Unity Catalogに対応したクラスターに制限がある
Unity Catalogを使用したDatabricks環境だと、Unity Catalogにアクセスできるセキュリティモードが
- シングルユーザー
- ユーザー分離共有
に限定される。シングルユーザーの場合は制約はそれほどないので特に問題はない。ユーザー分離共有の場合となると、DatabricksのMLランタイムがそもそも選択できない。とは言えMLランタイムでなくとも、mlflowはpip installすれば使えるし、分散処理しないのであればsklearnやlightgbmもpip installで使えば良い。
問題はSparkMLを使いたい場合だ。シングルユーザーのクラスターは問題なくSparkMLを使えるが、ユーザー分離共有のクラスターはそもそもMLランタイムを選択できない。その状況下で無理やりSparkMLを使うとどうなるだろうか?
SparkML自体はsparkのライブラリに内包されているので、import自体は可能。しかし、いざインスタンス化しようとするとエラーになる。
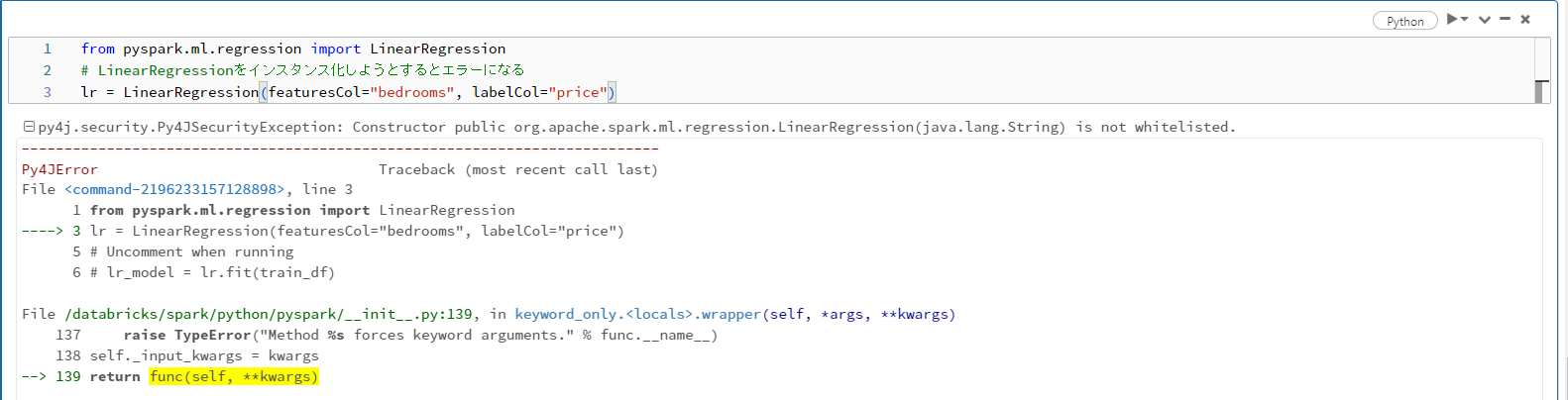
エラーログを見るとConstructor public org.apache.spark.ml.regression.LinearRegression(java.lang.String) is not whitelisted.と書いてある。これはPy4JSecurityが影響している模様。
共有モードのクラスターだとspark.databricks.pyspark.enablePy4JSecurityがtrueになり、spark.jvm.class.allowlistに追加されていない一部のクラスが使えなくなるようだ(共有モードでMLランタイムが選択できないのも、恐らくこれが理由)。
じゃあこの設定を無効化するか、spark.jvm.class.allowlistにホワイトリスト登録すればいいじゃん、と思ったがこれは不可能。
この影響で、Unity CatalogにアクセスしてSparkMLを使った機械学習の並列分散処理を行うためには、「シングルユーザー」のクラスターを使う以外に選択肢がない。
さらに厄介なのはpyspark pandas APIを使っていると、一部のメソッドの内部でsparkMLのクラスを参照してエラーになる場合がある(pyspark pandas APIのdf.corr()でエラーになった)。
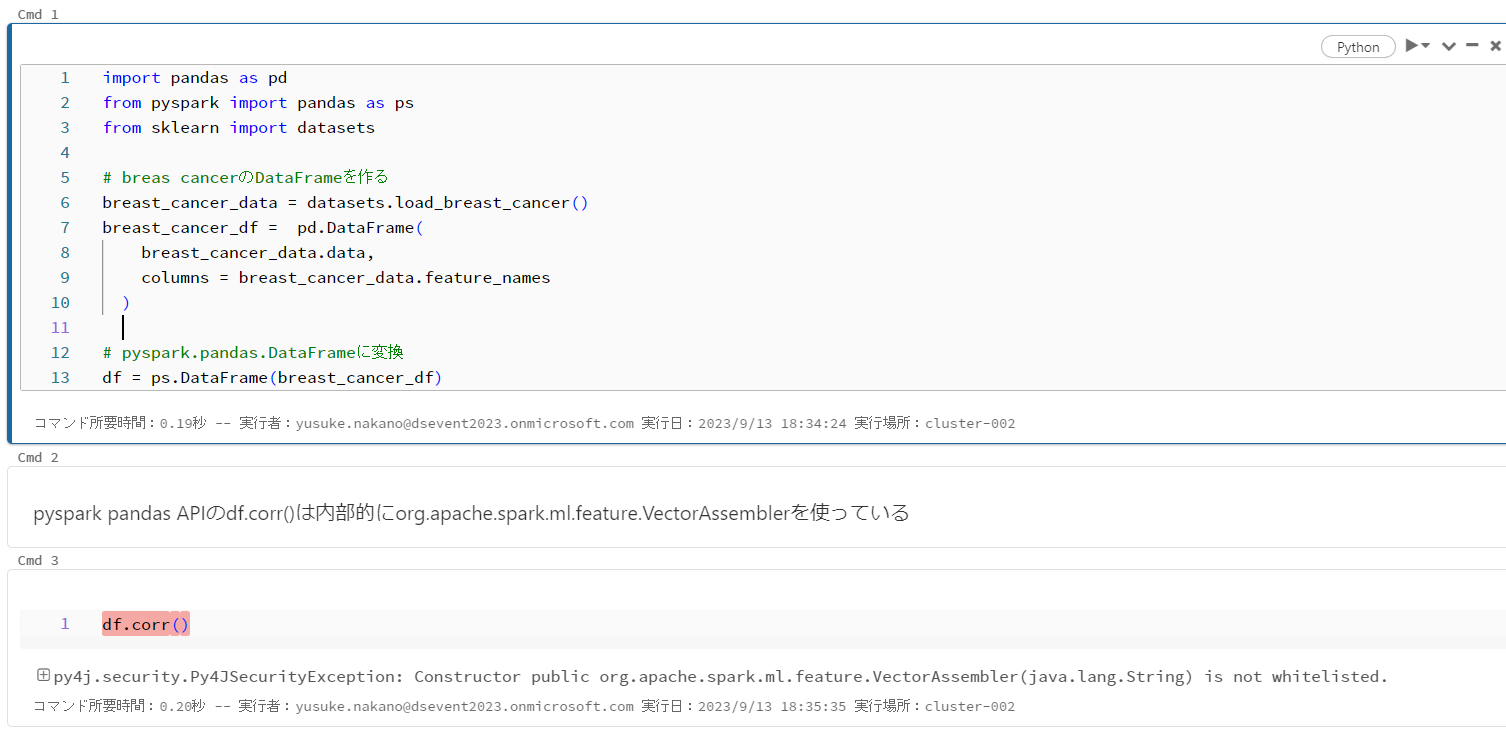
クラスターの作成権限を制限している組織は多そうなので、Unity Catalogに移行すると機械学習の並列分散処理が実質的にできなくなるケースもありそう。なのでSparkMLを使っている組織は、Unity Catalogへの移行は検討事項が増えるので注意が必要。