概要
ChatGPTのAPIを利用時に
logprobs と top_logprobsのオプション設定ができる.
これについて解説・実験をしてみる.
前提
- ChatGPTをAPI経由で使用したことがある人
- WebAPIをJSONで扱っている.
- 以下の記事を読んで,なんとなくの機能を理解している人.
API使用時の注意点
APIを公開しているのは公式だけではない,AzureでもChatGPTのモデルを使用して一般利用できるようにしてくれている.背景にはMicrosoftとOpenAIの連携があるのだが,それはまた別のお話.
今回,ChatGPTのAPIをAzure上のもので使用しようとしたら,エラーが出たため,理由を探っていた.
ChatGPTの公式とAzure OpenAPIではオプションの付け方が異なっている.
-
ChatGPT公式サイト : logbropsとtop_logprobsが分けられている.
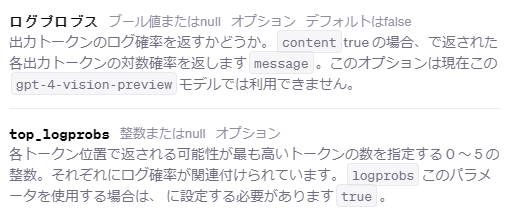
-
AzureOpenAI : logbropsオプション1つで完結している.

こちとら公式のフォーマットで型定義してしまったんや!
どないしてくれんねん.
まあーそれはいいとして,問題はAzureOpenAI ではgpt-35-turboモデルが使用できない.
現在AzureOpenAIの自分が使用できるモデルが上記だけなので,検証できない.(gpt4.0のインスタンスを立ててないだけで仕様で使えないわけではない.)
したがって,ChatGPT APIを用いて検証してみる.
検証1 : ログを実際に確認してみる.
以下のリクエストを送った.
{
"model":"gpt-3.5-turbo",
"messages":[
{"role":"system","content":"20文字程度で答えます."},
{"role":"user","content":"こんにちは,ChatGPT API,これからよろしくお願いします."}
],
"max_tokens":30,
"seed":27,
"logprobs":true,
"top_logprobs":3
}
以下のレスポンスが届いた.(見やすいように修正済)
レスポンスの文字列部分
{ "prompt_tokens": 40, "completion_tokens": 12, "total_tokens": 52 }
// ~~ 中略
{ "role": "assistant", "content": "こんにちは、よろしくお願いします。" }
レスポンスの詳細部分
"content":[
{
"token": "こんにちは",
"logprob":-0.37580183,
"bytes": [227,129,147,227,130,147,227,129,171,227,129,161,227,129,175],
"top_logprobs":[
{
"token": "こんにちは",
"logprob":-0.37580183,
"bytes": [227,129,147,227,130,147,227,129,171,227,129,161,227,129,175],
},
{
"token": "は",
"logprob":-1.3750083,
"bytes": [227, 129, 175],
},
{
"token": "よ",
"logprob":-3.1182888,
"bytes": [227, 130, 136],
}
]
},
{
"token": "、",
"logprob":-1.5497832,
"bytes": [227,128,129],
"top_logprobs":[
{
"token": "!",
"logprob":-1.1965842,
"bytes": [239, 188, 129],
},
{
"token": ",",
"logprob":-1.3137641,
"bytes": [44],
},
{
"token": "、",
"logprob":-1.5497832,
"bytes": [227, 128, 129],
}
]
},
//以下,次の単語以降は省略
]
さて,これの見方
1トークン目 : こんにちは
-
token: 1単語という解釈でいいです.
回答の初めは,こんにちは,は,よが選択候補にあがりました. -
logprob: 各tokenが出現する確率です.
一番初めの単語こんにちはが-0.3758..(約68.7%)と一番高い出現確率でした.
確率の詳細は,参考資料(確率とlogprobの関係性)をご確認ください. -
bytes: 単語をUTF-8でエンコードしてあるbyte文字列です.
tokenの文字列と意味は同じなので説明は省略します.
top_logprobを3に設定したため,候補を3つ出してくれました.
この数値を変動させることで,どのような候補が上がってくるか確認できます.
2トークン目 : 、
2トークン目の候補は以下となります.
| トークン | logprob | 確率 | 備考 |
|---|---|---|---|
| ! | -1.1965842 | 30.22248% | |
| , | -1.3137641 | 26.88063% | |
| 、 | -1.5497832 | 21.229399% | 選ばれたトークン |
注目するべきポイントは,上位の! ,を差し置いて、が選ばれていることである.
とはいえ30%も20%も当たるときは当たる.くらいの感覚かもしれない.
参考資料(確率とlogprobの関係性)
logprobはその単語が出現する確率を対数で取ったものになります.
なんで対数で取るかというと,そっちの方が計算が楽だからです.(雑説明)
ここでは,確率を以下のように定義します.(ChatGPTに聞いてみました.)
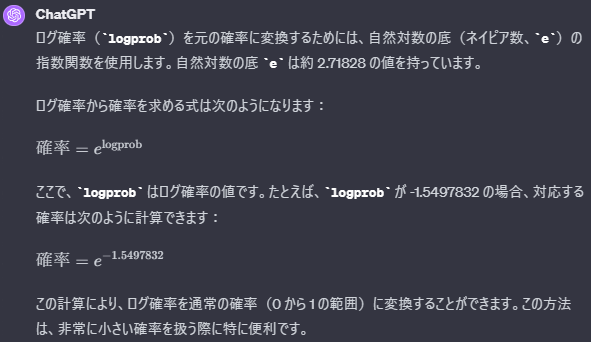
よくわからないので,実際の数値と対応表を作ってみました.
確率は,1が100%を表します.つまり,0.2の場合20%です.
| logprobの値 | 確率(e^logprob) | 備考 |
|---|---|---|
| 1 | 2.718... | 確率が1を超えてしまうためあり得ない数値 |
| 0.1 | 1.105... | 確率が1を超えてしまうためあり得ない数値 |
| 0 | 1 | 0乗すると100%になる.(おそらく滅多にない) |
| -0.1 | 0.905... | およそ90% |
| -0.2 | 0.819... | およそ82% |
| -0.3 | 0.741... | およそ74% |
| -0.4 | 0.670... | およそ67% |
| -0.5 | 0.607... | およそ61% |
| -1.0 | 0.368... | およそ37% |
| -2.3 | 0.1003... | およそ10% |
| -3.0 | 0.0498... | およそ5% |
| -5.0 | 0.0067... | およそ0.7% |
| -10.0 | 10^5*4.54... | およそ0.004% |
小さい数値編
| logprobの値 | 確率(e^logprob) | 備考 |
|---|---|---|
| -1 | 0.368... | およそ37% |
| -0.1 | 0.905... | およそ90% |
| -0.01 | 0.990... | およそ99% |
| -0.001 | 0.999... | およそ99.9% |
| -0.0001 | 0.[9が4つ]... | およそ99.99% |
| -10^(-5) | 0.[9が5つ]... | およそ99.99..% |
| -10^(-6) | 0.[9が6つ]... | 以降大体同じ |
終わりに
現状検証したいことはし終えたので,別のオプションの検証を行う.
例えば,top_pを設定したときの挙動確認や,frequency_penaltyを設定したときの次文字出現確率への影響などを調べたい.
何か実験してほしい内容があればコメントください.
ご協力よろしくお願いします!