はじめに
「Pythonで作るエラトステネスのふるい」という記事を遊びで書いたのですが、コメントで指摘をして頂いて改善をすることができました。そのコメントの中で
ちなみに data = list(range(2, n + 1)) とも書けますが、遅くなるようです。
と書かれていました。私もlistオブジェクトへのキャストの方が、内包表記で展開するよりも遅いだろうと思ったのですが、ちゃんと検証したことはなかったのでやってみるかぁっと思ってやってみたよって話です。
逆アセンブル
disモジュールを使うことで、CPythonバイトコードを逆アセンブルできるのでやってみました。
>>> from dis import dis
>>> def hoge():
... return [i for i in range(10)]
...
>>> dis(hoge)
2 0 LOAD_CONST 1 (<code object <listcomp> at 0x---------, file "<stdin>", line 2>)
2 LOAD_CONST 2 ('hoge.<locals>.<listcomp>')
4 MAKE_FUNCTION 0
6 LOAD_GLOBAL 0 (range)
8 LOAD_CONST 3 (10)
10 CALL_FUNCTION 1
12 GET_ITER
14 CALL_FUNCTION 1
16 RETURN_VALUE
>>> def foo():
... return list(range(10))
...
>>> dis(foo)
2 0 LOAD_GLOBAL 0 (list)
2 LOAD_GLOBAL 1 (range)
4 LOAD_CONST 1 (10)
6 CALL_FUNCTION 1
8 CALL_FUNCTION 1
10 RETURN_VALUE
※「0x---------」はメモリアドレスのため隠しています。
この結果、ステップ数はlist(range(10))の方が少ないことが分かりました。つまり、内方表記の方が早いという理解は間違っていたのかもしれないです。
実際に測定してみる
そこで、次のようなソースコードで検証を行いました。
# -* -coding:utf-8 -*-
import time
from dis import dis
import numpy as np
from matplotlib import pyplot as plt
def when_list(n):
return list(range(2, n + 1))
def when_inner(n):
return [i for i in range(2, n + 1)]
def measurement():
list_time = []
inner_time = []
count = []
for i in range(1, 100):
n = (i + 1) * 10
s_time = time.time()
when_list(n)
list_time.append(time.time() - s_time)
s_time = time.time()
when_inner(n)
inner_time.append(time.time() - s_time)
count.append(n)
plt.subplot(111)
plt.plot(np.array(count), np.array(list_time), label="list")
plt.plot(np.array(count), np.array(inner_time), label="inner")
leg = plt.legend(loc='best', ncol=2, mode="expand", shadow=True, fancybox=True)
leg.get_frame().set_alpha(0.5)
plt.show()
def main():
measurement()
if __name__ == '__main__':
main()
実証結果
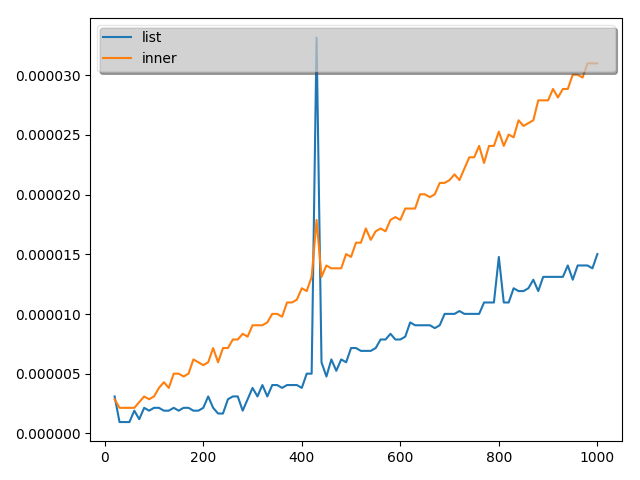
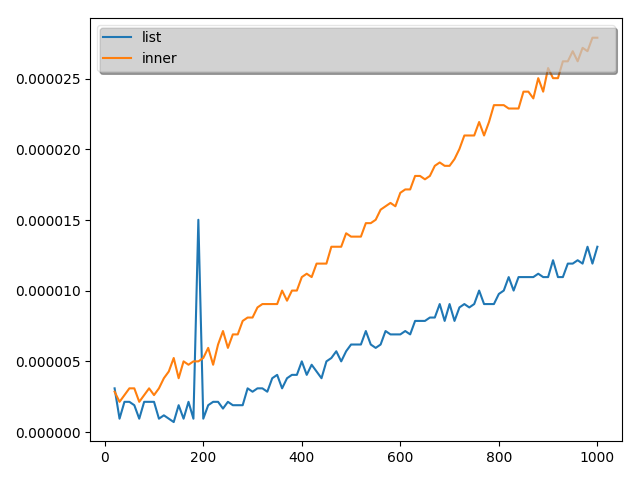
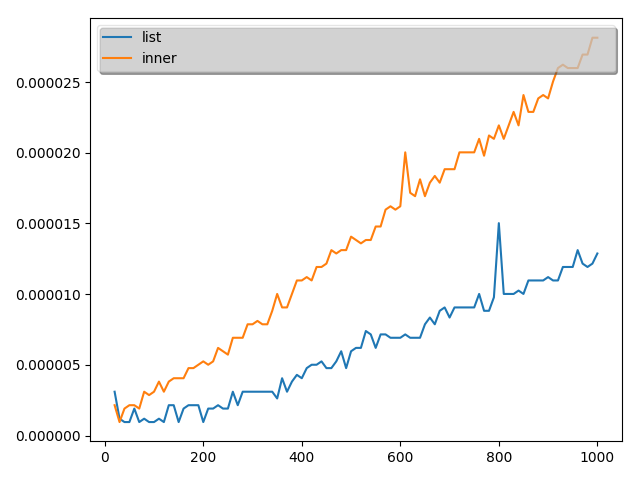
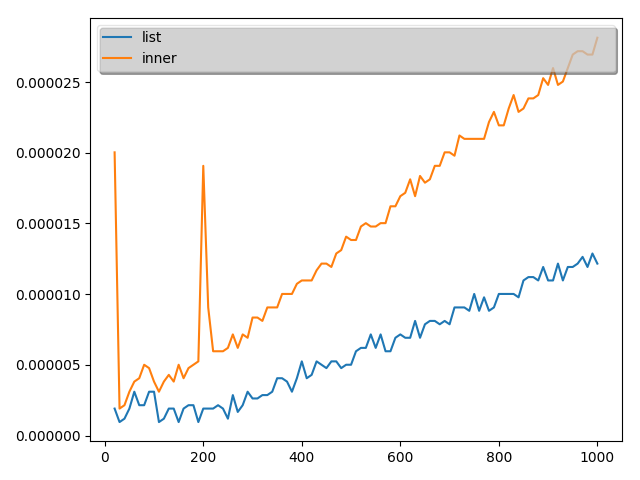
こちらの結果は次のようになりました。(10回とりました。)
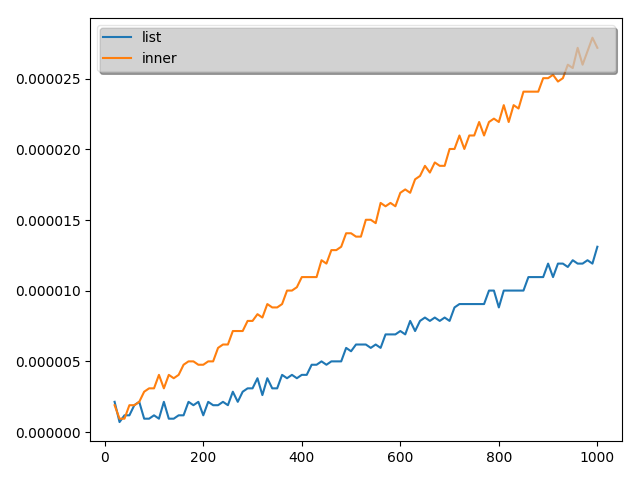
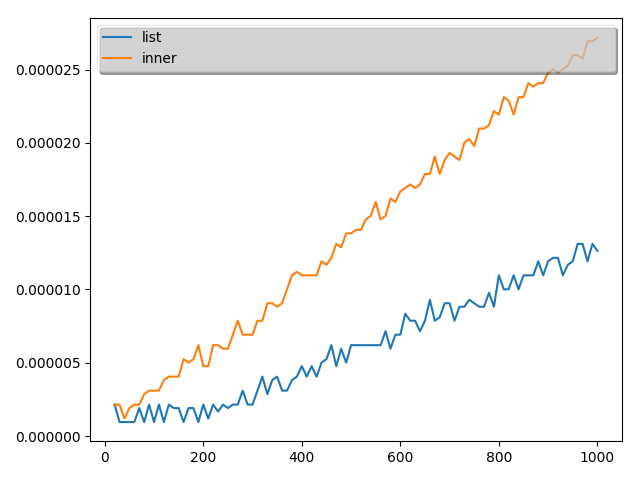
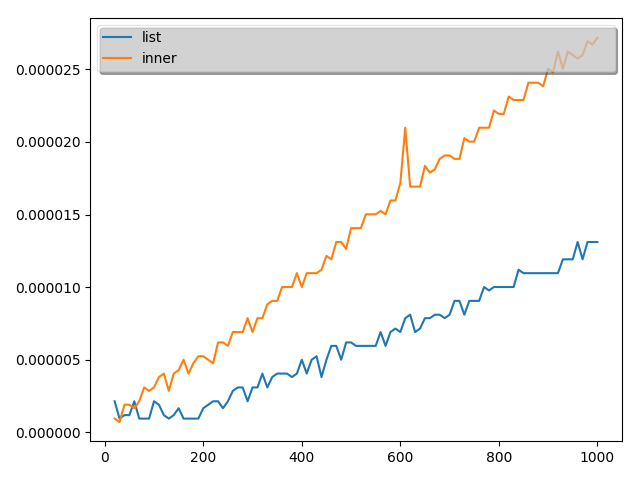
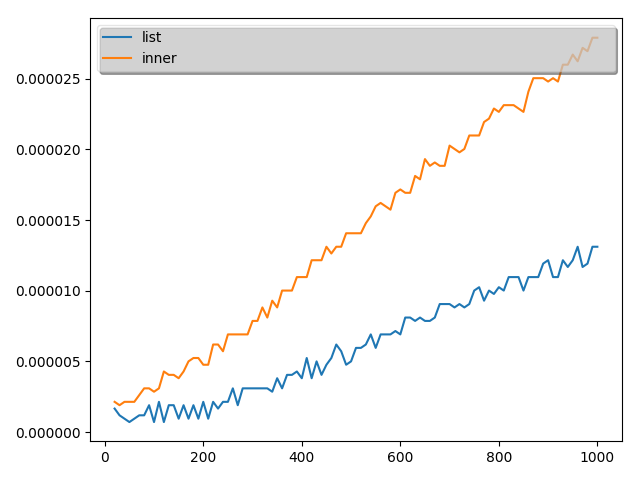
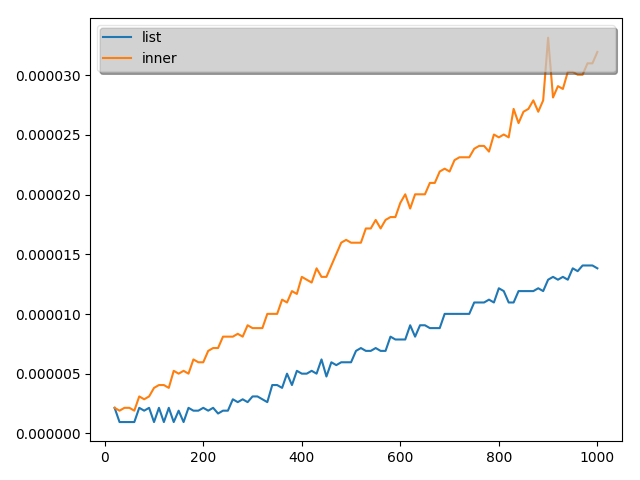
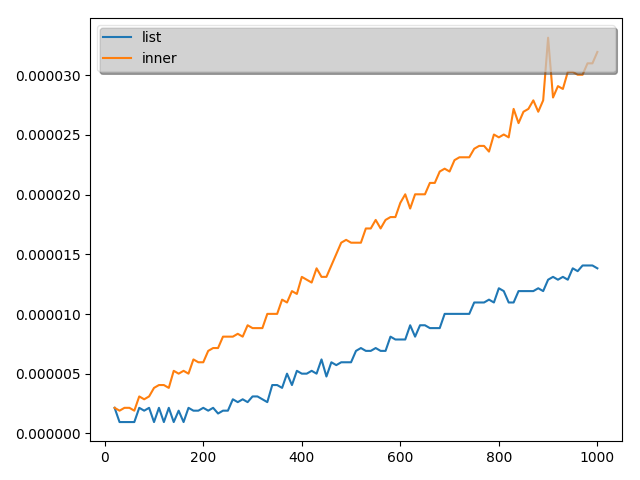
結論
実証結果から、最初の理解は誤りであることがことが分かりました。
ということで、本当に内包表記が常に早いわけではないことが分かりました。
ただし、time関数の測定精度が悪いので数値として内包表記がこれだけ遅いと言うのは難しいですが。