はじめに
誰?
技術開発部のDataScience TUで時系列データの異常検知とかをやってます。社会人2年目、趣味はスポーツ(特にテニス)です。
今回の内容
kaggleのデータセットにある男子プロテニスの試合結果から、Eloレーティングというレーティング手法を使って選手の強さを定量的に評価してみます. 使用言語はRです。
(内容としては、先週JapanRというRユーザーのイベントでLTしたものの解説となっています。LTの準備でQiitaの記事書くことを忘れてこの内容になったことは秘密...)
Eloレーティング
1対1で勝敗が決する競技で広く用いられるレーティング手法です。
国際チェス連盟等で公式に採用されています。(参考)
レーティング値の定義
レーティング値としては以下の2点を満たすように定義されています。
- レーティングが同じもの同士の対戦の場合、お互いの勝率は50%
- レーティングの差が大きくなるほど、レーティングが高い方からみて勝率が100%に近づく
例えば、レーティング$R_A$のAさんとレーティング$R_B$のBさんの対決の場合、Aさんの勝率$E_A$は以下の式で計算されます。
E_A=\frac{1}{1 + 10^{(R_B-R_A)/400}}
数式だとわかりづらいのでグラフを描いてみます(Rのggplot2というパッケージを使ってみます)
library(ggplot2)
ggplot(data=data.frame(X=c(-800,800)), aes(x=X)) +
stat_function(fun=function(x) 1/(1+10^(-x/400))) +
scale_x_continuous(breaks=seq(-800,800,by=200)) +
xlab("AさんとBさんのレーティング差") +
ylab("Aさんの勝率[%]")
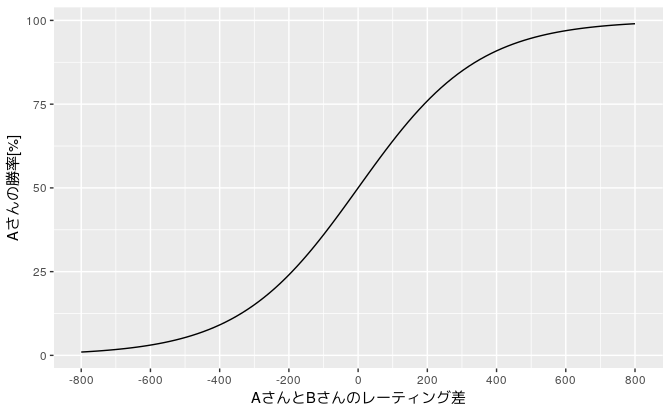
このように、AさんのレーティングがBさんと比較して大きくなるほどAさんの期待される勝率は100%に近づいていきます。
対戦後のレーティング値
次に、どのようにレーティングが変化するかについてです。今回はレーティング2000のAさんとレーティング1800のBさんの対戦を考えます。Aさんの勝率は先ほどの式より約76%と求められます。
ここで、
1)Aが勝った場合
Aのレーティングが $(1-0.76)\times27$ 増える(27は任意定数)
Bのレーティングが $(1-0.76)\times27$ 減る
2)Aが負けた場合
Aのレーティングが $(1-0.24)\times27$ 減る
Bのレーティングが $(1-0.24)\times27$ 増える
27は任意定数で、これが大きくなると一回で変動するレーティングが大きくなります。
また、勝てばレーティングは増え、負ければレーティングは減るのですが、順当な結果の場合の変動は小さく、番狂わせの場合は大きくなります。そして、試合の前後で両者のレーティングの和は変化しません。つまり、プレイヤー数が一定の場合はレーティング値の総和が一定となります。
以上がEloレーティングについての説明です。以降では実際のデータに適用していきます。
データセットについて
今回はkaggleで公開されているこちらのデータセットを利用します。2012年から2017年途中までの男子プロテニスの試合結果(ATP250以上)がまとめられています。まず、扱いやすいように少し加工します。
library(tidiverse)
# 元データの読み込み
df <- readr::read_csv("ATP Dataset_2012-01 to 2017-07_Int_V4.csv")
# 必要なカラムに絞る&Player1/2をWinner/Loserにする
df %>%
dplyr::select(Date, Tournament, Series, Surface, Round, Winner, Player1, Player1_Rank, Player2, Player2_Rank) %>%
dplyr::mutate(Loser = ifelse(Player1 == Winner, Player2, Player1)) %>%
dplyr::mutate(Winner_Rank = ifelse(Winner == Player1, Player1_Rank, Player2_Rank)) %>%
dplyr::mutate(Loser_Rank = ifelse(Loser == Player1, Player1_Rank, Player2_Rank)) %>%
dplyr::select(-Player1, -Player2, -Player1_Rank, -Player2_Rank) -> df
# 大会のランクを少し修正
df$Series %>%
replace(which(df$Series == "Masters"), "Masters1000") %>%
replace(which(df$Series == "MastersCup"), "TourFinal") -> df$Series
加工したものはこんな感じ
> head(df)
# A tibble: 6 x 9
Date Tournament Series Surface Round Winner Loser Winner_Rank Loser_Rank
<date> <chr> <chr> <chr> <chr> <chr> <chr> <int> <int>
1 2017-01-04 BrisbaneInter… ATP250 Hard 1stRo… Thomps… YmerE. 79 160
2 2017-01-04 BrisbaneInter… ATP250 Hard 1stRo… MahutN. Rober… 39 54
3 2017-01-04 BrisbaneInter… ATP250 Hard 1stRo… Ferrer… Tomic… 21 26
4 2017-01-04 BrisbaneInter… ATP250 Hard 1stRo… Edmund… Escob… 45 141
5 2017-01-04 BrisbaneInter… ATP250 Hard 1stRo… Dimitr… Johns… 17 33
6 2017-01-05 BrisbaneInter… ATP250 Hard 1stRo… Donald… Mulle… 105 34
Date: 試合があった日にち
Tournament: 大会名
Series: 大会のランク
Surface: コートの種類
Round: 何回戦か
Winner: 勝者の名前
Loser: 敗者の名前
Winner_Rank: 勝者の世界ランク
Loser_Rank: 敗者の世界ランク
PlayerRatingsパッケージでEloレーティングを求める
データの用意もできたので、Eloレーティングを求めようと思います。今回はPlayerRatingsパッケージのelo関数を使用します。先ほど作成したデータフレームを以下のようにelo関数に渡せば結果を得られます。
library(PlayerRatings)
# elo()にはtimeを数値で渡す必要があるので変換
df$Date <- as.numeric(df$Date)
# elo関数を使う
df %>%
dplyr::select(Date, Winner, Loser) %>%
dplyr::mutate(num = 1) %>%
elo(history = TRUE) -> res
下のelo関数のhelpにあるように、データフレームは、
1)数値型の時間
2)選手名1
3)選手名2
4)試合結果(選手1が勝った場合1、選手2が勝った場合0、引き分けだと1/2、今回は全て選手1が勝ってるので1が入っている)
のカラムから成ります。
A dataframe containing four variables: (1) a numeric vector denoting the time period in which the game took place (2) a numeric or character identifier for player one (3) a numeric or character identifier for player two and (4) the result of the game expressed as a number, typically equal to one for a player one win, zero for a player two win and one half for a draw.
historyをTRUEにすることで、レーティング値を時系列で得ることができます。
また、レーティングの初期値は2200、変化の重みは27とデフォルト値を使用しています。(変更は可能)
結果の可視化
それではelo関数を使用した結果から必要な情報を取り出して可視化したいと思います。今回は適当に選んだ10選手のレーティング推移を見ていきます。
# elo()の結果からhistoryを取り出してdataframeにする
res[["history"]] %>%
tibble::as_data_frame() %>%
t() %>%
tibble::as_data_frame() -> ret
# レーティングの変化を知りたい10選手を取り出す
ret$DjokovicN. %>%
head(1577L) -> DjokovicN.
ret$FedererR. %>%
head(1577L) -> FedererR.
ret$NadalR. %>%
head(1577L) -> NadalR.
ret$MurrayA. %>%
head(1577L) -> MurrayA.
ret$WawrinkaS. %>%
head(1577L) -> WawrinkaS.
ret$NishikoriK. %>%
head(1577L) -> NishikoriK.
ret$DelPotroJ.M. %>%
head(1577L) -> DelPotroJ.M.
ret$CilicM. %>%
head(1577L) -> CilicM.
ret$ThiemD. %>%
head(1577L) -> ThiemD.
ret$ZverevA. %>%
head(1577L) -> ZverevA.
# timestampを追加
df$Date %>%
unique() %>%
sort() -> Date
# データをbind -> tibble&tidy化
elo <- cbind(Date, DjokovicN., FedererR., NadalR., MurrayA., WawrinkaS., NishikoriK., DelPotroJ.M., CilicM., ThiemD., ZverevA.) %>%
tibble::as.tibble() %>%
tidyr::gather(key = player, value = elo_score, DjokovicN., FedererR., NadalR., MurrayA., WawrinkaS., NishikoriK., DelPotroJ.M., CilicM., ThiemD., ZverevA.)
# Date型へ変換
elo$Date <- as.Date(elo$Date, origin = "1970-01-01")
取り出したものはこんな感じ
> head(elo)
# A tibble: 6 x 3
Date player elo_score
<date> <chr> <dbl>
1 2012-01-03 DjokovicN. 2200
2 2012-01-04 DjokovicN. 2200
3 2012-01-05 DjokovicN. 2200
4 2012-01-06 DjokovicN. 2200
5 2012-01-07 DjokovicN. 2200
6 2012-01-08 DjokovicN. 2200
10選手のレーティング推移
こいつをggplot2を使って可視化します
elo %>%
ggplot(aes(x = Date, y = elo_score, colour = player)) +
geom_line() -> p
plot(p)

2012年1月1日の時点では全員レーティング値2200からのスタートです。大体1年程度で安定しているような気がします。そして、ジョコビッチの強さが際立ってますね。
錦織選手にハイライト
次に、レーティングが安定しだした2013年以降のデータで錦織選手にハイライトして可視化してみます。
library(gghighlight)
elo %>%
dplyr::filter(Date >= as.Date("2013-01-01")) %>%
ggplot(aes(x = Date, y = elo_score, colour = player)) +
geom_line() +
gghighlight(player == "NishikoriK.") -> p
plot(p)

こうして見ると、2014年に大きくレーティングを上げていることがわかりますね。この年の9月に全米オープンで準優勝しているので、そこで大きく上げているのはもちろんなのですが、シーズン序盤でも好調だったこともわかります。
感想
- 今回は普段お仕事で使っているR×趣味のテニスで記事を書きました。やはり、自分の興味のあるドメインのデータは分析してて楽しいです。
- 自分のやったことを文章にすることはあまりやらないので、記事を書くのは思いのほか大変でした。スライドでの発表だと口頭でカバーできるのですが、文章だとそれができないところが難しいです。
- kaggleはコンペが注目されがちですが、面白いデータセットがたくさんあります。今回は自分が興味のあるテニスのデータセットを用いましたが、他にも色々な種類のデータがあるので興味のある方は是非!