目標
サーバーレス技術やマイクロサービスが台頭している昨今、DBをサービスごとに分けるケースが多くなってきています。
本記事では、RDBとDynamoDBの両方を活用しているあなたが、分析レポートを作成するケースを想定します。
AWSを使ってETLし、両DBのデータをAthenaによりクエリするサンプルを作成していきます。
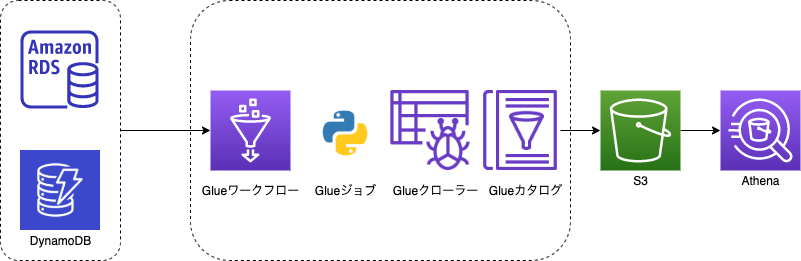
構成図
データはRDSとDynamoDBに存在することが前提となります。
Glueの機能のみでS3へparquet化したデータをETLします。
AthenaでRDSのデータとDynamoDBのデータをクエリでJOINします。
Glueの作成
それではAWSリソースをTerraformで作成するサンプルをみてみましょう。
ジョブの作成
共通
Glue用のIAMロールを作成します。
Glue、S3、DynamoDBのアクセス権限を与えておきます。
resource "aws_iam_role" "glue_role" {
name = "AWSGlueServiceRole-Sample"
assume_role_policy = data.aws_iam_policy_document.glue_assume_role.json
}
data "aws_iam_policy_document" "glue_assume_role" {
statement {
actions = ["sts:AssumeRole"]
principals {
identifiers = ["glue.amazonaws.com"]
type = "Service"
}
}
}
resource "aws_iam_role_policy_attachment" "glue_policy-1" {
policy_arn = "arn:aws:iam::aws:policy/service-role/AWSGlueServiceRole"
role = aws_iam_role.glue_role.name
}
resource "aws_iam_role_policy_attachment" "glue_policy-2" {
policy_arn = "arn:aws:iam::aws:policy/AmazonS3FullAccess"
role = aws_iam_role.glue_role.name
}
resource "aws_iam_role_policy_attachment" "glue_policy-3" {
policy_arn = "arn:aws:iam::aws:policy/AmazonDynamoDBReadOnlyAccess"
role = aws_iam_role.glue_role.name
}
続いてS3バケットです。
こちらのバケットにDBのデータを格納し、クローリングしてAthena検索できるようにします。
resource "aws_s3_bucket" "results" {
bucket = "hogehoge-XXX"
acl = "private"
}
output "data-logs-bucket-name" {
value = aws_s3_bucket.results.bucket
}
MySQL
続いてジョブの作成です。
ジョブはPython(Spark)で作成します。
aws-glue-scripts-${var.aws_account_id}-ap-northeast-1/にPythonファイルを配置することとします。
variable "aws_account_id" {}
resource "aws_glue_job" "mysql_job" {
name = "mysql_job"
role_arn = aws_iam_role.glue_role.arn
command {
script_location = "s3://aws-glue-scripts-${var.aws_account_id}-ap-northeast-1/mysql_job.py"
python_version = 3
}
connections = ["mysql_job"]
glue_version = "2.0"
number_of_workers = 10
worker_type = "G.1X"
default_arguments = {
"--bucket" = aws_s3_bucket.results.bucket
"--continuous-log-logGroup" = "/aws-glue/jobs/output"
"--enable-continuous-cloudwatch-log" = "true"
"--enable-continuous-log-filter" = "true"
"--enable-metrics" = ""
"--job-language" = "python"
"--job-bookmark-option" = "job-bookmark-disable"
"--TempDir" = "s3://aws-glue-temporary-${var.aws_account_id}-ap-northeast-1/"
}
}
以下に注目してください。
DBへの接続は別途AWSコンソールより行なうこととしています。
DBのパスワードなどをTerraform上に記録することを防ぐための対応です。
(SecretsManagerの活用や、ジョブの引数などで工夫しても可能です)
connections = ["mysql_job"]
Pythonのジョブは以下とします。
JDBC接続を確立し、1テーブルごとにS3へparquet化しています。
こちらのファイルはaws-glue-scripts-${var.aws_account_id}-ap-northeast-1/mysql_job.pyに配置しましょう。
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
arg_keys = ['JOB_NAME', 'bucket']
args = getResolvedOptions(sys.argv, arg_keys)
(job_name, bucket) = [args[k] for k in arg_keys]
# 以下の接続情報は直接入力やジョブの引数、もしくはSecretsManagerやParameterStore等の活用で指定する
db_host = "" # Todo
db_user = "" # Todo
db_password = "" # Todo
db_schema = "" # Todo
db_port = "" # Todo
jdbc_url = "jdbc:mysql://" + db_host + ":" + db_port + "/" + db_schema
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
target_tables = [
'users',
'shops',
]
for table_name in target_tables:
data_path = "s3://" + bucket + "/" + table_name
ds = glueContext.create_dynamic_frame_from_options('mysql', connection_options={
"url": jdbc_url, "user": db_user, "password": db_password, "dbtable": table_name
})
glueContext.write_dynamic_frame.from_options(
frame=ds, connection_type="s3",
connection_options={
"path": data_path
},
format="parquet"
)
DynamoDB
DynamoDBのジョブも同様に作成します。
resource "aws_glue_job" "dynamodb_job" {
name = "dynamodb_job"
role_arn = aws_iam_role.glue_role.arn
command {
script_location = "s3://aws-glue-scripts-${var.aws_account_id}-ap-northeast-1/dynamodb_job.py"
python_version = 3
}
glue_version = "2.0"
number_of_workers = 10
worker_type = "G.1X"
default_arguments = {
"--bucket" = aws_s3_bucket.results.bucket
"--continuous-log-logGroup" = "/aws-glue/jobs/output"
"--enable-continuous-cloudwatch-log" = "true"
"--enable-continuous-log-filter" = "true"
"--enable-metrics" = ""
"--job-language" = "python"
"--job-bookmark-option" = "job-bookmark-disable"
"--TempDir" = "s3://aws-glue-temporary-${var.aws_account_id}-ap-northeast-1/"
}
}
こちらのファイルはaws-glue-scripts-${var.aws_account_id}-ap-northeast-1/dynamodb_job.pyに配置しましょう。
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
arg_keys = ['JOB_NAME', 'bucket']
args = getResolvedOptions(sys.argv, arg_keys)
(job_nam, bucket) = [args[k] for k in arg_keys]
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(job_name, args)
target_tables = [
'PurchaseHistories'
]
for table_name in target_tables:
data_path = "s3://" + bucket_root + "/" + table_name
ds = glueContext.create_dynamic_frame_from_options('dynamodb', connection_options={
"dynamodb.region": "ap-northeast-1", "dynamodb.input.tableName": table_name, "dynamodb.splits": "72"
})
glueContext.write_dynamic_frame.from_options(
frame=ds, connection_type="s3",
connection_options={
"path": data_path
},
format="parquet"
)
job.commit()
クローラーの作成
続いてTerraformでGlueクローラーを作成しましょう。
ジョブによりS3に蓄積されたデータを、Glueデータカタログとして認識させるためのものです。
カタログとして認識させることでAthenaでクエリできるようになります。
resource "aws_glue_crawler" "sample_crawler" {
database_name = aws_glue_catalog_database.sample.name
name = "sample_crawler"
role = aws_iam_role.glue_role.arn
s3_target {
path = "s3://${aws_s3_bucket.results.bucket}/"
}
}
resource "aws_glue_catalog_database" "sample" {
name = "sample"
}
ワークフローの作成
続いてGlueワークフローを定義します。
ジョブ→クローラーと実行するようにスケジューリングを組むことが可能です。
毎日深夜01:00(JST)に実行するように定義してみましょう。
resource "aws_glue_workflow" "sample_workflow" {
name = "sample_workflow"
}
resource "aws_glue_trigger" "trigger" {
name = "sample_workflow_start"
schedule = "cron(0 16 * * ? *)" // UTC
type = "SCHEDULED"
workflow_name = aws_glue_workflow.sample_workflow.name
actions {
job_name = aws_glue_job.mysql_job.name
}
actions {
job_name = aws_glue_job.dynamodb_job.name
}
}
resource "aws_glue_trigger" "job_complete_trigger-0" {
name = "sample_workflow_job_complete"
type = "CONDITIONAL"
workflow_name = aws_glue_workflow.sample_workflow.name
actions {
crawler_name = aws_glue_crawler.sample_crawler.name
}
predicate {
conditions {
job_name = aws_glue_job.mysql_job.name
state = "SUCCEEDED"
}
conditions {
job_name = aws_glue_job.dynamodb_job.name
state = "SUCCEEDED"
}
}
}
以下の内容に注目してください。
actions {
crawler_name = aws_glue_crawler.sample_crawler.name
}
predicate {
conditions {
job_name = aws_glue_job.mysql_job.name
state = "SUCCEEDED"
}
conditions {
job_name = aws_glue_job.dynamodb_job.name
state = "SUCCEEDED"
}
}
こちらの記述は、mysql_jobとdynamodb_jobが完了した後、sample_crawlerを実行するという流れになっています。
Glueワークフローを使用することで、簡易的にETLの流れを定義することができました。
Athenaによるクエリ
クローラーでカタログを作成できれば、Athenaで検索することができるようになります。
MySQLのデータとDynamoDBのデータをJOINできることを確認しましょう。