりの人」が実際のシステムにServerless Frameworkを活用するにあたっての
-
serverless.ymlの書き方 - おすすめの設定
- プラグインの使い方
について記載しています。
この記事で紹介しないこと
- この記事は「Serverless Frameworkの使い方」に焦点を当てた解説記事です。
リソースとしてLambda等は登場しますが、それらのリソースの具体的な利用方法等についてはこの記事では範囲外としています。 - この記事では対象のプロバイダとしてAWSを想定しています。
そのためGCP/Azure等他プロバイダでの利用方法については記載していません。
今回のゴール
今回この記事が目指すゴールは以下のリポジトリのようなプロジェクトが作成できるようになることです。
サンプルリポジトリ
このプロジェクトは、以下のようなシンプルな構成のものです。
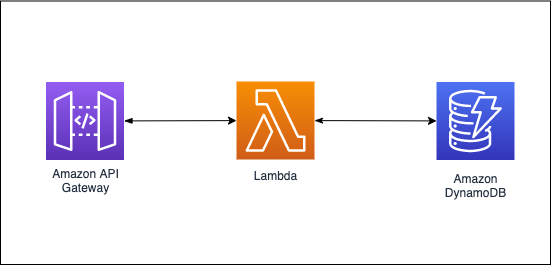
よく知るAPI Gateway + LambdaのAPIに、DBとしてDynamoDBが追加されているイメージです。
今回はこのプロジェクトに対して、
- コマンド一つでサービス全体をデプロイする
- 開発用/本番用と複数のステージで使い分ける
- 長期に運用する
という観点でどうServerless Frameworkを活用していけば良いかを考えていきます。
1. リソースを定義して読み込む
Serverless Frameworkにおいて、API Gateway + Lambdaの構成はserverless.ymlのfunctionsに記載を行うことで簡単に作成ができます。
↓以下のようなコードですね。
functions:
foo:
handler: foo.lambda_handler
event:
- http:
path: /foo
method: get
ただ今回のゴールのプロジェクトのように、DynamoDB等の周辺リソースも利用を行いたいケース、というのは多々あるかと思います。
API分をデプロイした後にコンソールから手動で作成、でも良いのですが、
せっかくコマンド1つでAPI Gateway + Lambdaをデプロイできるようになっているので、そういった周辺リソースもまとめてデプロイができるように設定しましょう。
またデプロイもそうですが、リソースを削除する際も、sls removeコマンドによって綺麗に削除することができます。
こうしてデプロイ/削除をシステム単位で簡単に行えるようにすることで、システムのポータビリティ、再利用性の向上が望めます。
resourcesに必要なリソースを追加する
serverless.ymlでは、resourcesの項目に必要なリソースの情報を記載することで合わせてデプロイすることができます。
例えばDynamoDBの場合は以下のように記載します。
# ..略..
resources:
Resources:
sampleDynamoDB: # リソース名
Type: AWS::DynamoDB::Table # リソースのタイプ
Properties:
TableName: sampleDB # DynamoDBのテーブル名
AttributeDefinitions: # テーブルのキー情報
- AttributeName: id # キー名
AttributeType: N
KeySchema:
- AttributeName: id
KeyType: HASH
ProvisionedThroughput: # スループット値
ReadCapacityUnits: 1
WriteCapacityUnits: 1
急に設定項目が多いと感じてしまうかもしれませんが、
これらはAWSのリソース管理サービスであるCloudFormationのテンプレート記法に準拠しています。
それぞれのリソースによってProperties以下に何を記載すれば良いかが変わりますが、CloudFormationのドキュメントが非常に親切なので、そちらを見つつ順番に設定を書いていけば問題なく記載できるでしょう。
これによって、sls deployコマンドでDynamoDBも一緒にデプロイすることができるようになりました。
各リソースを外部ファイルに分割する
前節で様々なリソースをserverless.ymlに記載できるようになりました。
今回のようにDynamoDBのテーブル1つだけ等であれば対して気にはなりませんが、実際にシステムで利用するリソースをいくつも記載していくと、resources下のコードの行数がみるみる増えていきます。
あんまりserverless.ymlが長いと後でそのコードを読んだ人が困ってしまうので、ファイルを分割して外部から読み込めるようにしましょう。
serverless.ymlでは、${file(<ファイルへのパス>)}を記載してあげることで外部ファイルからコードを読み込むことができます。
これを利用して、以下のようにコードを分割していきます。
.
├── resources
│ └── dynamodb_sample.yml
└── serverless.yml
まずはdynamodb_sample.ymlを作成します。
以下のようにserverless.ymlのresourcesに記載していた内容をdynamodb_sample.ymlに移しましょう。
Resources: # ←この行の記載を忘れない
sampleDynamoDB:
Type: AWS::DynamoDB::Table
Properties:
###~以下は同じ~###
ここで読み込む側のファイルにResourcesの記載を忘れないようにしてください。これがないと正しく読み込まれません。
ではserverless.yml側でこちらを読み込むようにします。
resourcesを以下のように修正します。
...
resources:
# 外部ファイルからリソースを読み込み
- ${file(./resources/dynamodb_sample.yml)}
これでコードがすっきりしましたね。今後新しいリソースを追加したい場合は同様にリソースを定義したYAMLファイルを作成し、
resourcesのリストに追加すればOKです。
この章のまとめ
-
resources下に周辺リソースが定義できる - 書き方はCloudFormationのヘルプを見よう
-
${file(<ファイルへのパス>)}を使ってファイルを分割しよう
2. 複数環境へデプロイするための設定を行う
さて、前章で周辺リソースも定義したプロジェクトを作成できました。
しかし今のままだと同一リージョンにステージ名を変えてデプロイしようとするとエラーが出てしまいます。
これは前章で定義したDynamoDBで、リソース名が重複してしまうためです。
そこでこの章では、変数を利用してステージによってリソース名を変えるように修正を行い、複数のステージへのデプロイができるように設定していきます。
Serverless Frameworkの変数
serverless.ymlでは、デプロイ時に値が決定するような変数を利用することができます。
変数は${<タイプ>:<内容>}という記法で表現されます。前章に出てきた${file}と近いものだと思ってもらうとわかりやすいでしょう。
今回はこの中でも最も良く使う
${opt:}${self:}
を紹介しつつ、これらを利用してデプロイする環境に合わせてリソースの名前を変更していきましょう。
opt
opt変数は、デプロイする際のsls deployコマンドにて指定したオプションを取得することができます。
今回はAWS上の「どのリージョン」に「何というステージ名で」デプロイを行うかを取得したいと思います。
serverless.ymlのprovider下に以下の内容を追記します。
provider:
#..略..
stage: ${opt:stage, "dev"}
region: ${opt:region, "us-east-1"}
このように記載することで、sls deployのオプションである--stage, --regionにて指定した値を取得して、provider.stageに値を設定することができます。
なお、opt変数内でstage、regionの後に指定している"dev", "us-east-1"は、オプションが指定されなかった場合のデフォルト値です。
よってオプションと実際に入力された値は、以下のような例となります。
sls deploy --stage prod --region ap-northeast-1
=>stage: prod, region: ap-northeast-1
sls deploy --stage prod
=>stage: prod, region: us-east-1
sls deploy
=>stage: dev, region: us-east-1
このように、コマンドのオプションで値を振り分けることができるようになりました。
なおご存知の方もいるかもしれませんが、実はprovider下に内容を記載しなくても、オプションで指定をしたリージョン、ステージに対してデプロイを行うこと自体は可能です。
ただこの後リソース名にこの値を使う際の準備としてここでは明示的に記載を行っています。
self
self変数は、serverless.yml内の別箇所で設定されている値を取得することができます。
今回はこれを利用して、デプロイした際のステージ名をリソース名につけてあげましょう。
./resources/dynamodb_sample.ymlを以下のように修正します。
Resources:
sampleDynamoDB:
Type: AWS::DynamoDB::Table
Properties:
# TableName: sampleDB
TableName: sampleDB-${self:provider.stage}
###~以下は同じ~###
${self:provider.stage}を追加しました。これによってデプロイ時には、serverless.ymlのprovider.stageに設定された値が代わりにここに入ります。
前節にてprovider.stageは${opt:stage, "dev"}と設定しているので、
オプションでステージを指定した場合もそのステージ名がリソース名に反映されます。
これによって複数ステージにデプロイを行うことができるようになりました。
環境変数を利用する
複数環境にデプロイを行うとき、例えばデプロイするステージによって連携先のシステムのステージも切り替えたい、なんていう要望が出てくることも考えられます。そんな時には環境変数を利用するのが便利です。
環境変数を扱うのに、一般的に良く使われているのが.envファイルです。
Serverless Frameworkでは標準の機能では.envファイルを読み込むことはできませんが、プラグインによってデプロイ時に.envファイルから環境変数を読み込むことができるようになります。
プラグインはServerless Frameworkの拡張機能として作られているもので、これをインストールすることで様々な拡張機能を利用することができます。
今回は.envを取り扱うための、serverless-dotenv-pluginをインストールして利用していきます。
serverless-dotenv-pluginの適用
まずはserverless-dotenv-pluginをインストールします。
Serverless Frameworkのプラグインはnpmで配布されているためnpm installでもインストール可能です。ただ自動でpackage.jsonを作成してくれたりと便利な点があるので、serverless plugin installコマンドを利用することをおすすめします。
プロジェクトのディレクトリで以下のコマンドを実行し、serverless-dotenv-pluginをインストールします。
serverless plugin install -n serverless-dotenv-plugin
これでプラグインのインストールができました。
次はserverless.ymlで利用することを宣言します。
以下のようにserverless.ymlに追記します。
provider:
#..略..
plugins:
- serverless-dotenv-plugin
package:
exclude:
- node_modules/**
functions:
#..略..
これでこのプロジェクトでserverless-dotenv-pluginを利用する準備ができました。
なお、その下のpackage.excludeの部分は、インストールしたプラグインをLambdaにデプロイするファイルに含めないようにする設定です。これをしないとデプロイパッケージがどんどん大きくなってしまうので設定することをお勧めします。
それでは環境変数を読み込んでLambdaに渡してあげるようにしましょう。
まずは.envを作成します。
ENV_PARAM1=hoge
ENV_PARAM2=fuga
それではこれを読み込みます。serverless-dotenv-pluginによってデプロイ時にターミナル環境変数に.envファイルの中身が展開されます。
その環境変数をLambdaに設定してあげるために、以下の設定を追記します。
provider:
#..略..
environment:
# dotenvファイルから読み込んだ環境変数はここで受け取っておくことで各関数に展開される
ENV_PARAM1: ${env:ENV_PARAM1}
ENV_PARAM2: ${env:ENV_PARAM2}
${env:}変数は環境変数を読み込むことができます。これをprovider.environmentで渡してやることで、それぞれのLambda関数に対して環境変数が展開されました。
あとはLambdaの関数内でこの値を読み込めば利用することができます。
(Pythonでいうos.environ.get()等)
この章のまとめ
-
serverless.ymlの便利な変数を利用しよう- opt :
serverless deployで指定した値を取得 - self :
serverless.yml内の値を取得
- opt :
- 複数ステージへのデプロイ時にはリソース名にステージ名を付けてあげるのがお勧め
- 環境変数は
.envファイルで管理するのが良い -
serverless-dotenv-pluginと${env:}変数で.envの内容をLambdaに展開できる
3.長期運用時のトラブルを減らす
実際のシステムでは、デプロイした直後には気づかないが、長期に運用していくにあたって発生してくる問題、というものがいくつもあります。
それらは適宜対応する必要がありますが、設定をきちんと行っておくことで先回りして対処しておけるものもあります。
最後に転ばぬ先の杖的な設定を2つ紹介します。
serverless-prune-pluginでバージョンを整理する
Serverless Frameworkでデプロイしたプロジェクトを長期に利用する場合、新たな機能を追加したり不具合を修正したりと継続的に内容を更新していくことになるかと思います。
serverless deployでデプロイ完了してコンソールを見ると、あたかも前の内容は消えて新しい内容に上書きされているように思えますが、
実はAWS上には前のコードもバージョニングされ保存されています。
これ自体は良い機能なのですが、気づかずにどんどん更新していくと、いずれ各リージョンごとのLambdaのデプロイ可能データ量の上限に達してしまいます。
このような事態を事前に防ぐため、serverless-prune-pluginを利用して保存するバージョン数を指定してあげましょう。
serverless plugin installでインストール後に、以下の内容をserverless.ymlに追記します。
plugins:
#..略..
- serverless-prune-plugin
custom:
# serverless-prune-pluginの設定
# 自動で最新3バージョン以外は削除する
prune:
automatic: true
number: 3
このように設定してあげることで、最新の3バージョン以外は自動で削除されるようになり、前述の問題は起こらなくなります。
CloudWatch Logsのログ保存期間の設定
Lambda内で出力されたログはCloudWatch Logsに集められ保存されます。
デフォルトの設定ではこのログは無期限に保存するようになっています。
ここで問題になるのが、CloudWatch Logsの利用料金は意外と高い、という点です。
試しにデプロイしてログを見る程度であれば気にする必要はないですが、長期的に運用していくとCloudWatch Logsに蓄積されたログによって利用料金がじわじわと増えていきます。
このようなことにならないように、Serverless FrameworkではCloudWatch Logsのログ保存期間を設定できます。
serverless.ymlのprovider下に以下の内容を追記します。
provider:
#..略..
logRetentionInDays: 5 # ログ保存期間を5日に設定
これによって5日以上経過したログは自動で削除されるようになります。
ログはKinesis Firehose等を利用してS3など安価なストレージに移すようにしましょう。
最後に最終的なプロジェクトとserverless.ymlの全体像を貼っておきます。
.
├── functions
│ ├── hello1.py
│ └── hello2.py
├── node_modules
├── package-lock.json
├── package.json
├── resources
│ └── dynamodb_sample.yml
└── serverless.yml
service: sls-samples
frameworkVersion: '2'
provider:
name: aws
runtime: python3.8
# stageとregionはoptからの指定を受け付ける+デフォルト値も指定しておく
stage: ${opt:stage, "dev"}
region: ${opt:region, "us-east-1"}
environment:
# .envファイルから読み込んだ環境変数はここで受け取っておくことで各関数に展開される
ENV_PARAM1: ${env:ENV_PARAM1}
ENV_PARAM2: ${env:ENV_PARAM2}
# CloudWatch Logsのログ保存期間を5日に設定
logRetentionInDays: 5
custom:
# serverless-prune-pluginの設定
# 自動で最新3バージョン以外は削除する
prune:
automatic: true
number: 3
plugins:
- serverless-dotenv-plugin
- serverless-prune-plugin
package:
exclude:
- node_modules/**
functions:
hello1:
handler: functions/hello1.lambda_handler
events:
- http:
path: /foo
method: get
hello2:
handler: functions/hello2.lambda_handler
events:
- http:
path: /bar
method: post
resources:
# 外部ファイルからリソースを読み込み
- ${file(./resources/dynamodb_sample.yml)}
終わりに
内容は以上です。
今回は網羅的ではなく個人的にポイントと思う部分の解説でしたが、参考になる部分がありましたら幸いです。
もちろんServerless Frameworkではより様々なことを実現可能です。
調べたり使ってみたりすることでさらなる理解につながるでしょう。
記事に不明点等ありましたらコメントで質問いただければと思います。
最後まで読んでくださりありがとうございました。