この記事はトラストバンクAdventCalendar 1日目になります
エンジニアリングマネージャーの @featkjです
去年の11月に入社してから、はや1年たちました。開発組織として1年間で多くの取り組みを行ってきたので組織の振り返りを書こうかなと思いましたが、1日目はライトなところから行きたいなと思います。まだ検証段階ですが業務改善取り組みの一つとして検証しているtblsの活用について書いていこうと思います。
tbls利用の背景
ふるさとチョイスはサービス開始から12年経ち、その間に様々な機能が追加され成長してきました。DBのテーブル数に至っては500以上あり、都度有識者に聞かないと内容を把握する事が難しい状態にもなっています。属人化を全て解消するというのは現実的ではないと思っているのですが、全員が知っておくべき(知っておいて欲しい)コア機能はどんなプロダクトにも必ず存在します。自分の理解を深めるためと新しい方もたくさんjoinしてくれているので、整理するには良い機会だと考えました。あと個人的にコーヒーを飲みながらリファクタに思いを馳せたい時にパッと見れる情報をまとめておきたかったという思いもあります^^;
何を整理したいのか
DBドキュメント自動化ツールで一般的に思いつくのがテーブル定義書を作成してくれるイメージを持つ方も多いのかなと思います。ただテーブル定義はQuery叩けば見れる(mysqlで言えばshow columns from テーブル名)のでそんなに有効性を感じないかなと思います。やっぱり欲しいのはデータ関連ですよね!もっというとデータ構成だけでなく、重要な関心毎にフォーカスしてまとめられると良いなと思っています。
なぜtbls?
viewpointが求めている機能そのものだった
色々なツールを調査しようと思ったのですが、初期調査の段階でtblsのviewpointが一番求めていたものに近く導入や運用のイメージもついたので、tbls採用前提で検証することにしました。
CIとの親和性の高さ
なるべく開発フローの中で自然にメンテナンスができるような構成が取れたらいいなと思っています。
tblsにはlint機能などもあるので、今後効率化をしていく上の機能拡張ができそうと思っています。特に1テーブルのカラム数をチェックできる機能とか新しいテーブル追加した時に気づきを与えてくれそうで、負債予防にもなりそうだなと感じました。
# check max column count
columnCount:
enabled: true
max: 10
導入の方針
整理したい箇所にフォーカスして整理する
よくやってしまいがちな事で、ドキュメント全部を統一化しようとしていろんなパターンを想定して資料が複雑化してしまう事です。そうなると誰も見なくなり、ドキュメント作成業務が形骸化する最悪なパターンになってしまいます。情報として価値のあるものにフォーカスして取り組むことが最も重要です。
価値の定義
以下の条件で整理していく対象を特定していく。
・機能改修が多く入っている機能 (プロダクトバックログ、githubの履歴で判断)
・複雑な処理を行っている機能 (有識者へのレビューを依頼している、QAに時間がかかる、問い合わせが多い)
リファクタ優先順位を決める時とほぼ同じような感じになるのかなと思います。この考え方はデータ構成に限らず、どのドキュメント整理にも使える概念ではないでしょうか。プロダクトの状態によってはコードの複雑性を対象条件にしておくとモデル再設計時も含めた優先度付けをする際に役立つかもしれません。
tblsの導入
導入自体は非常に簡単なので公式見てもらう方が早いと思います。またローカルとりあえず試したいという方もいると思うので、docker-compose.yml 貼っておきます
# docker-compose.yml
version: "3" ##←忘れがち
services:
tbls:
image: ghcr.io/k1low/tbls:latest
volumes:
- ./tbls.yml:/tbls.yml
- ./dbdoc:/dbdoc
command: doc --force
profiles:
- tbls
env_file:
.env
# tbls.yml
name: tbls_test
desc: tblsデモ
# DSN (Database Source Name) to connect database
dsn: my://${DATABASE_USER}:${DATABASE_PASSWORD}@host.docker.internal:3306/tbls_test
# Path to generate document
# Default is `dbdoc`
docPath: dbdoc
#.env
DATABASE_USER=xxx
DATABASE_PASSWORD=xxx
小ネタ
開発DBが踏み台サーバーの先にある構成も多いと思うので、そんな時はポートフォワーディングしてあげると楽かもしれません。
ssh -f -N -C -L {任意のローカルポート}:{接続先DB}:{接続先DBポート} {db_user}@{踏み台IP}
実行
docker-compose run tbls
デモDBで活用方法を解説
Productionテーブルは公開できないので、仮想ECサイトのテーブルを作成してみました。こちらをベースに活用イメージを紹介できればと思います。
- テーブル数:16
何も設定せずに出力してみる
テーブル図の設定

テーブルが横一列に並んでいる図です。あまり使わなそう。
リレーションを貼った例
# tbls.yml
detectVirtualRelations:
enabled: true
strategy: default
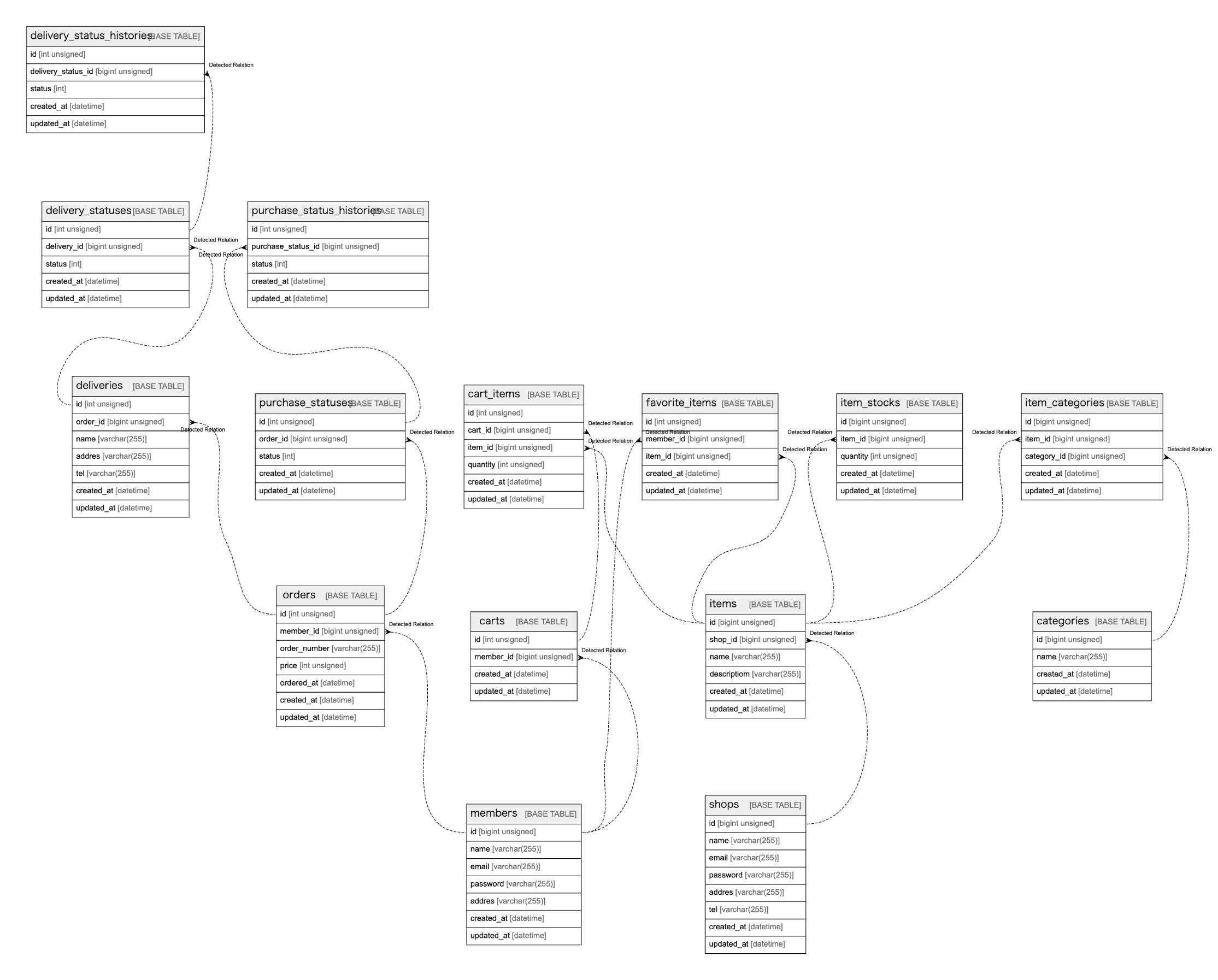
リレーションが貼られて関係性が見やすくなりました。テーブル数が20以下程度であれば認識できるのかなと思います。これ以上テーブルが多くなるとなかなかカオスな状態になりそうです。(productionテーブルで実行した際はとても把握できるような状態ではありませんでした。)
viewpointの実例
商品関連情報をviewpointを使ってまとめてみましょう
# tbls.yml
viewpoints:
-
name: 商品情報
desc: >
商品情報関連テーブルまとめ
tables:
- shops
- items
- item_categories
- item_stocks
- categories
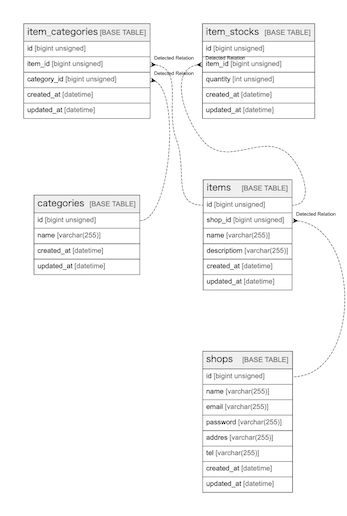
商品に関連するテーブルだけをまとめてみました。商品にどのような情報が存在しているのか把握しやすくなりとても見やすいかなと思います。ただこれだけの情報であればtblsがデフォルトで用意してくれるリレーションで事足りるのでviewpointで整理する必要はないかもしれません。
viewpointの実例(データ構成ごと)
groupsの素敵な機能を使ってみます。自分が検討する際に便利だと思った機能でもあります!tblsにはviewpointの中でカテゴライズできるgroupという設定があり、細分化する事ができます。商品に関連する情報でも商品と切り離して考えても良い情報・商品が参照のみで利用しているデータを明確にすることができます。
viewpoints:
-
name: 商品情報
desc: >
商品情報関連テーブルまとめ
tables:
- shops
- items
- item_categories
- item_stocks
- categories
groups:
-
name: 店舗
desc: 店舗情報
tables:
- shops
-
name: 商品
desc: 商品情報
tables:
- items
- item_categories
- item_stocks
-
name: カテゴリマスタ
desc: カテゴリ情報
tables:
- categories
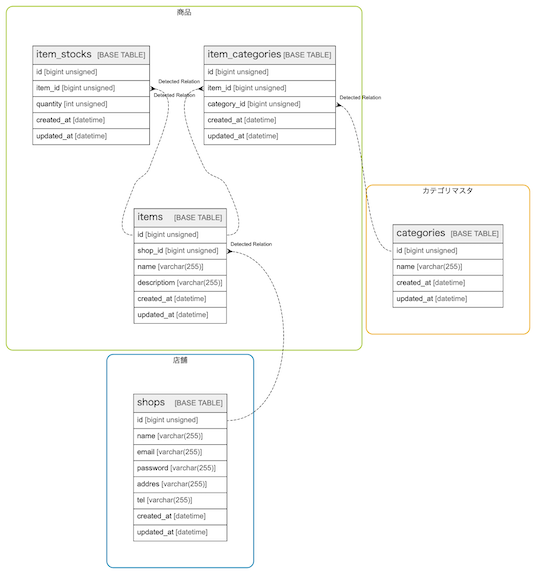
カテゴライズされてとても見やすくなりました。
viewpointの実例(プロダクト要求の関心で整理する)
今回tblsで整理したいと思っていたサンプルになります。今までの情報はデフォルトのERでも把握することにそこまでハードルが高くないと思います。(groupで見やすくなったくらい)
データ関連ベースではなくプロダクト要件に沿って異なるテーブル群をまとめることによって、機能の把握をすることが可能になりそうです。今回はデモにECを想定していますので、重要機能かつ機能追加が入りそうな購入者-発注の関係をまとめてみました。
viewpoints:
-
name: 決済処理
desc: >
決済処理の関連テーブル
tables:
- members
- orders
- order_items
- items
- item_stocks
- deliveries
- delivery_statuses
- delivery_status_histories
- purchase_statuses
- purchase_status_histories
groups:
-
name: 購入者
desc: 購入者情報
tables:
- members
-
name: 注文情報
desc: 注文情報
tables:
- orders
- order_items
-
name: 配送情報
desc: 配送情報
tables:
- deliveries
- delivery_statuses
- delivery_status_histories
-
name: 支払い情報
desc: 支払い情報
tables:
- purchase_statuses
- purchase_status_histories
-
name: 商品情報
desc: 商品情報
tables:
- items
- item_stocks
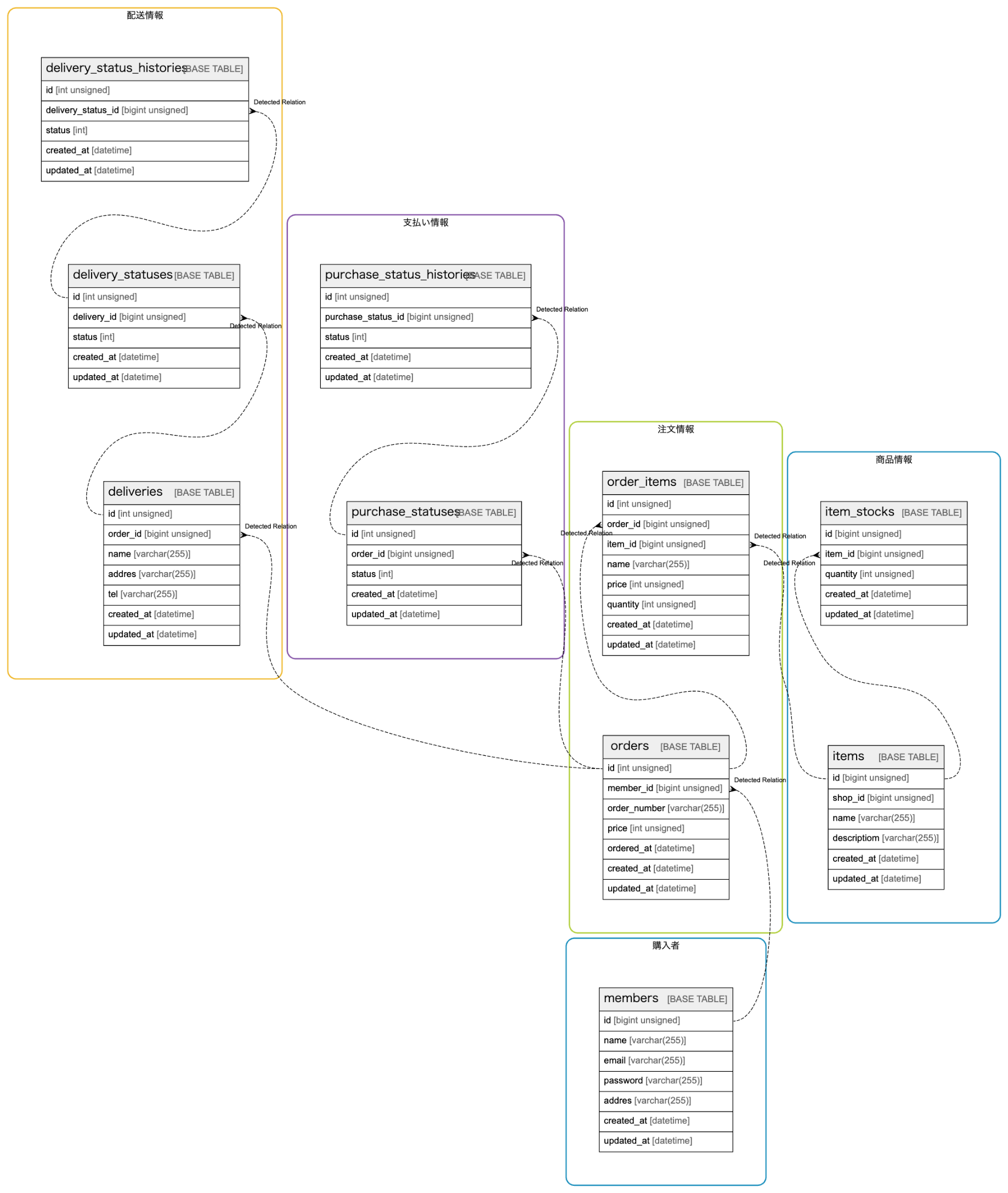
デモなのでシンプルなカテゴライズになってしまいましたが、これだけでも大分スッキリ出来ると思います。購入者は会員単位、注文情報の中に配送、支払い情報、注文数などで関心が分かれていることがわかります。複雑な処理に関する関係テーブルを整理するためには非常に有効だと思います。詳細情報なども書けるので、注意事項や関連リンクなどをまとめることができます。
まとめ
開発効率の話を進める上でドキュメント整理についての課題は多々あると思います。ドキュメント整理の難しさは形骸化してただの業務負担になるという事を避けないといけないことと、本当に意味のあるものなのかを判断していくところかなと思います。ドキュメントをちゃんと整備したいという思いが強いほどルール作成に意識が向くことも多いです。価値のある情報を的確に判断して、なるべく開発フローの中に自然とドキュメント作成作業が組み込まれている状態を作って行けたら良いなと考えています。
さいごに
今回の記事の取り組み以外でも、プロダクト開発・技術的課題解決などやりたいことがたくさんあります。 カジュアル面談歓迎です!少しでも興味を持っていただけたら是非ご連絡ください!
https://www.wantedly.com/companies/trustbank/projects
明日は、chiicaフルスタックエンジニアの @hiroumi_seino さんの記事です!お楽しみに!