本記事にはOracle Cloud Infrastructure (OCI)の分析サービスAnalytics Cloud(OAC)及びデータレイクサービスを利用して、製造メーカーの販売店/卸業者から貰うPDFファイル形式の販売履歴をデータベースに取り込んで、自社の在庫データと結合して、在庫分析を行う方法をご紹介します。
利用したサービス
- Autonomous Data Warehouse (ADW)
- Oracle Analytics Cloud (OAC)
- Oracle Cloud Infrastructure (OCI) Data Science
- Object Storage
上記のサービスで、非構造化と構造化データを統合した分析のシナリオを検証しました。
構成図
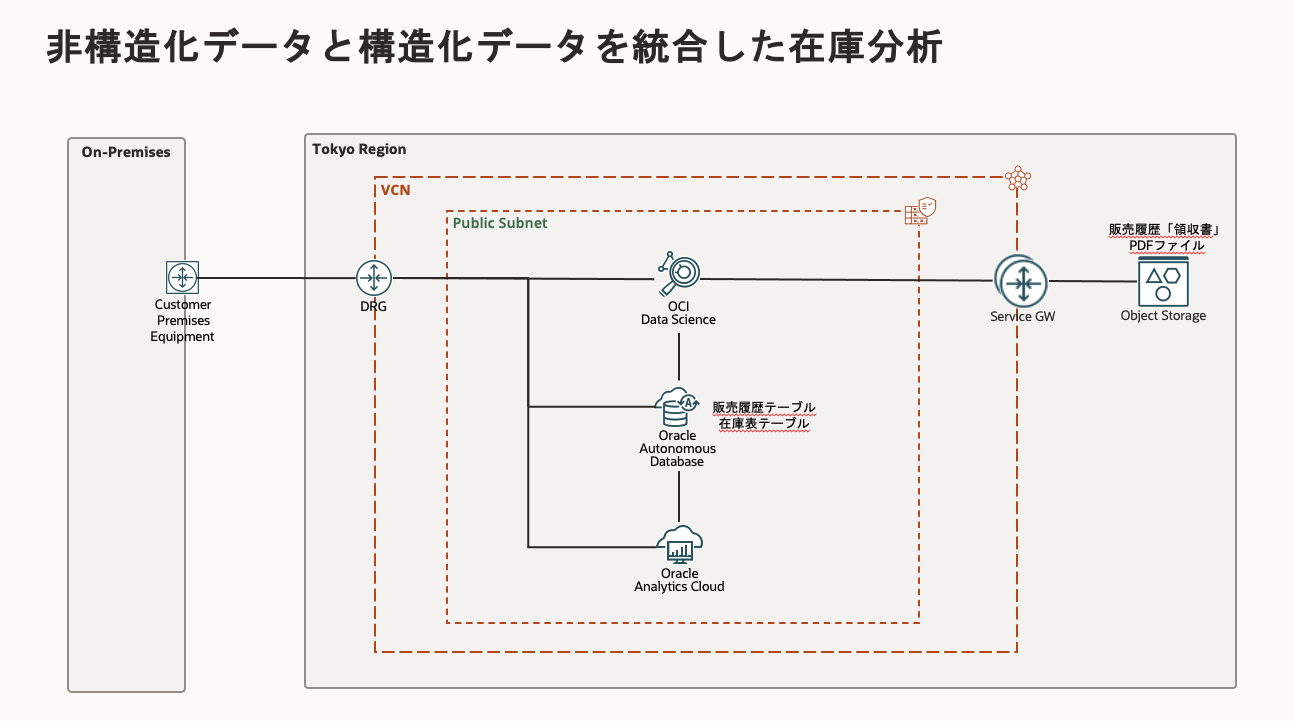
前提条件
- 利用したサービスの作成
- PDFファイルの販売履歴「領収書」を用意
ダミーのPDFファイルをGithubにアップロードしたので、ご参考ください。
実装手順
下記の流れで実装します。
- 領収書のPDFファイルをObject Storageにアップロード
- Data Scienceで販売履歴をPDFファイルから抽出し、ADWのテーブルに取り込み
- ADWで分析のテーブルビューを作成
- OACで在庫分析を行い
領収書のPDFファイルをObject Storageにアップロード
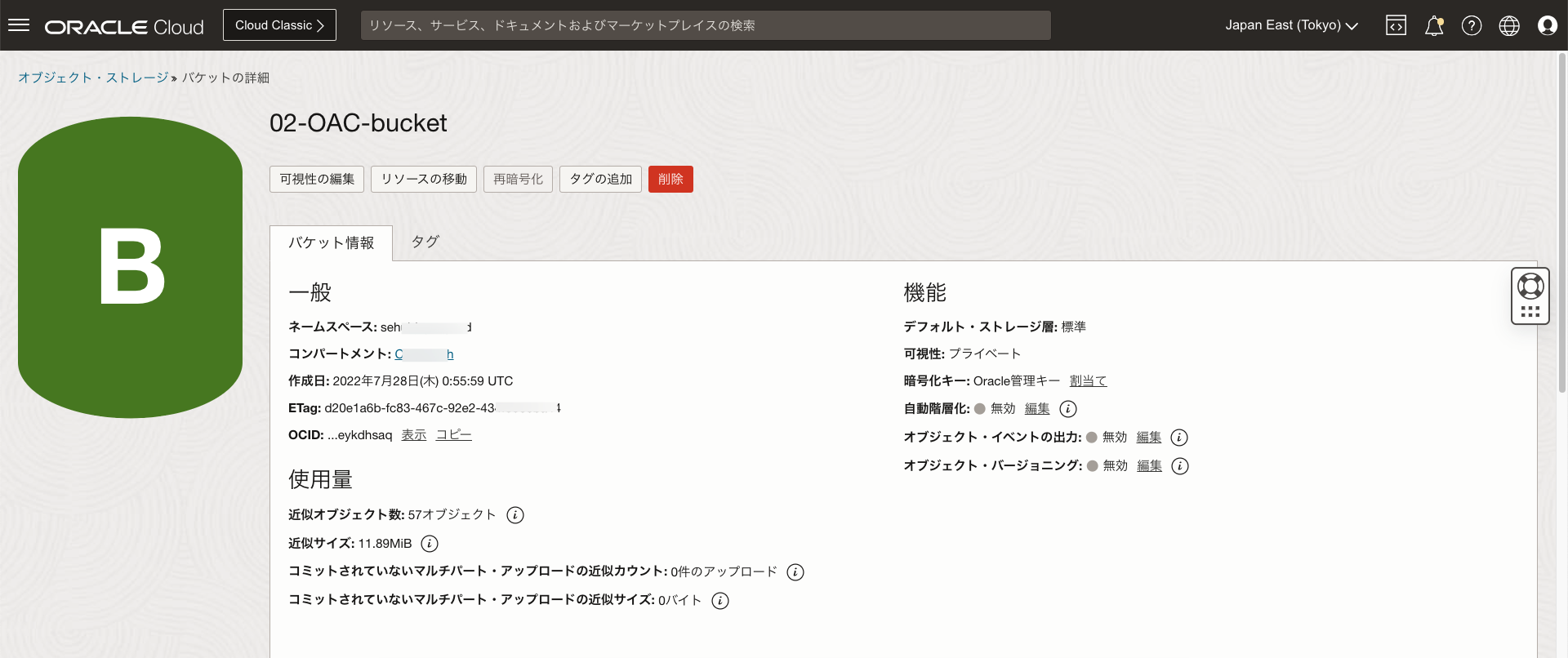
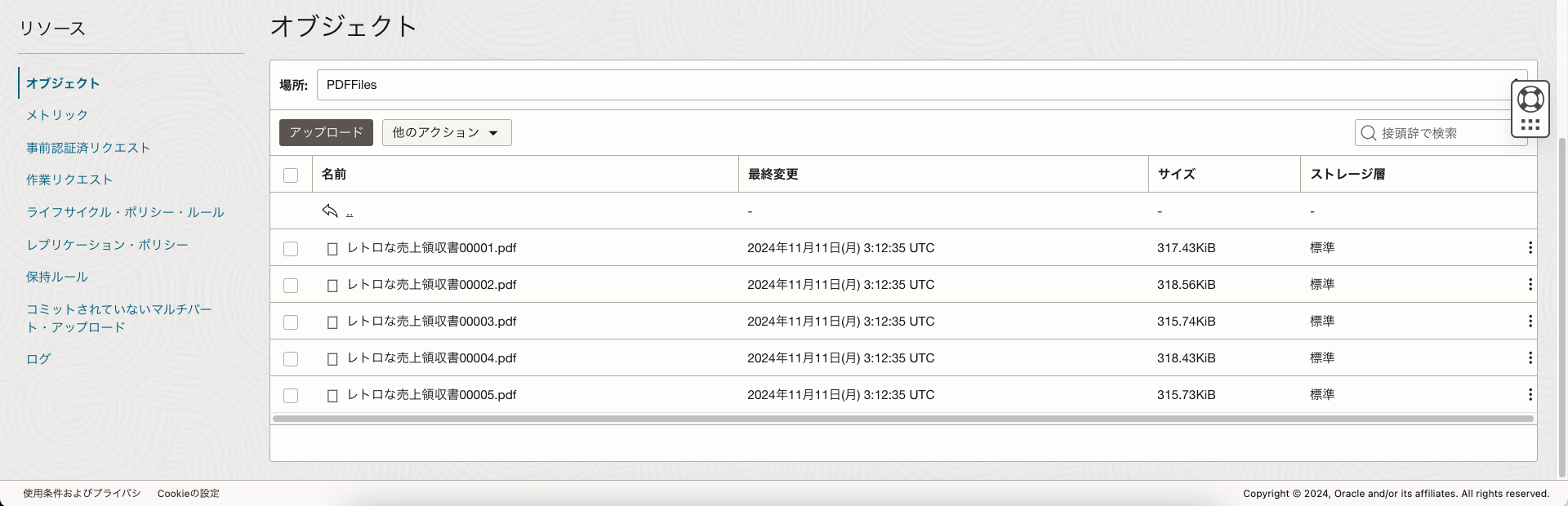
Data Scienceで販売履歴をPDFファイルから抽出し、ADWのテーブルに取り込み
Data Scienceのノートブックを作成します。
pdfplumberをインストールします。
!pip install pdfplumber
処理に必要なパッケージをインポートします。
import ads
import re
import pandas as pd
from ads.text_dataset.backends import Base
from ads.text_dataset.dataset import TextDatasetFactory as textfactory
from ads.text_dataset.extractor import FileProcessor, FileProcessorFactory
from ads.text_dataset.options import Options
ads.set_debug_mode()
ads.set_auth("resource_principal")
オブジェクトストレージの情報を定義します。
namespace = "sehubjapacprod"
bucket = "02-OAC-bucket"
folder = "PDFFiles"
OCIサービスのアスセス認証を設定する必要となります。下記のドキュメントを参照して、認証用のconfigファイルとKeyファイルをData Scienceのサーバーにアップロードします。
オブジェクトストレージのPDF領収書から下記の販売情報を取り出します。
「'数量', '品目番号', '内容', '単価', '割引', '行の合計', '領収書番号', '日付'」
# ファイル名リストを定義
file_names = [
"レトロな売上領収書00001.pdf",
"レトロな売上領収書00002.pdf",
"レトロな売上領収書00003.pdf",
"レトロな売上領収書00004.pdf",
"レトロな売上領収書00005.pdf"
]
# コンマを含む通貨額をマッチできるように更新した正規表現パターン
ITEM_PATTERN = r"(\d{1,4})\s+([A-Z]\d+)\s+(.+?)\s+\$([\d,]+\.\d{2})\s+\$([\d,]+\.\d{2})\s+\$([\d,]+\.\d{2})"
RECEIPT_NUMBER_PATTERN = r"領収書番号\s+(\d+)"
DATE_PATTERN = r"日付\s+(\d{4}/\d{2}/\d{2})"
# 空のDataFrameを初期化
combined_df = pd.DataFrame()
# 各ファイルをループして読み込む
for file_name in file_names:
# PDFの内容を読み込む
dl = textfactory.format("pdf").backend("pdfplumber").engine("pandas")
content_df = dl.read_line(f"oci://{bucket}@{namespace}/{folder}/{file_name}", storage_options={"config": {}})
# DataFrameを文字列に変換
content_str = content_df.to_string(index=False)
# 領収書番号と日付を検索
receipt_number_match = re.search(RECEIPT_NUMBER_PATTERN, content_str)
date_match = re.search(DATE_PATTERN, content_str)
if receipt_number_match and date_match:
receipt_number = receipt_number_match.group(1)
date = date_match.group(1)
else:
# 領収書番号または日付が見つからない場合、そのファイルをスキップ
continue
# 各販売記録を抽出
sales_records = re.findall(ITEM_PATTERN, content_str)
# 各記録を処理し、コンマを削除して領収書番号と日付を追加
records_with_info = [
(record[0], record[1], record[2], record[3].replace(',', ''), record[4].replace(',', ''), record[5].replace(',', ''), receipt_number, date)
for record in sales_records
]
# 記録をDataFrameに変換し、全体のDataFrameに追加
df = pd.DataFrame(records_with_info, columns=['数量', '品目番号', '内容', '単価', '割引', '行の合計', '領収書番号', '日付'])
combined_df = pd.concat([combined_df, df], ignore_index=True)
# マッチした結果を出力
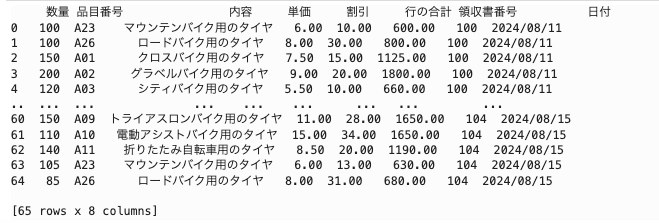
print(combined_df)
ADWに接続するため、ウォレットファイルをData Scienceのサーバーにアップロードし、接続情報を指定します。
# ウォレットファイルを使用する場合は、`wallet_location` に zip ファイルのパスを指定する。
connection_parameters = {
"user_name": "oml_user",
"password": "xxxxxxxx",
"service_name": "adwml_high",
"wallet_location": "/home/datascience/Wallet_ADWML.zip",
}
PDFから抽出した下記の販売データをADWに格納します。
「'数量', '品目番号', '内容', '単価', '割引', '行の合計', '領収書番号', '日付'」
combined_df.ads.to_sql(
"販売履歴",
connection_parameters=connection_parameters, # Should contain wallet location if you are connecting to ADB
if_exists="replace"
)
ADWで分析のテーブルビューを作成
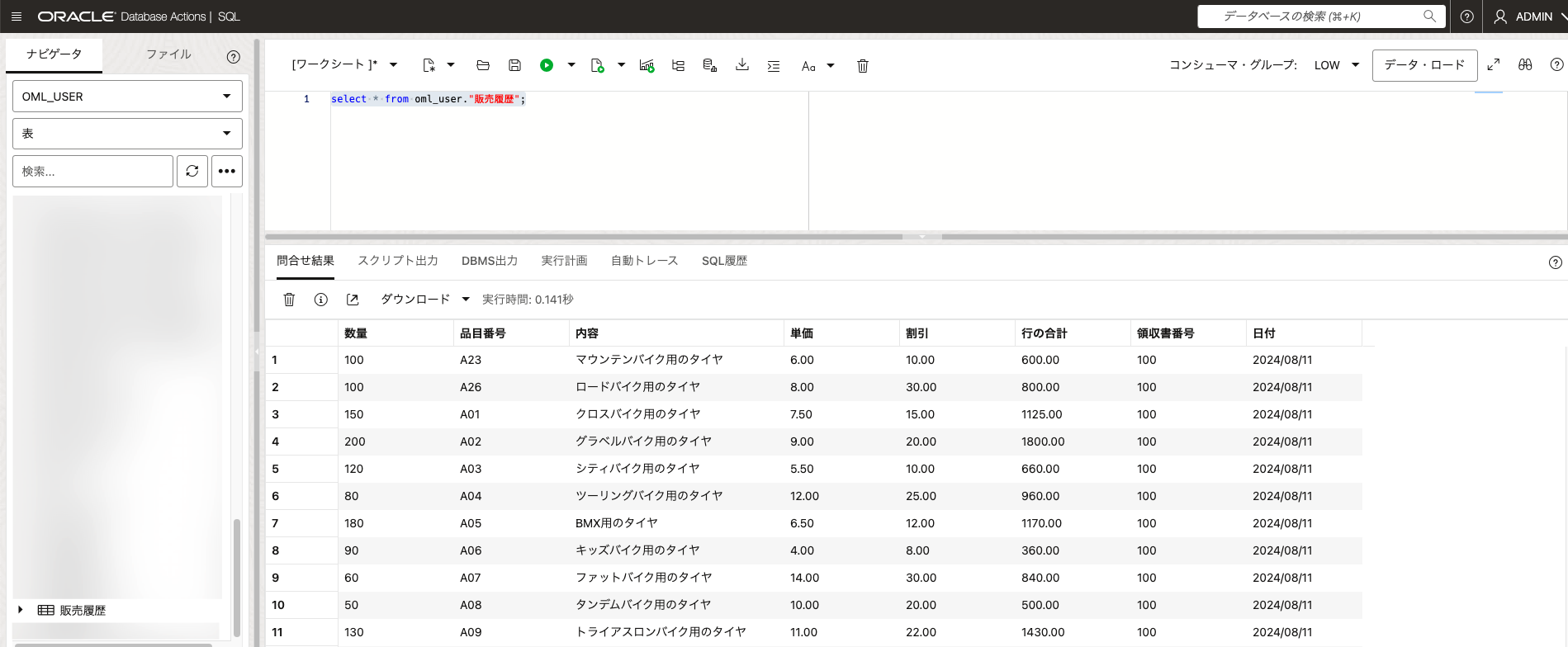
ADWにアップロードした販売履歴のデータを確認します。
初期在庫量のダミーテーブルを作成します。仮に各品目に対して、全部1000個の商品在庫で作成します。
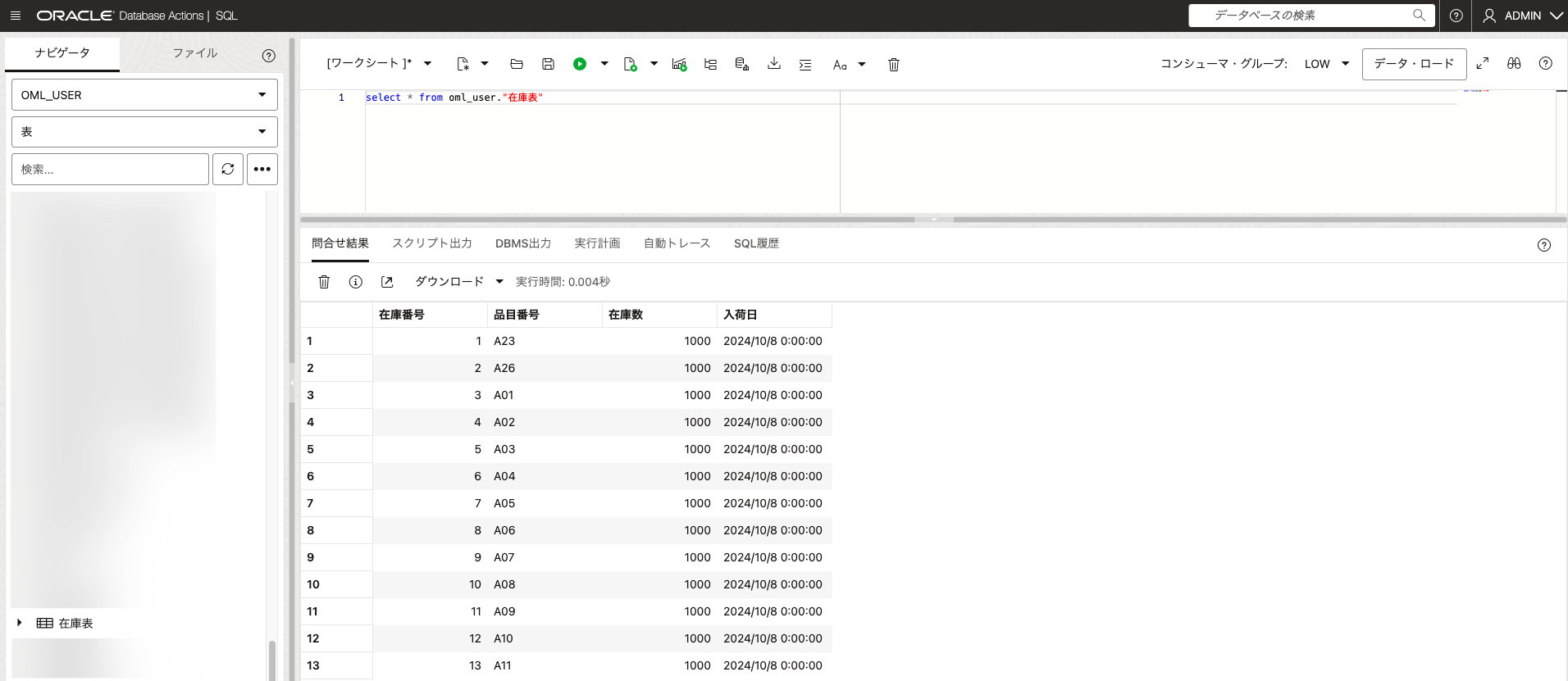
在庫表のDDLが下記となります。
CREATE TABLE OML_USER.在庫表
(
在庫番号 NUMBER ,
品目番号 VARCHAR2 (64) ,
在庫数 NUMBER ,
入荷日 DATE
)
TABLESPACE DATA
LOGGING
;
次にはテーブル「在庫表」と「販売履歴」のデータで毎日の残り在庫数を算出し、ビューに格納します。
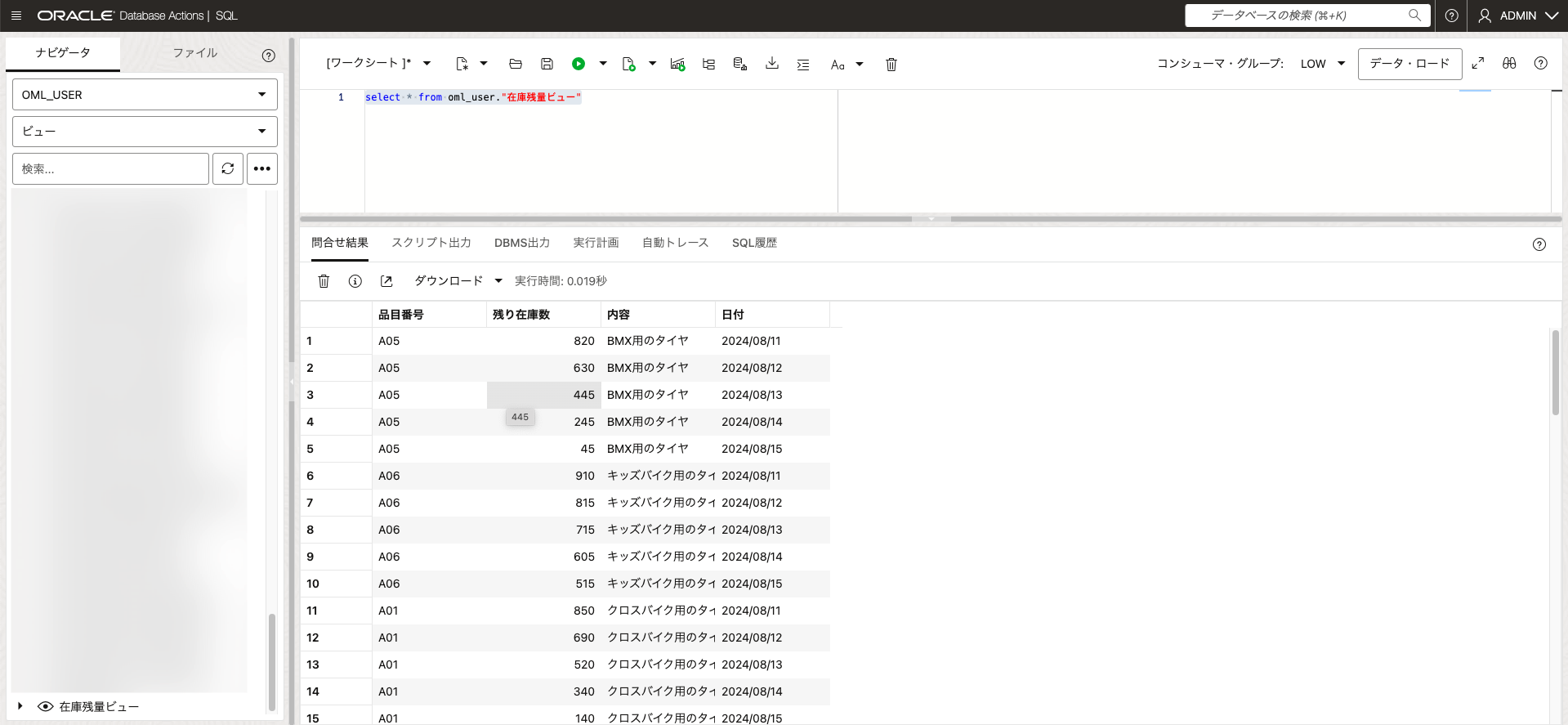
在庫残量ビューのDDLが下記となります。
CREATE VIEW OML_USER.在庫残量ビュー ( 品目番号, 残り在庫数, 内容, 日付 ) AS
SELECT
i."品目番号",
i."在庫数" - COALESCE(t."累積販売量", 0) AS "残り在庫数",
h."内容",
h."日付"
FROM
OML_USER."在庫表" i
LEFT JOIN (
SELECT
h1."品目番号",
h1."日付",
SUM(h2."数量") AS "累積販売量"
FROM
OML_USER."販売履歴" h1
JOIN
OML_USER."販売履歴" h2
ON
h1."品目番号" = h2."品目番号"
AND h1."日付" >= h2."日付"
GROUP BY
h1."品目番号",
h1."日付"
) t
ON
i."品目番号" = t."品目番号"
LEFT JOIN
OML_USER."販売履歴" h
ON
i."品目番号" = h."品目番号"
AND t."日付" = h."日付"
GROUP BY
i."品目番号",
i."在庫数",
t."累積販売量",
h."内容",
h."日付"
ORDER BY
h."内容",
h."日付"
;
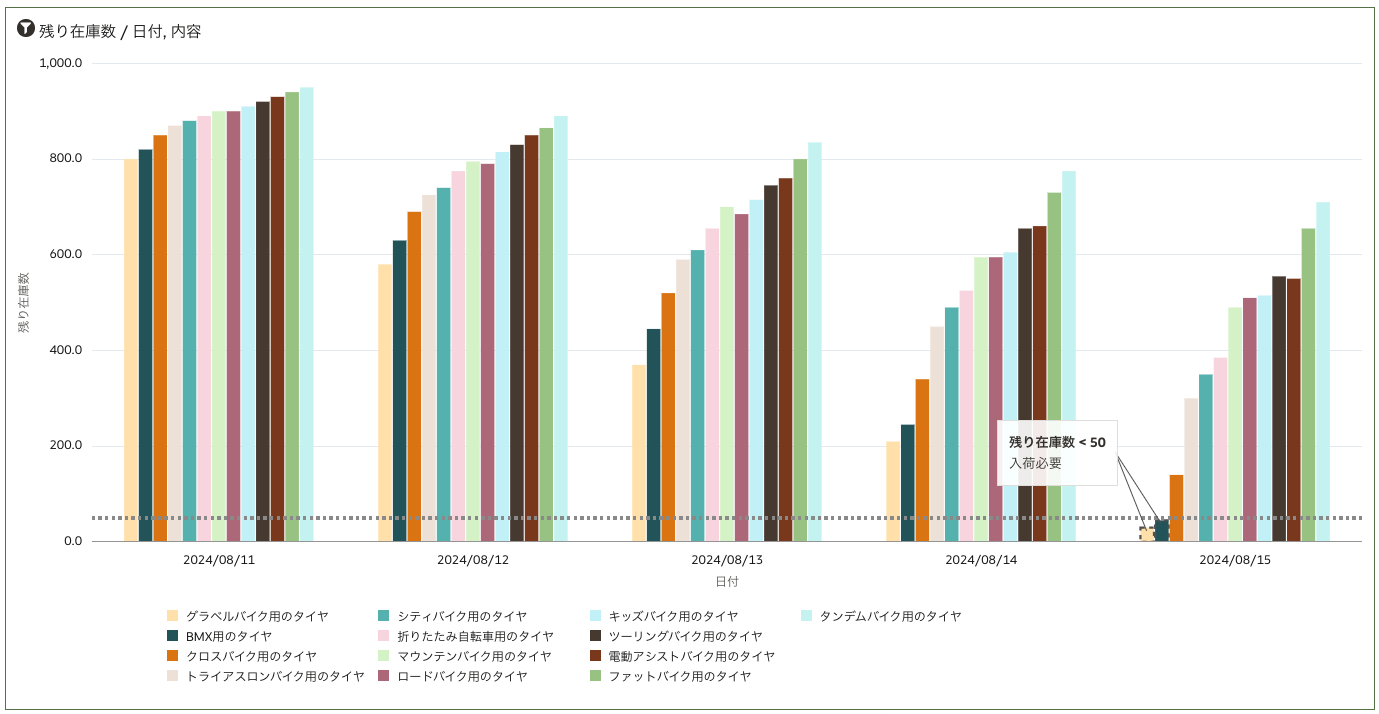
OACで在庫分析を行い
OACで在庫残量ビューのデータを取り込み、在庫状況のグラフを作成します。また基準線と条件付き書式の機能を利用して、在庫数がマイナス50個の商品をハイライトします。
最後に
OACには構造化のデータを利用して分析を行うサンプルが多いですが、今回OCI Data Scienceサービスと統合して、非構造化のPDFファイルにも分析できることを検証しました。非構造データと構造データを統合して分析を行うニュースがこれからも増えるかと思っているから、興味があればこの製品の組み合わせでやってみてください。