これからデータサイエンスの仕事を始めるんですが,それに当たって統計の知識を整理しています.その中で効果量という概念についてよく分かっていなかったので調べたものをまとめてみることにしました.
まだまだ経験が浅いですし,統計の専門家でもないので間違えている可能性は大いにあります.その際はツッコミ頂ければ嬉しいです.
効果量とは?
- ある現象に対する効果の大きさを表す指標のこと.値の絶対値が大きいほど効果の大きさも大きい
- 効果量の例として,2つの母集団の平均値の差や,相関係数がある
以下にもう少し詳しい解説を書いていきます.
まずは,仮説検定の復習
効果量の説明の前に,仮説検定のやり方について復習しましょう (別に効果量は仮説検定に限った話ではなく区間推定でも定義できる概念なのですが,自分が説明しやすいからそうします).
まずp値 (p-value) についてです.p-valueとは,帰無仮説 (null hypothesis) が真,かつ正しい統計モデルを使用していると仮定したとき,(観測データ+それよりも極端なデータ)1が得られる確率のことです.このp-valueが先に決めておいた閾値である有意水準 (significance level) $\alpha$ よりも小さい値である場合,「帰無仮説が真である」という仮定が偽であったと結論付け,背理法に基づいて対立仮説 (alternative hypothesis) を採択する,というのが仮説検定のやり方です (ここでも統計モデルが正しい,ということは前提になっています.元々正規分布に従わないデータを無理に正規分布に当てはめて仮説検定しても出た結論に意味は薄いはずです).
仮説検定の一例を見てみましょう.ちなみに,下の例の計算はこちらのgistに上げてあります (本当にテストして実験したのではなく,乱数を発生させて作ったものです).
ある高校で,テストの成績を上げるために補習を行おうと決めたとします.その補習が効果があるのか,ないのかを判断するために,補習を行う生徒と行わない生徒をランダム (恣意的な抽出をしない) に100人ずつ抽出して,それぞれのテストの点数を見て補習の効果があったかどうかを見る実験を考えてみましょう.テストの点数は正規分布に従うと仮定し,補習を行わなかった生徒の母集団のテストの平均値を$\mu_0$,補習を行った生徒の母集団のテストの平均値を$\mu_1$とし,帰無仮説を$H_0: \mu_0=\mu_1$,対立仮説を$H_1: \mu_0 < \mu_1$,有意水準を$\alpha=.05$として実験をしてみます (今回は検出力は考慮していません.サンプルサイズも適当に決めています2).
以下に実験結果として,各生徒のテストの点数と分布の図を載せます.
| 補習を受けてない生徒のテストの点数 | 補習を受けた生徒のテストの点数 | |
|---|---|---|
| 0 | 49 | 45 |
| 1 | 52 | 54 |
| 2 | 44 | 47 |
| 3 | 42 | 53 |
| 4 | 58 | 56 |
| ... | ... | ... |
| 95 | 41 | 59 |
| 96 | 56 | 52 |
| 97 | 47 | 51 |
| 98 | 50 | 55 |
| 99 | 50 | 51 |
100 rows × 2 columns
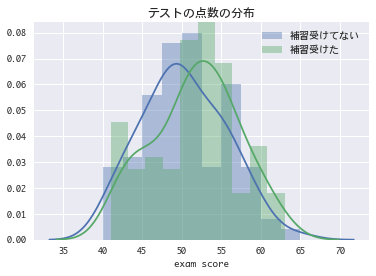
この表から補習を行わなかったグループと行ったグループのテストの平均値を計算すると,それぞれ$50.23$と$51.72$という結果になりました.補習を受けた方が点数が高いように見えますが,これは補習の影響なのでしょうか?それともたまたま補習を受けた生徒のヤマが当たっただけ?
上の疑問について考えるために,今ある手元のデータ (標本, sample) の平均値の差が母集団 (population) でも差があるのかを見てみましょう.つまり「誤差ではなく,何らかが原因でデータ間に差があったか?」を見るわけです.2つの母集団の平均値に差があるかを見るときには,仮説検定という統計手法がよく採られます.これは,「平均値に差がない」という仮定を置き,その条件のもとでp-valueを計算,それが有意水準よりも小さければ「平均値に差がない」とは言えないと判断し,背理法の要領で「平均値に差がある」と判断をします.これで誤差ではなく,何らかが原因でデータ間に差があると結論付けられました.ここで実験環境を思い出すと,生徒を恣意的な選択をせずに補習する/しないをランダムに決めているので,補習を行ったかどうか以外の原因が入り込む余地がないはずです.そのため,2つのデータ間の平均値の差の原因は「生徒が補習を受講した」ことであるといえる,よって補習はテストの点数を上げる効果があった,ということができます.
さて,ここでは有意水準を$\alpha=.05$としていました.p-valueを計算してみましょう.(サンプルのコードを一部抜粋)
from scipy import stats
# supplementary_lesson_scores: 補習受けた生徒のテストの点数の配列
# non_supplementary_lesson_scores: 補習受けてない生徒のテストの点数の配列
stat_val, p_val = stats.ttest_ind(supplementary_lesson_scores, non_supplementary_lesson_scores, equal_var=False)
# 得られたp_valは両側検定の値なので,右片側検定の結果に直す必要がある
p_val /= 2
print('stat_val: {:.3f}, p_val: {:.3f}'.format(stat_val, p_val))
if p_val < 0.05 and stat_val > 0:
print('統計的に有意です')
else:
print('統計的に有意とは言えません')
# Output: stat_val: 1.960, p_val: 0.026
# 統計的に有意です
p-valueを計算すると,$.026$という結果になりました3.有意水準$\alpha$が$.05$のもとでは有意である,つまり補習は効果があったと言えそうです.補習を行った先生,受けた生徒の労力は報われたと言えそうですね.
...でも,ちょっと待ってください.補習には効果があったことはわかりましたが,その効果ってどの程度なのかは全くわからないですよね?
効果量について
前の節で補習には効果があったことはわかりましたが,じゃあどの程度の効果があったのでしょうか?
頑張って補習に時間を割いて効果があったのはいいけど,その効果はテストの点数が0.1点上げるだけかもしれません.これだと補習やった甲斐がない気がします.これを示すのが効果量です (ようやく出てきました).今回は補習を行っていない母集団と,行った母集団の平均値の差を比較するCohen's dという効果量を使用してみましょう.
Cohen's dの定義は以下の通りです.
$$
\begin{eqnarray}
\displaystyle d = \frac{M_2 - M_1}{\sqrt{\frac{SD_{1}^{2} + SD_{2}^{2}}{2}}}
\end{eqnarray}
$$
(where $M_1$ and $M_2$ are the means for the 1st and 2nd samples, $SD_1$ and $SD_2$ are the standard deviation for the 1st and 2nd samples)
上の定義式に基づいて計算してみると,効果量$d=0.27$となりました.
どのくらいの効果量ならばよしとするのかは場合によるので,一概にこのくらいの効果量が無いとダメ,というのは無いと思います.ただ,効果量の値と効果の大きさの目安は存在します.しかしあくまで慣例であり,学問の領域によってもまちまちなようです.Cohen(1988)が提唱した行動科学における効果量の目安が有名らしいので.その基準の抜粋を載せておきます.
| 項目 | 指標 | 効果量小 | 効果量中 | 効果量大 |
|---|---|---|---|---|
| 相関係数 | $$r$$ | 0.10 | 0.30 | 0.50 |
| 独立な2群のt検定 | $$d$$ | 0.20 | 0.50 | 0.80 |
| 重回帰分析 | $$R^2$$ | 0.02 | 0.13 | 0.26 |
上の表に照らすと,独立な2群のt検定のところを見ればよいので,今回得られた$0.27$という効果量は小さいほうだと言えそうです.
ここまでの分析で,補習には効果があったと言えるが,その効果はあまり大きくなかった.ということがわかりました.
ところで,Cohen's dを始めとする効果量は,サンプルサイズに依存しません.p-valueはサンプルを頑張って集めれば,小さくはしやすいので有意であるという結論にもしやすいです.しかしサンプルサイズを大きくして有意にしたからといって,その効果があるのかどうかという疑問には実は答えていないのです.当たり前の話ですが,効果があると言えるくらいの差を出すことができて初めて効果があったといえるんですね.そのため,仮説検定をした実験結果を発表するときはp-valueを計算して有意になったと言うだけでなく,効果量も一緒に出してどの程度の効果があったのかも言及することが大事です.例えばよく眠れる薬が開発されて,しかも$.05$の有意水準で有意でした!という発表があっても,その効果が実は1回の睡眠につき10秒しか睡眠時間を伸ばさないものだったら多分がっかりですよね?
ちなみに,サンプルサイズを大きくすれば何でも有意になる,というのは誤解です.実際に帰無仮説が真ならばサンプルサイズをいくら大きくしても帰無仮説が棄却されることはほぼありません4.ただし,サンプルサイズを大きくすれば有意になりやすくはなります.サンプルサイズを大きくすると小さな効果であっても検出されやすくなるからです.
今回は仮説検定を行ってから得られたデータの効果量を算出しましたが,逆に一定の条件5のもとに,このくらいの効果量が欲しい!という数値を決めておくことで,仮説検定に必要なサンプルサイズを計算することができます.このサンプルサイズと有意水準で有意だと言えれば,条件として与えた効果量は保証できる,ということですね.このあたりの話は余裕があればまた書くかもしれません.
参考にしたサイト
- 効果量と検定力分析入門 ―統計的検定を正しく使うために― 『より良い外国語教育研究のための方法』(pp. 47–73) 外国語教育メディア学会 (LET) 関西支部 メソドロジー研究部会 2010 年度報告論集
- 水本 篤・竹内 理 研究論文における効果量の報告のために―基礎的概念と注意点― 英語教育研究 2008 31;57-66.
- 効果量・検出力・サンプルサイズ
- 効果量 (effect size) とは何か?|薬剤師のためのEBMお悩み相談所-基礎から実践まで
- 仮説検証とサンプルサイズの基礎 - クックパッド開発者ブログ
- meta-analysis
- 施策の効果をどうやって測るか(2) - 検出力と効果量 - About connecting the dots.
- 効果量(effect size)のはなし - 六本木で働くデータサイエンティストのブログ
- 31-2. 効果量1 | 統計学の時間 | 統計WEB
- 効果量・検定力・サンプルサイズ - Murakami's Memorandum
- TAKENAKA's Web Page: 有意性検定の無意味さ
-
p-valueは確率密度関数を定積分した値なので,こういう分かり辛い表現になってしまうんですよね.. ↩
-
欲しい検出力と効果量を先に決めておき,サンプルサイズをどの程度の大きさにするかを決める,というアプローチもある (そちらのほうがスタンダード?) ↩
-
ここ,本当は2つの分布が同じ分散値かどうかを仮説検定してその結果如何で平均値の検定法変えたりとか面倒なんですが,ここの平均値比較の考えとかを見ると多重検定の問題が発生するので,いっそのこと等分散性を仮定せずにWelchのt検定してもいいのでは,と思えるのでそうします.詳しくはリンク先を読んで下さい) ↩
-
当然,有意水準の確率で第一種の過誤は起こります ↩
-
有意水準,検出力を条件として与えておく ↩