初めに





学習
13 〇
ストリームは400KB。動画アプリケーション。ログストリームをSQLで分析したい。
- ログデータをfirehose配信ストリームに出力。Lmabdaでデータ変換してRedshiftでクエリ
- redshitの用途がいまいち
- ログをSQSに配信。Lambdaでデータ変換。Redshiftでクエリ
- リアルタイムに処理するのに向いていない。順番性がない。
- ログをcloudwatchでS3に出力。Lambdaでデータ変換。Redshiftでクエリ
- メトリクスとして配信であればリアルタイムについていけるのだろうか
- kinesisデータ配信ストリームに出力。Lambdaで二番目のストリームにデータを配信。kinesis data analyticsでクエリ
- 正解
【初心者】Amazon Kinesis Video Streams を使ってみる(ラズパイカメラからの送信
Amazon Kinesis Data Firehose とは?
Amazon Kinesis Data Firehose は、リアルタイムのストリーミングデータを Amazon Simple Storage Service (Amazon S3)、Amazon Redshift、Amazon Elasticsearch Service (Amazon ES)、Splunk などの送信先に配信するための完全マネージド型サービスです。Kinesis Data Firehose は、Kinesis ストリーミングデータプラットフォームの一部です。他にも、Kinesis Data Streams、Kinesis ビデオストリーム、Amazon Kinesis Data Analytics があります。Kinesis Data Firehose を使用すると、アプリケーションを記述したり、リソースを管理したりする必要はありません。Kinesis Data Firehose にデータを送信するようデータプロデューサーを設定すると、指定した送信先にデータが自動的に配信されます。データを配信前に変換するように、Kinesis Data Firehose を設定することもできます。
主要なコンセプト
- Kinesis Data Firehose 配信ストリーム
- Kinesis Data Firehose の基盤となるエンティティ。Kinesis Data Firehose を使用するには、Kinesis Data Firehose 配信ストリームを作成し、それに対してデータを送信
- record
- データプロデューサーが Kinesis Data Firehose 配信ストリームに送信する、目的のデータ。レコードのサイズは最大 1000 KB です。
- データプロデューサー
- プロデューサーは Kinesis Data Firehose 配信ストリームにレコードを送信します。たとえば、配信ストリームにログデータを送信するウェブサーバーはデータプロデューサーです。Kinesis Data Firehose 配信ストリームが自動的に既存の Kinesis からデータを読み取り、送信先にロードするよう設定することもできます。
- バッファサイズおよびバッファの間隔
- Kinesis Data Firehose は特定の期間、受信するストリーミングデータを特定のサイズにバッファしてから、送信先に配信します。[Buffer Size] は MB 単位で、[Buffer Interval] は秒単位です。
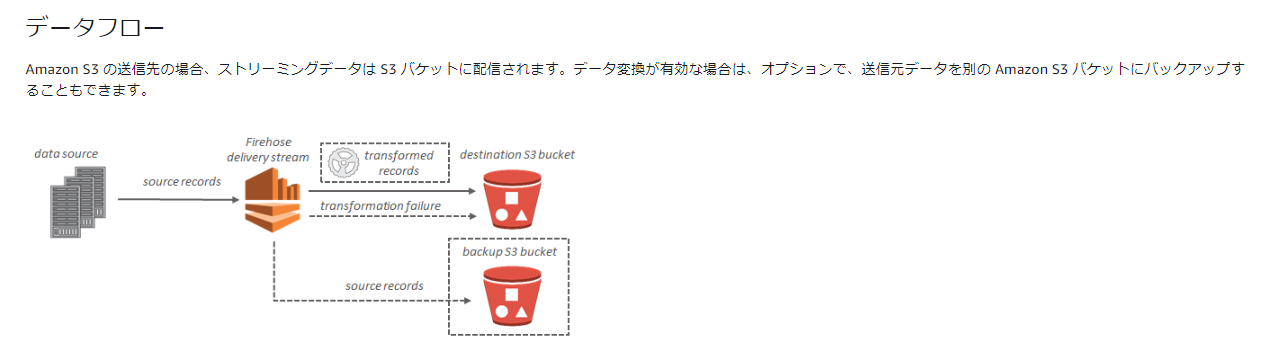
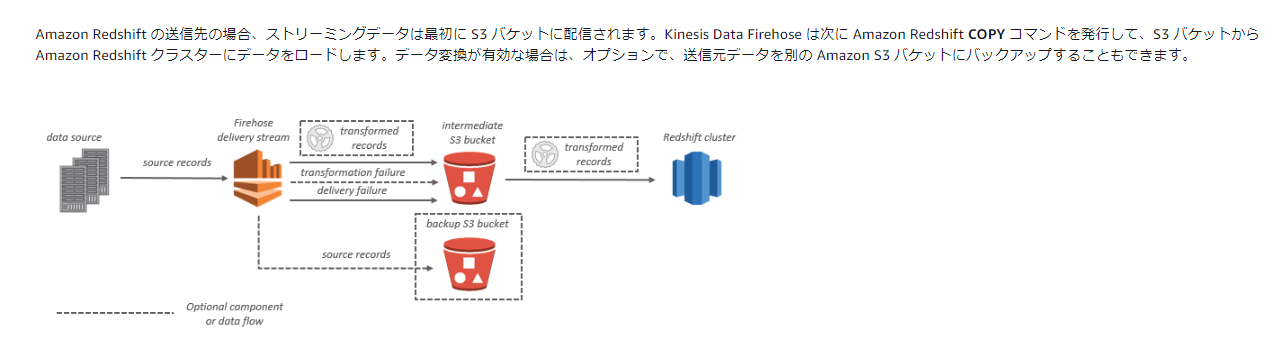
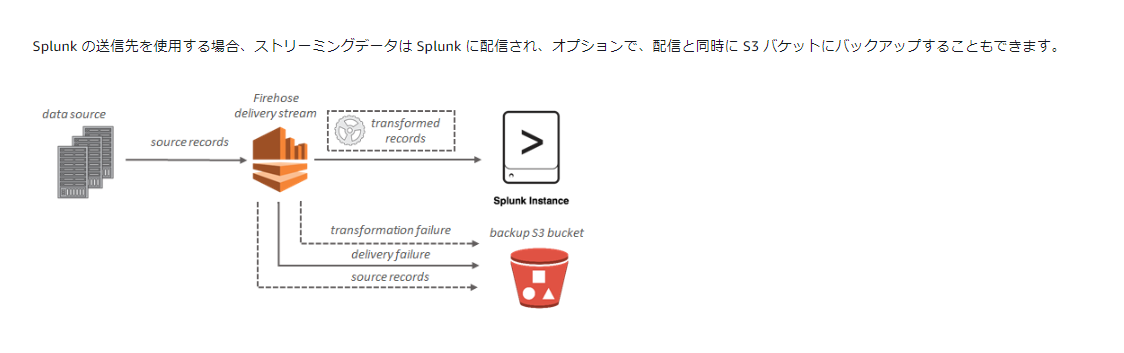
データフロー
- s3
- redsfhit
- es

- splunk
Amazon Kinesis Data Firehose 配信ストリームへのデータの送信
- Kinesis Data Streams を使用した Kinesis Data Firehose への書き込み
- Kinesis エージェントを使用した Kinesis Data Firehose への書き込み
- AWS SDK を使用した Kinesis Data Firehose への書き込み
- CloudWatch Logs を使用した Kinesis Data Firehose への書き込み
- CloudWatch イベント を使用した Kinesis Data Firehose への書き込み
- AWS IoT を使用した Kinesis Data Firehose への書き込み
Amazon Kinesis Data Streams とは?
データレコードの大量のストリームをリアルタイムで収集し、処理するには、Amazon Kinesis Data Streams を使用します。Kinesis Data Streams アプリケーションと呼ばれるデータ処理アプリケーションを作成できます。一般的な Kinesis Data Streams アプリケーションでは、データストリームのデータをデータレコードとして読み取ります。これらのアプリケーションは Kinesis Client Library を使用できます。また、Amazon EC2 インスタンスで実行できます。処理されたレコードは、ダッシュボードに送信してアラートの生成や、料金設定と広告戦略の動的変更に使用できるほか、他のさまざまな AWS のサービスにデータを送信できます。
- kinesis ファミリ
- firehose
- datastream
- videostream
- dataanalytics
プロデューサーはシャードにデータレコードを送信し、コンシューマーはシャードからデータレコードを取得します。
-
プロドゥーサー
- プロデューサーは、データレコードを Amazon Kinesis データストリームに送信します。たとえば、Kinesis data stream にログデータを送信するウェブサーバーはプロデューサーです。コンシューマーは、ストリームのデータレコードを処理します。
- ストリームにデータを送信するには、ストリームの名前、パーティションキー、ストリームに追加するデータ BLOB を指定する必要があります。パーティションキーは、データレコードが追加されるストリーム内のシャードを決定するために使用されます。
- シャード内のすべてのデータは、そのシャードを処理する同じワーカーに送信されます。使用するパーティションキーはアプリケーションのロジックによって異なります。パーティションキーの数は、通常、シャード数よりかなり大きくする必要があります。これは、データレコードを特定のシャードにマッピングする方法を決定するために、パーティションキーが使用されるからです。十分なパーティションキーがある場合、ストリーム内のシャードに均等にデータを分散することができます。
-
Kinesis Data Streams コンシューマー
- コンシューマーは、Amazon Kinesis Data Streams application とも呼ばれ、Kinesis データストリームからデータレコードを取得して処理するために構築するアプリケーション
- Amazon Simple Storage Service (Amazon S3)、Amazon Redshift、Amazon Elasticsearch Service (Amazon ES)、Splunk などのサービスに直接ストリームレコードを送信する場合は、コンシューマーアプリケーションを作成する代わりに Kinesis Data Firehose 配信ストリームを使用できます
- コンシューマーを作成する場合は、Amazon Machine Image (AMI) のいずれかに追加して、Amazon EC2 インスタンスにデプロイします。コンシューマーをスケールするには、これを Auto Scaling グループの複数の Amazon EC2 インスタンスで実行します。Auto Scaling グループを使用すると、EC2 インスタンスに障害が発生した場合に新しいインスタンスを自動的に起動するのに役立ちます。また、アプリケーションの負荷の経時変化に応じてインスタンス数を伸縮自在にスケールすることもできます。Auto Scaling グループを使用することで、一定数の EC2 インスタンスを常に実行状態にすることができます。Auto Scaling グループのスケーリングイベントをトリガーするには、CPU やメモリの使用率などのメトリクスを指定して、ストリームからのデータを処理する EC2 インスタンスの数を増減させることができます。
Amazon Kinesis Data Streams からのデータの読み取り
主に以下の三つ
- lambda
- hirehose
- analytics
14
気象予測用アプリは2000vcpuで50分かかる処理を行っている。各期初予測データサイズは10GBで分析はデータサイズセットが入ってくるまでに完了する必要がある。予測データにアクセスが集中するのは最初の一時間のみであり使用料は次第に減っていく。
最もコスパがいいのは?
- 各リージョンで1時間のスポットブロックを使用し、Amazon EC2ベースのクラスタで分析を開始する
- こっちのほうが安いので正解。また各リージョンなのでサイズにもよるがキャパシティの確保が問題
- 単一リージョンでリザーブドインスタンスを使用し、Amazon EC2ベースのクラスタで分析を開始する
- S3スタンダードにデータを格納。30日後にスタンダードIAに移行するようライフサイクルポリシーを設定
- S3スタンダードonezone IAにデータを格納。90日後にグレイサーに移行するようライフサイクルポリシーを設定
- 正解
- S3スタンダードIAにデータを格納。90日後にグレイサーに移行するようライフサイクルポリシーを設定
Amazon S3 ストレージクラス
Amazon S3 では、各ユースケース向けに幅広いストレージクラスが提供されています。クラスの種類は、S3 標準 (高頻度アクセスの汎用ストレージ用)、S3 Intelligent-Tiering (未知のアクセスパターンのデータ、またはアクセスパターンが変化するデータ用)、S3 標準 – 低頻度アクセス (S3 標準 - IA)、S3 1 ゾーン - 低頻度アクセス (S3 1 ゾーン - IA) (長期間使用するが低頻度アクセスのデータ)、Amazon S3 Glacier (S3 Glacier)、Amazon S3 Glacier Deep Archive (S3 Glacier Deep Archive) (長期アーカイブおよびデジタル保存) があります。Amazon S3 には、ライフサイクルを通じてデータを管理する機能が搭載されています。S3 ライフサイクルポリシーを設定すると、データは別のストレージクラスに自動的に移行されます。アプリケーションに変更を加える必要はありません。
- Amazon S3 標準 (S3 標準)
- Amazon S3 Intelligent-Tiering (S3 Intelligent-Tiering)
- このストレージクラスは、アクセスパターンが未知または予測不能で、長期間使用するデータで理想的
- アクセスパターンの変化に応じて、オブジェクトを 2 つのアクセス階層間で自動的に移動する
- 高頻度アクセス
- 低頻度アクセス
- S3 Intelligent-Tiering ストレージクラスを使用しても取り出し料金はかかりません。
- スタンダード使うならこっちか
- Amazon S3 標準 – 低頻度アクセス (S3 標準 – IA)
- 性能はスタンダードと同じ
- 標準より安い
- 取り出し GB あたり
- Amazon S3 1 ゾーン – 低頻度アクセス (S3 1 ゾーン – IA)
- 可用性が下がる
- S3 標準 – IA よりもコストを 20% 削減
- 取り出し GB あたり
- Amazon S3 Glacier (S3 Glacier)
- Amazon S3 Glacier Deep Archive (S3 Glacier Deep Archive)
- 1 年のうち 1 回か 2 回しかアクセスされないようなデータを対象とした長期保存やデジタル保存をサポート
- 磁気テープの代替策
- 取り出し GB あたり
15
アプリが複数AZかつAutoscaling設定されたEC2上で稼働している。データはDynamoDBに保管。アプリは各オペレーションが何回呼び出されたかをテーブルに記録し、呼び出される項目としてオペレーションIDと回数が含まれている。ログはcloudwatchlogsに格納される。ELBアクセスログに記録されたGETリクエスト件数がDynamoDBテーブルでのGET回数よりはるかに多いことが分かった。
原因は何か
- Get呼び出しが現行数を取得したら整合性のある読み込みを行う
- RCU
- WCU
- UPdateitem呼び出しが増加後の呼び出し状況を保存したら条件付き書き込みを使う
- 正解。上書きされることでカウントがずれるのではないだろうか
DynamoDB 条件式
PutItem オペレーションはキーが同じ項目を上書きします (存在する場合)。これを回避するには、条件式を使用します。これにより、問題の項目が同じキーを持っていない場合にのみ書き込みが続行されます。
Amazon DynamoDB のコアコンポーネント
-
テーブル
- 他のデータベースシステムと同様、DynamoDB はデータをテーブルに保存します。テーブルは、データのコレクションです。
- 項目
- 各テーブルにはゼロ以上の項目が含まれています。項目は、他のすべての項目間で一意に識別可能な属性のグループです。
- 属性
- 各項目は 1 つ以上の属性で構成されます。属性は、基盤となるデータ要素であり、それ以上分割する必要がないものです
-
プライマリキー
- パーティションキー
- パーティションキーという 1 つの属性で構成されたシンプルなプライマリキー。
- パーティションキーのみを含むテーブルでは、2 つの項目が同じパーティションキー値を持つことはできません。
- 複合プライマリキー
- 複合プライマリキーと呼ばれるこのキーのタイプは、2 つの属性で構成されます。
- 最初の属性はパーティションキーであり、2 番目の属性はソートキーです。
- パーティションキー
-
セカンダリインデックス
- インデックスは基本テーブルから作られる。
- DynamoDB はインデックスを自動的に維持します。基本テーブルの項目を追加、更新、または削除すると、DynamoDB はそのテーブルに属するすべてのインデックスの対応する項目を追加、更新、または削除します。
- インデックスを作成するときは、基本テーブルからインデックスにコピーまたは射影される属性を指定します。少なくとも、DynamoDB は基本テーブルからインデックスにキー属性を射影します。
- DynamoDB の各テーブルは、20 グローバルセカンダリーインデックス (デフォルトの制限) と、テーブルあたり 5 ローカルセカンダリーインデックスに制限されています
- テーブルで 1 つ以上のセカンダリインデックスを作成できます。
- セカンダリインデックス では、プライマリキーに対するクエリに加えて、代替キーを使用して、テーブル内のデータのクエリを実行します
- Global secondary index
- テーブルと異なるパーティションキーとソートキーを持つインデックス
- 最初からある項目では対応できない属性の抽出を行うための項目
- テーブルと異なるパーティションキーとソートキーを持つインデックス
- ローカルセカンダリインデックス
- テーブルと同じパーティションキーと、異なるソートキーを持つインデックス。
- 違う属性でソート検索したい時用
- テーブルと同じパーティションキーと、異なるソートキーを持つインデックス。
- Global secondary index
DynamoDBはまた明日にします。