DatabricksでSynapseMLのLightGBMを使う
Synapse MLはmicrosoftが開発した分散処理に対応した機械学習ライブラリ。LightGBMも実装されている。いつの間にかmlflowにも対応していたので、databricksにインストールしてLightGBMをmlflowでトラッキングしてみる。
インストール
インストールはクラスターの設定で実施する
- computingメニューを開き、インストールしたいクラスターをクリック
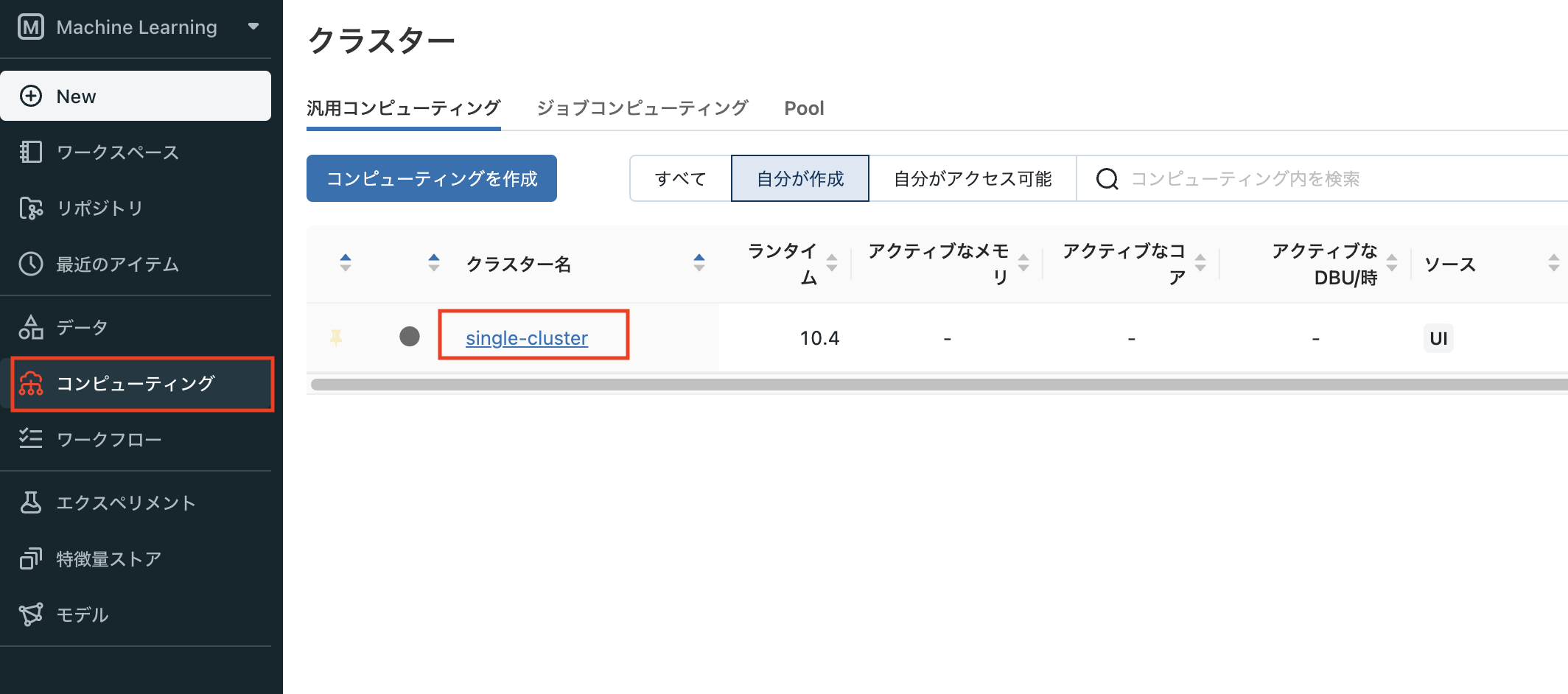
なお、2023/2/2現在では、SynapseML v0.10.2をDatabricks Runtime 11.4 LTS MLにインストールしようとすると、エラーになりインストールできない。インストール対象のクラスターがDatabricks Runtime 10.4 LTS MLだとインストール出来る。
2023/4/4追記:
どうやら座標をcom.microsoft.azure:synapseml_2.12:0.11.0-32-6085190e-SNAPSHOTにすると、Databricks Rutime 11.4 LTS MLにインストール出来るようになった模様。
ただしリリース公開されていないリポジトリなので、リポジトリ欄にhttps://mmlspark.azureedge.net/mavenを指定する必要がある。
-
「ライブラリ」タブをクリックし、「新規をインストール」をクリックする

-
Mavenを選択し、「座標」と「リポジトリ」に以下を入力する
- 座標:
com.microsoft.azure:synapseml_2.12:0.10.2 - リポジトリ:
https://mmlspark.azureedge.net/maven
- 座標:
2023/4/4追記:
Databricks Rutime 11.4 LTS MLの場合は、座標をcom.microsoft.azure:synapseml_2.12:0.11.0-32-6085190e-SNAPSHOTにする。
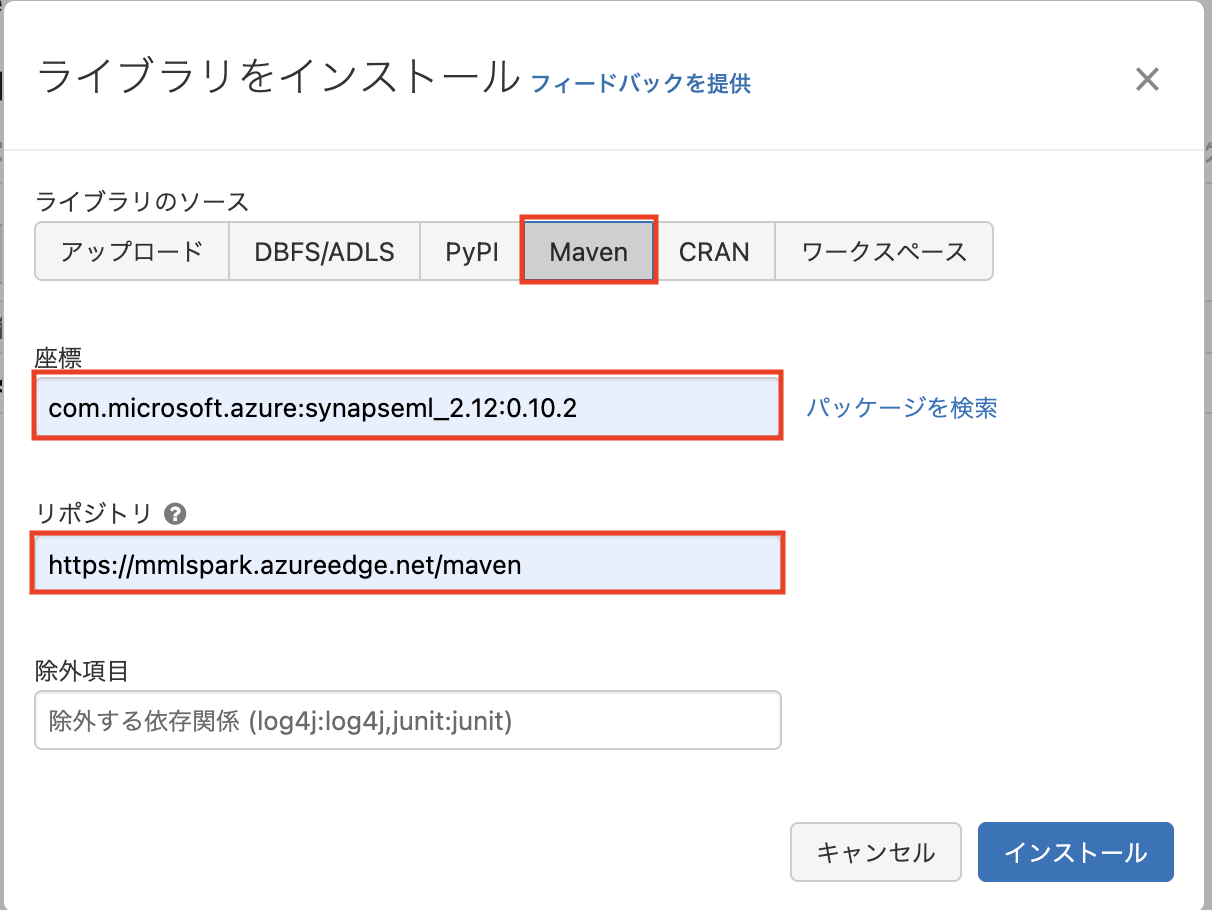
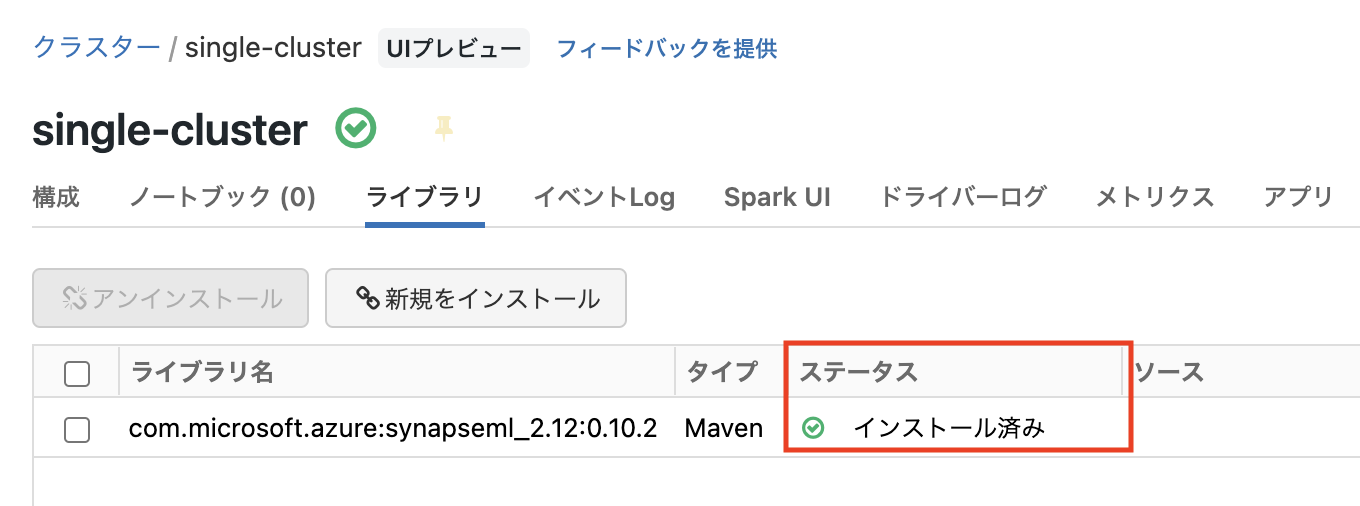
座標はSynapseMLのバージョンによって異なるので注意。「インストール」をクリックするとインストールが開始される。「ステータス」がインストール済みになるまで時間がかかる。
クラスターが作成されてもインストール済みになるまでプログラム実行が保留になる。
mlflowでSynapseMLのLightGBMをトラッキングする
ここからはdatabricks notebookでSynapseMLのLightGBMを試す。ただ実行するだけでは面白くないので、mlflowでトラッキングする。なお、SynapseMLは2022/8にmlflowに対応している。
今回はあくまで動かすだけなので、sklearnのbreast cancerで済ませる。
下準備
SynapseMLを使用する場合、ワーカーノードにもmlflowをインストールする必要があるらしいので、%pipのマジックコマンドでインストールする。インタープリタが再起動するので、少し待ちましょう。
%pip install mlflow
sklearn.datasetsからbreast cancerのデータセットを読み込む。brast cancerのデータはnumpy.ndarrayだが、直接spark DataFrameに変換する方法が思いつかなかったのでpandas DataFrame経由で変換している。
import pandas as pd
from sklearn import datasets
import mlflow
from pyspark.ml import Pipeline
from pyspark.ml.feature import VectorAssembler, StringIndexer
from synapse.ml.lightgbm import LightGBMClassifier
# データ準備
breast_cancer_data = datasets.load_breast_cancer()
breast_cancer_df = pd.DataFrame(
breast_cancer_data.data,
columns = breast_cancer_data.feature_names
)
# 変数名にスペースがあるので、アンダーバーにreplace
breast_cancer_df.columns = [col.replace(' ', '_') for col in breast_cancer_df.columns]
cols = list(breast_cancer_df.columns)
breast_cancer_df['target'] = breast_cancer_data.target
# spark DataFrameに変換
breast_cancer_sdf = spark.createDataFrame(breast_cancer_df)
今回はholdoutで実装してみる。
# train test split
train_df, test_df = (
breast_cancer_sdf
.randomSplit([0.7, 0.3], seed = 22)
)
ハイパーパラメータは適当に設定。パラメータ名がスネークケースではなくキャメルケースなところにJavaの香りを感じる。
params = {
'objective':'binary',
'numIterations': 200,
'learningRate': 0.2,
'maxDepth': 7,
'lambdaL2': 1.,
'numLeaves': 31,
'labelCol':'target',
'featuresCol': 'features'
}
SynapseMLのLightGBMはsparkMLと同じく、特徴量はベクトル型の変数である必要がある。そのためVectorAssemblerで特徴量をベクトル型に変換する。sparkML特有のクセはまた別途記事にする。
VectorAssemblerとLightGBMClassifierのpipelineを定義しているが、sklearnのpipelineと似たようなものという認識で差し支えない。
# pipeline定義
assember = VectorAssembler(
inputCols = cols,
outputCol = 'features'
)
clf = LightGBMClassifier(**params)
stages = [assember, clf]
pipeline = Pipeline(stages = stages)
mlflowでモデル構築のトラッキング
折角なのでmlflowでトラッキングしてみる。mlflow.spark.log_modelにpip_requirementsを指定しているが、これがないとエラーログを吐き出す(loggerのエラーメッセージであるため、処理自体は動く)。mlflowのlog_modelはmlflow.models.infer_pip_requirementsを経由して、modelオブジェクトをもとにpipのrequirement.txtを自動生成してくれる。しかしSynapseMLのLightGBMだと、このmlflow.models.infer_pip_requirementsが上手く依存モジュールを見つけられないことが原因と思われる。
ここでエラーになってもget_default_pip_requirementsが機能するので一応動くのだが、エラーのログメッセージが気持ち悪いので、ここではpip_requirementsを指定している。良い解決方法とは言えないので真似しないように。
# mlflowでトラッキング
with mlflow.start_run() as run:
mlflow.pyspark.ml.autolog(log_models = False)
# モデルの学習
model = pipeline.fit(train_df)
mlflow.spark.log_model(
model,
"lightgbm_pipeline",
pip_requirements= ['pyspark==3.2.1']
)
# 予測
predictions = model.transform(test_df)
なお上記のコードを実行すると
WARNING mlflow.utils: Truncated the value of the key `VectorAssembler.inputCols`.
のwarningが出力される。VectorAssembler.inputColsをmlflow上にlog_paramsする際にリストが長すぎるので、途中で文字列が切断されてlog出力されているwarning。文字列が途中で切断される以外は不具合がない。
おまけで精度評価
ここまで書いたので、精度評価まで書いておこう。
# run idを取得してlog_modelで保存したモデルの読み込み
run_id = run.info.run_id
model_path = f"runs:/{run_id}/lightgbm_pipeline"
loaded_model = mlflow.spark.load_model(model_path)
# 予測値の算出
pred_df = loaded_model.transform(test_df)
sparkMLと同様、評価は(二値分類の場合)BinaryClassificationEvaluatorを使う。
from pyspark.ml.evaluation import BinaryClassificationEvaluator
evaluator = BinaryClassificationEvaluator(
labelCol='target',
rawPredictionCol = 'prediction',
metricName = 'areaUnderROC'
)
print("AUC: ", evaluator.evaluate(pred_df))
今回はインストールと実行を試しただけだが、今後は実行速度や精度について色々試していきたいところ。