概要
データ解析のコンペティションや練習問題を提供してくれるSIGNATEというサービスでデータ解析の面白さに触れてみたいとおもいます。
今回は練習問題の「自動車の走行距離予測」を解いていきたいとおもいます。
利用したもの
- jupyter notebook
何を予測するか?
この問題で予測するものは、ガソリン1ガロンあたりの走行距離になります。
自動車の重量や加速度などのデータを利用して、ガソリン1ガロンあたりの走行距離を求める問題になります。
分析方法
今回は、「重回帰分析」を利用して問題をといていきます。
「自動車の走行距離予測」の説明文に、課題種別:回帰と書いているので、回帰分析の一つである重回帰分析を利用していきます。
重回帰分析よりいい分析方法(アンサンブル学習する方法とか)があるよ!というのもわかりますが、一旦重回帰分析で進めていきます。
この問題では、以下のデータ種別があります。
- シリンダー
- 変位
- 馬力
- 重量
- 加速度
- 年式
- 起源
- 車名
これらのデータからガソリン1ガロンあたりの走行距離を求めるには、おそらく複数のデータ種別を利用して求める必要があります。
そのため、今回は複数のデータ種別から解を算出する用途の重回帰分析を利用しています。
回帰分析には、重回帰分析以外にも、単回帰分析、ロジスティクス回帰分析などがあります。
詳しくはこちらの回帰分析とその主な目的。単回帰分析・重回帰分析・ロジスティック回帰分析の違いについてとかを見ていただければ!
さっそく分析をはじめよう
今回はjupyther notebookでデータ解析を行います。
Anacondaを利用して環境構築をするとすばやく利用できると思います。
こちらからダウンロードできます
利用するライブラリは以下になります
インストールできていない場合はエラーが出ると思います。
そのときはpip installで必要なライブラリをインストールしてください。
- seaborn
- pandas
- scikit-learn
その後、SIGNATEのデータタブから学習用のデータと評価用のデータをダウンロードします。
学習用データには、今回求めたいガソリン1ガロンあたりの走行距離(mpg)が含まれています。
評価用データには、ガソリン1ガロンあたりの走行距離(mpg)が含まれていないデータが入っています。
重回帰分析をするときには、学習用データを利用してガソリン1ガロンあたりの走行距離(mpg)を求める式を作成します
とりあえず重回帰分析
1.はじめに必要なライブラリのimport
import pandas as pd
from pandas import DataFrame
import seaborn as sns
from sklearn.linear_model import LinearRegression
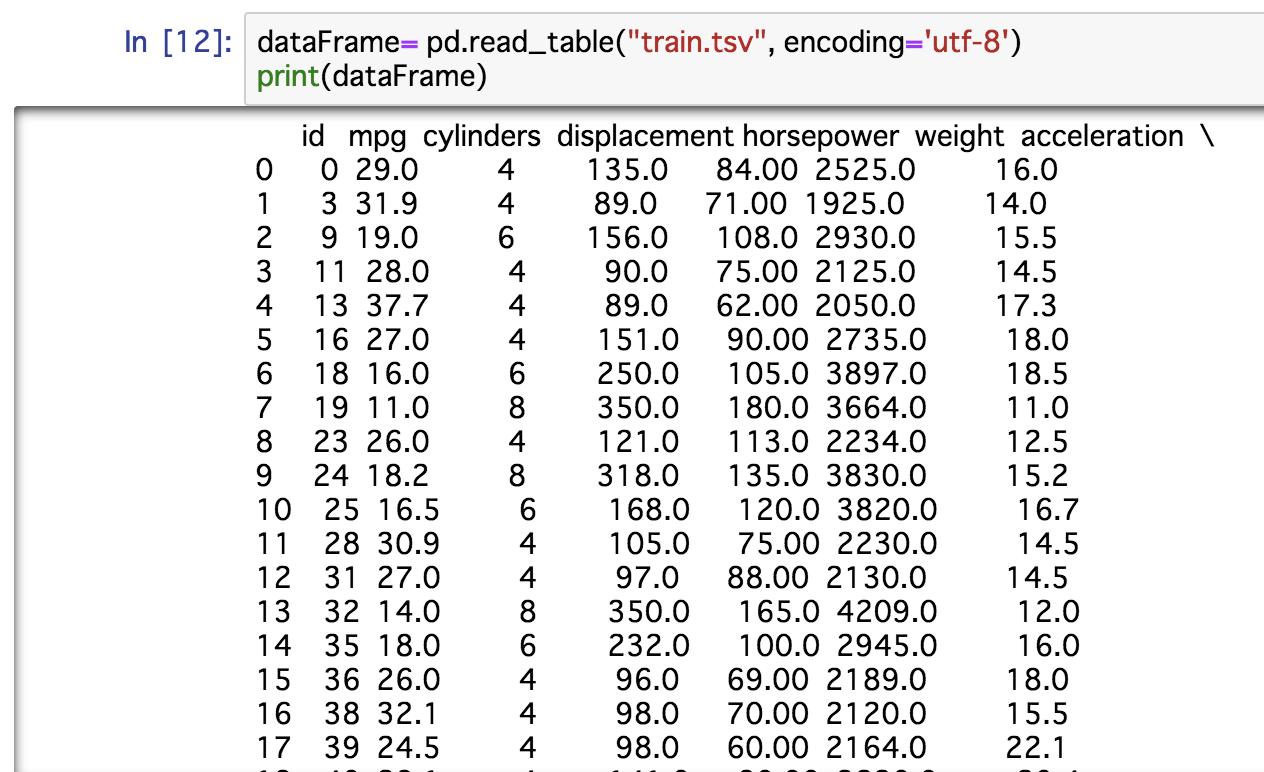
2.学習用データtrain.csvの読み込み
dataFrame = pd.read_table("train.tsv", encoding='utf-8')
print(dataFrame)
3.求めたいガソリン1ガロンあたりの走行距離(mpg)とそれぞれのデータの相関を確認
以下のようにseabornを利用することで、簡単にそれぞれのデータとの相関を表示することが出来ます。
sns.pairplot(dataFrame, height=5, markers="+", x_vars=["horsepower", "cylinders", "displacement", "weight", "acceleration", "model year"], y_vars=["mpg"])
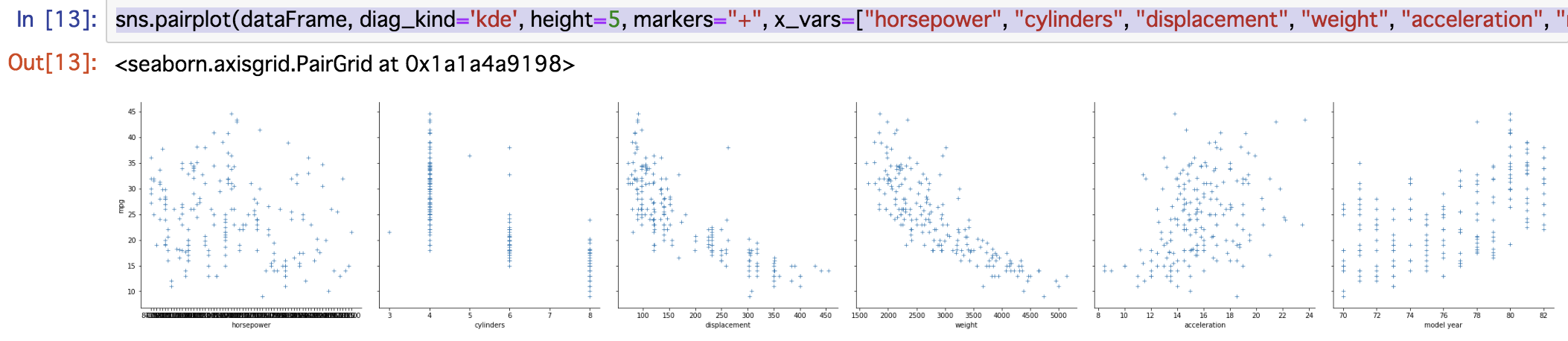
※縦軸がmpgで、横軸が左からhorsepower, cylinders, displacement, weight, acceleration, model year
グラフを見ると、cylindersとdisplacement, weight, model yearがmpgと相関があるだろうとわかります。
ということで、この4つの項目でひとまず重回帰分析をしてみます。
4.重回帰分析で利用するデータを定義
今回は4つの項目で重回帰分析を行います。
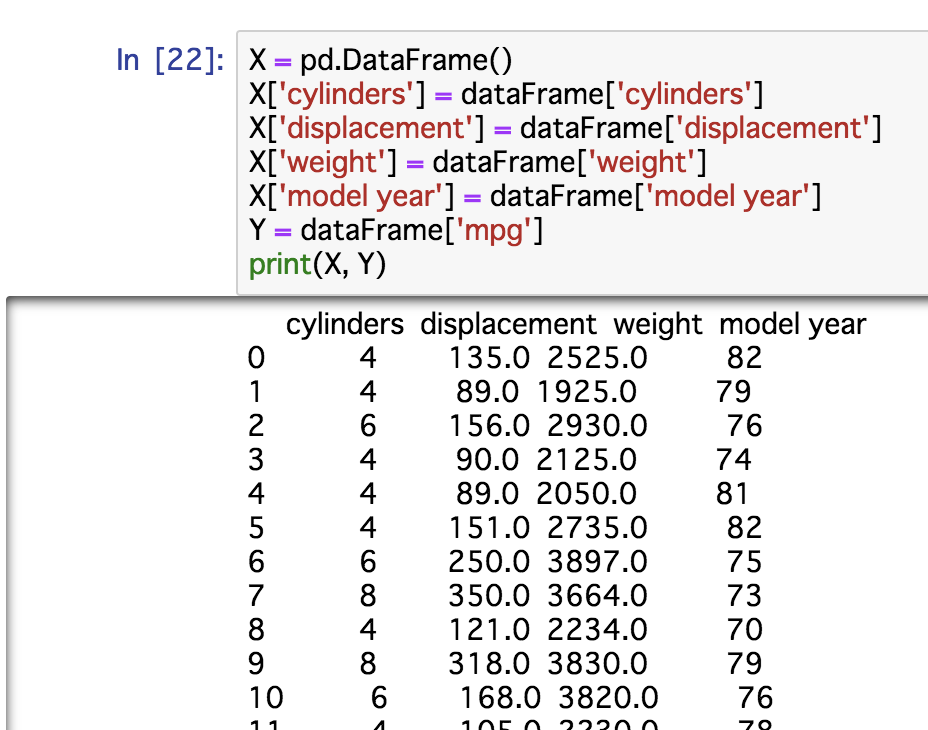
まずはじめに利用するデータを作成します。
さきほどの 3.で相関があったデータを X変数に、結果となる mpgのデータをY変数にいれていきます。
X = pd.DataFrame()
X['cylinders'] = dataFrame['cylinders']
X['displacement'] = dataFrame['displacement']
X['weight'] = dataFrame['weight']
X['model year'] = dataFrame['model year']
Y = dataFrame['mpg']
print(X, Y)
5.傾きa1 ~ a4と切片bの値を計算
重回帰分析は複数のデータX1 ~ X4(それぞれcylinders, displacement, weight, model yearに当てはまる)と結果のデータY(mpgに当てはまる)から、以下の式の傾きa1 ~ a4と切片bの値を計算します。
Y = a1 * X1 + a2 * X2 + a3 * X3 + a4 * X4 + b
傾きa1 ~ a4と切片bが分かれば、あとはX1 ~ X4のデータ(cylinders, displacement, weight, model year)さえあればYのデータ(mpg)を予測することができます。
一応変数の対応表としてはこちらになります。
| 項目 | 対応するデータ |
|---|---|
| a1 | cylindersの傾き |
| a2 | displacementの傾き |
| a3 | weightの傾き |
| a4 | model yearの傾き |
| b | 切片 |
| X1 | cylindersのデータ |
| X2 | displacementのデータ |
| X3 | weightのデータ |
| X4 | model yearのデータ |
| Y | mpgのデータ |
その傾きa1 ~ a4と切片bを計算するためにLinearRegressionのfitメソッドを利用します。
linear_regression = LinearRegression()
linear_regression.fit(X,Y)
6.計算した結果の傾きa1 ~ a4の値を取得
求められた傾きは以下のようになります。
| 項目 | 値 | 対応するデータ |
|---|---|---|
| a1 | -0.23905993 | cylindersの傾き |
| a2 | -0.00154163 | displacementの傾き |
| a3 | -0.00626588 | weightの傾き |
| a4 | 0.76239545 | model yearの傾き |
A = linear_regression.coef_
print(A)

7.計算した結果の切片bの値を取得
求められた切片は以下のようになります。
| 項目 | 値 | 対応するデータ |
|---|---|---|
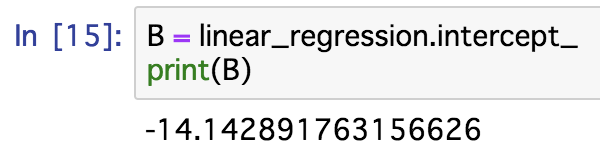
| b | -14.142891763156626 | 切片 |
B = linear_regression.intercept_
print(B)
8.mpgの予測を行う
6.と7.から以下の式の傾きa1 ~ a4と切片bがわかりました。
Y = a1 * X1 + a2 * X2 + a3 * X3 + a4 * X4 + b
あとは式通りに計算すれば変数Y、つまりmpgの値を予測値を出すことができます。
各変数の意味を再掲すると以下になります。
| 項目 | 対応するデータ |
|---|---|
| a1 | cylindersの傾き |
| a2 | displacementの傾き |
| a3 | weightの傾き |
| a4 | model yearの傾き |
| b | 切片 |
| X1 | cylindersのデータ |
| X2 | displacementのデータ |
| X3 | weightのデータ |
| X4 | model yearのデータ |
| Y | mpgのデータ |
では、計算していきましょう。
2.では学習用のデータを読み込みましたが、次は評価用のデータのtest.tsvを読み込みます。
その後、評価用のデータでmgpの値であるYを計算します。
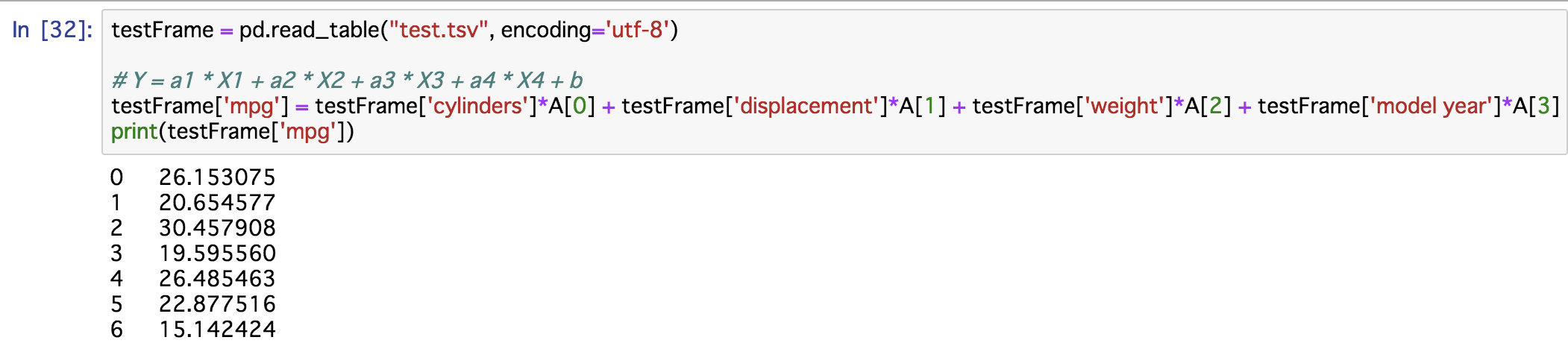
testFrame = pd.read_table("test.tsv", encoding='utf-8')
# Y = a1 * X1 + a2 * X2 + a3 * X3 + a4 * X4 + b
testFrame['mpg'] = testFrame['cylinders']*A[0] + testFrame['displacement']*A[1] + testFrame['weight']*A[2] + testFrame['model year']*A[3] + B
print(testFrame['mpg'])
9.提出用のファイルを作成
SIGNATEに提出するためのファイルを作成する必要があります。形式は以下で指定されているため、それ通り作成します。
1列目に評価用データの"id"を、2列目に予測したガソリン1ガロンあたりの走行距離"mpg"を記入したファイルを、ヘッダ無しcsv形式で投稿ください。
testFrame[['id', 'mpg']].to_csv('./submit.csv', header=False, index=False)
はい。おわり。
あとは提出するだけです!
10.SIGNATEに予測したmpgのデータをcsv形式で提出
提出すると数分後に評価結果が返ってきます。

0に近ければ近いほど、予測したmpgの値が実際のmpgの値に近いことを表します。
今回は3.44317という結果になりましたが、どのデータを用いて重回帰分析をするのかでこの値は結構変わってきます。
いろいろ試してみてください。
おわりに
今回愚直に与えられたデータをそのまま重回帰分析を行いました。
学習用データを見ると、自動車の国別でも分けて考えることも可能なようです。
恐らくドイツ車、日本車、アメリカ車で性能は異なると思うため、それぞれで重回帰分析をするとより良い予測が可能なのではないでしょうか?
いろいろと工夫の方法はあると思うので、是非「ぼくのかんがえたさいきょうのよそく」を作ってみてください。