自己紹介
はじめまして。自分は今年からエンジニアとして働いている社会人2年目のfoieです。
最近の松風さんの活躍をみて、自分も買い目を出してくれる競馬AIを自分で作ってみたいという思いが湧いてきました。記録を兼ねて競馬AI作成の過程を投稿していこうと思います。今回はその第一弾。
スキル背景
データ分析とかは全くやったことありません。強いて言えば大学で統計の授業を1コマ取っていたくらい。さらにいうとエンジニアになったのも比較的最近(2019年6月)です。
最近プログラミング初めて競馬のデータ分析とかやってみたいけどどうすればいいのかわからなーい!という方は多いのではないでしょうか。そんな方々の参考になればと思います。
間違ったこととかもっとこうした方がいいのに、みたいなことがあればご指摘くださいm(__)m
目標
2020年に自分で開発した競馬AIで月間回収率100%を達成すること。
参考までに自分が自分で投票してたときの成績を載せます。(2019年12月25日時点)

2019年は散々な結果でした。。
友人達と気合入れて望んだ有馬記念で13万円負けました。アーモンドアイ。。泣
2019年の回収率は74%、こんな自分が2020年に回収率100%超えられたらすごくないですか?
機械学習とかAIってどうやんの?
手始めに下記の方法でで機械学習やAIについて勉強しました。
- AI Academy
- Pythonではじめる機械学習 ―scikit-learnで学ぶ特徴量エンジニアリングと機械学習の基礎
- scikit-learn データ分析 実践ハンドブック (Pythonライブラリ定番セレクション)
勉強したといってもさらーっと読んだくらい。読み飛ばしたりしたとことかめっちゃあるし大体理解していない。
それでもいくつかわかったことがあります。
わかったこと
- 問題設定が大事
- 分析にはデータが必要。それもちゃんとしたデータ、かつ結構な量が必要
- データの前処理が大事
- いろんなモデルがあってむずい
とりあえず実際に予測してみよう
問題設定
善は急げ。惨敗の有馬記念から1週間後、2019/12/28(土)のベストウィッシュカップで3着以内に入線する馬を予想してみましょう!
主な条件
- 中山競馬場、3歳以上2勝クラス、芝、外回り、1600m、定量戦、16頭立
なぜこのレースにしたかというと、全馬前走情報が揃っているレースだったからです。それ以外は特に理由がありません。
データ
KeiBa DataBase Serverを利用してデータを準備しました。netkeiba-scraperを利用して如何様にもデータは準備できるかもしれませんが、そこに労力をかけたくなかったので課金して公式データを利用しています。ただ正直この準備にもちょっとてこずったのでまた別の記事で紹介したいと思います。
また、今回特徴量として使用したデータは以下のとおりです。いろいろ試行錯誤中にタイムリミットを迎えてしまったので、最後は「えいやっ!」で決まりました。
学習対象のデータを中山の1600m-1800mに絞っているので、当日の開催場所と距離は特徴量としては利用しません。
当日の馬の情報
| 項目 | カラム名 | 備考 |
|---|---|---|
| 馬番 | UMANO | |
| 負担重量 | FTNWGHT | |
| 単勝オッズ | TANODDS | |
| マイニング予想走破タイム | DMTIPRUNTM | JRA-VANから提供される予測 |
| 登録レース数 | ENTRNUM | JRA-VANに登録されている成績レース数 |
| 登録頭数 | ENTNUM | 出走馬名表時点での登録頭数 |
1-3走前の情報
| 項目 | カラム名 | 備考 |
|---|---|---|
| 開催場所 | RCOURSECD | |
| 馬番 | UMANO | |
| 確定着順 | FIXPLC | |
| 走破タイム | RUNTM | |
| 2コーナーでの順位 | CONRPLC2 | |
| 3コーナーでの順位 | CONRPLC3 | |
| 4コーナーでの順位 | CONRPLC4 | |
| 単勝オッズ | TANODDS | |
| 獲得本賞金 | GPRZ | |
| 獲得付加賞金 | GAPRZ | |
| 後3ハロンタイム | SH3FL | |
| タイム差 | DIFFTM | 1着馬とのタイム差を設定(自身が1着の場合は2着馬を設定) |
| マイニング予想走破タイム | DMTIPRUNTM | |
| 登録頭数 | ENTNUM | 出走馬名表時点での登録頭数 |
前処理は特に特別なことはしていません。AとかBという文字列で入っているカテゴリ変数を数字に変えたくらいです。あ、あと特徴量の中で利用しているマイニング予想走破タイムですが、これ自体がJRA-VAN様の不屈の努力から様々な特徴量の学習の結果出力されているものなので、これをまた特徴量おして利用するのが良いのか悪いのか自分でも分かっていません。とりあえず有効そうだったので使ってみました。w
モデル
3着以内に入るかか入らないかの2値のクラス分類問題を解きます。
scikit-learnのランダムフォレストで分析してみます。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.8, random_state=0)
model_tree = RandomForestClassifier(bootstrap=True, n_estimators=10, criterion='gini', max_depth=None, random_state=1)
model_tree.fit(X_train_std, y_train)
メインの予測部分はここだけ。どうやらこれで学習したようです。すごい。感動。
モデルの評価
accuracy_score : 0.7806005563737523
precision_score : 0.5566076574722107
recall_score : 0.23980134799574318
f1_score : 0.3351927606297261
こちらのサイトによると、
accuracy_scoreは「本来ポジティブに分類すべきアイテムをポジティブに分類し、本来ネガティブに分類すべきアイテムをネガティブに分類できた割合」を示します。つまり単純な正解率ですね。0.78ということなので、意外といけてるじゃんって思いました。
precision_scoreは「ポジティブに分類されたアイテムのうち、実際にポジティブであったアイテムの割合」を示します。3着以内!と予測してそれが実際に3着以内だった確率になりますね。0.56かあ。しょぼいような。
recall_scoreは「本来ポジティブに分類すべきアイテムを、正しくポジティブに分類できたアイテムの割合」を示します。3着以内だった全ての馬に対して、どれくらいの数3着以内にくると判定できたかの確率ですね。0.24かあ。。
f1_scoreは「精度 (Precision) と検出率 (Recall) をバランス良く持ち合わせているか」を示す指標です。0.34かあ。。。。。。。
あらまー、という感じの結果になりましたが時間がないのでしょうがない。このままで予測しましょう。
いざ予測
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0]
おー!私のプログラムは2番人気の15番ミエノウインウインが3着以内に入ると予測したようです。
(左から馬番1-16の予測結果、1だと3着以内に入ると判定)
鞍上もリーディングジョッキーのルメールですし、それなりに期待できるんではないでしょうか。
結果が楽しみですね。
そして結果
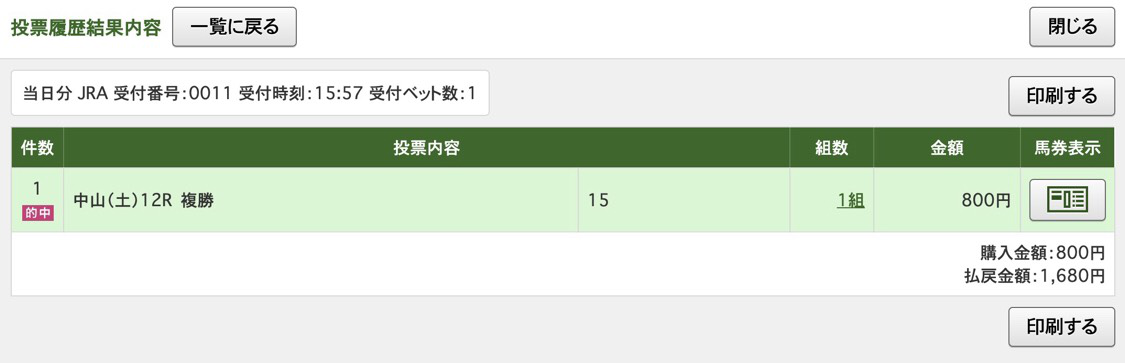
結果はこちら。
なんと1着!!!ミエノウィンウィンのファンになりました。いやもうめっちゃよかった。ありがとうルメール、ありがとうウィンウィン!
記念すべき初めての予測だったので馬券も買っていました。800円の複勝でしたがかなり興奮しました!
自分が書いたプログラムが出した買い目が予測して当てる興奮計り知れない。。
やってみた感想
いやもうめっちゃ適当に書いたプログラムなのになんか当たってしまって、今後頑張っていくモチベーションになりました。すごいわ機械学習!すごいわランダムツリー!
後日談
この記事を書いている最中に気づいてしまったことがあります。賢明なみなさんは既にお気づきでしょうか。。。
ここ。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.8, random_state=0)
model_tree = RandomForestClassifier(bootstrap=True, n_estimators=10, criterion='gini', max_depth=None, random_state=1)
model_tree.fit(X_train_std, y_train)
ここ。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.8, random_state=0)
ここ。
test_size=0.8
なんとテストデータと訓練データのサイズを勘違いしていて、訓練データを全体データのうちの2割分しか使っていなかったのです!!(7割くらいを訓練データに利用するのがセオリーらしい)
そして正しく以下のようにモデルを再作成した結果
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
model_tree = RandomForestClassifier(bootstrap=True, n_estimators=10, criterion='gini', max_depth=None, random_state=1)
model_tree.fit(X_train_std, y_train)
[0 0 0 0 0 0 0 0 1 0 0 0 0 0 1 0]
1番人気9番のセリユーズも3着以内に入ると予測しました。結果、この馬は7着でした。
また、特徴量の重要度を可視化したものは以下です。

単勝オッズを一番重要な特徴量、その次には前走の単勝オッズを見ているのでこのプログラムは超競馬初心者であることがわかりました。そして今回の的中もまったく偶然だったということがわかりました。
AIにもビギナーズラックってあるんですね!