導入
ほんの3ヶ月ほど前に機械学習を勉強しデータコンペに参加していました。しばらく機械学習は触れていませんでしたが、大学の学園祭が終わり、サークル活動がひと段落したのでJリーグの観客動員数予測のデータコンペを修正し、より良い評価にしようと思いました。(以前のものはこちら)機械学習において予測しようとしている値が正規分布に従ったほうが精度がよくなるということが知られているので、目的変数を正規化することを考えました。
目的変数の分布
まず、本記事を書く上で利用したデータの分布を下記に挙げます。
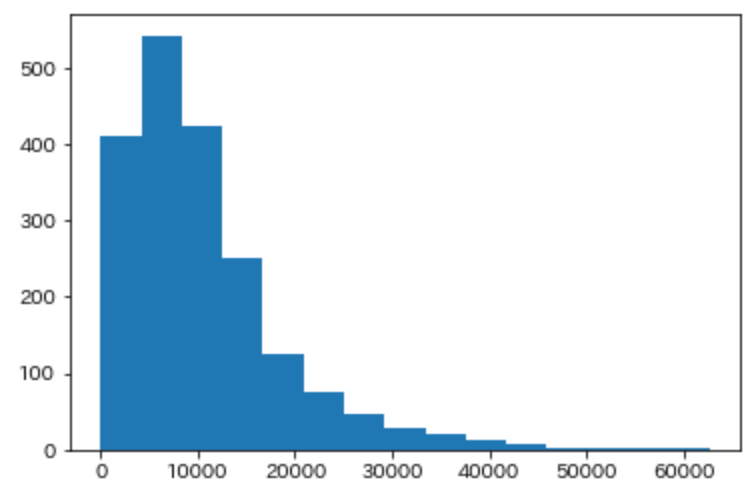
明らかに正規分布とは言い難いですね。これを正規分布に近づけていこうと思います。
import文
下記の通りです。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import scipy.stats as stats
import pylab
対数変換
目的変数の分布が線形回帰が仮定している正規分布ではないので、目的変数を対数変換し、正規分布ライクな形に整形し直し、線形回帰を下記のコードで実施しました。
## yは目的変数
## trainデータはdf_trainにDataFrame型で格納
y = df_train['y'].values
df_train['logy'] = np.log(y)
すると
RuntimeWarning: divide by zero encountered in log
という警告が出てしまいました。
logの計算ができないことで出るWarningということで元データを確認してみると、1569番目のデータの目的変数に0が含まれていることが分かりました。そのデータを例外として削除することにしました。
0を1回対数変換すると-infという文字が格納され、2回logをとるとnullが格納されることがわかったので、下記のコードで処理を行いました。
logy = df_train['logy'].values
df_train['loglogy'] = np.log(logy)
df_train=df_train.dropna(subset=['loglogy'])
結果として下図のようになり、正規分布に近づけることができたと考えられるが、QQプロットとシャピロウィルク検定を用いて再確認しようと思いました。

QQプロット
QQプロットは、X軸上に観測した累積パーセント、Y軸上に期待累積パーセントを持つグラフで、一直線上になっていれば正規分布になっていることがわかることが知られています。コードは下記のように書けばいいです。
stats.probplot(df_train['y'], dist="norm", plot=pylab)
plt.show()
この結果、正規化前のデータは下図のようになり、
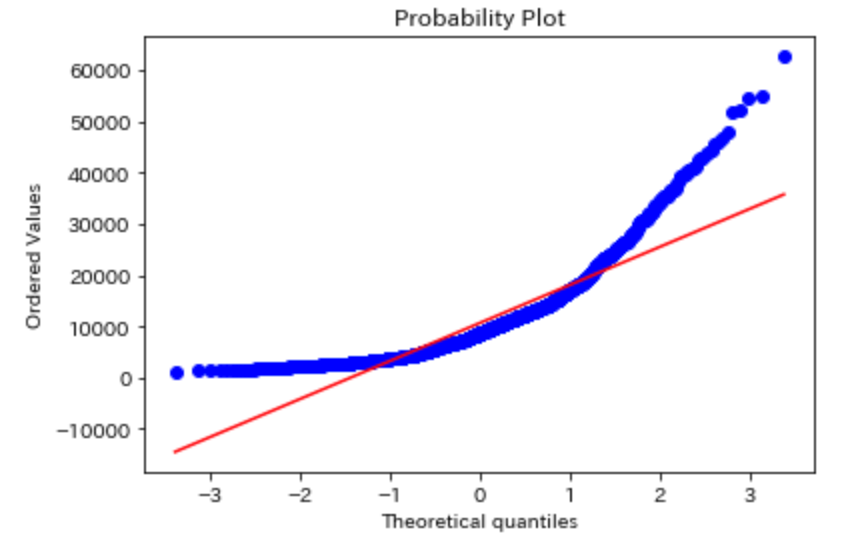
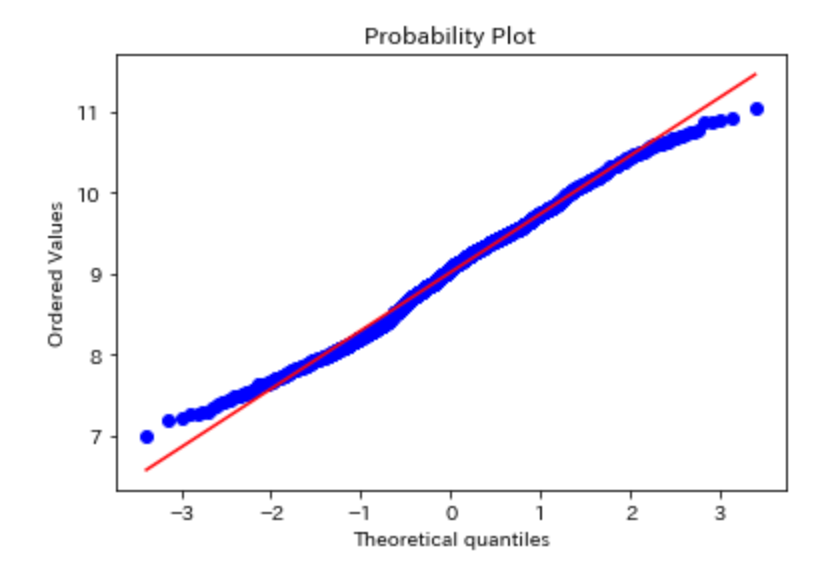
正規化後のデータは下図のようになりました。正規分布に近づいていることは明白です。
シャピロウィルク検定
b = stats.shapiro(df_train['y'])
print("対数変換前: ")
print(b)
print("")
a = stats.shapiro(df_train['logy'])
print("対数変換後: ")
print(a)
対数変換前:
(0.8354302644729614, 6.124234808485181e-41)
対数変換後:
(0.9928132891654968, 3.526571745737783e-08)
0.05以下であるため、正確な正規分布にならないが、対数変換により正規分布には近づいていることが分かります。
最後に
logにした後の値を教師データにしているので、モデルが吐き出した値に対してexpを施す必要があります。必ず忘れないようにしましょう。この対数変換を行った結果、Scoreが3,356.78983点→3,268.64733点になりました。100点近く縮める事ができました。現在59位/580位です。もっと点数伸ばしていけるように頑張ります。