フューチャー Advent Calendar 2019 の24日目のエントリーです。
はじめに
皆さんは普段どの程度クラウドのマネージドサービスを利用してますでしょうか?
私は、AWSではDynamoDBやAmazon ES、GCPだとBigQueryやGKEを使っている人間です。
クラウドのマネージドサービスはとても便利ですし、アーキテクチャデザインの際に採用する方も多いかなと思います。
かくいう私もその1人ですが、マネージドな部分に完全におんぶに抱っこだと泣きを見るんだということを身をもって実感しました。
事前背景
Shared VPC構成下にて、GKEのPrivateクラスタを運用していました
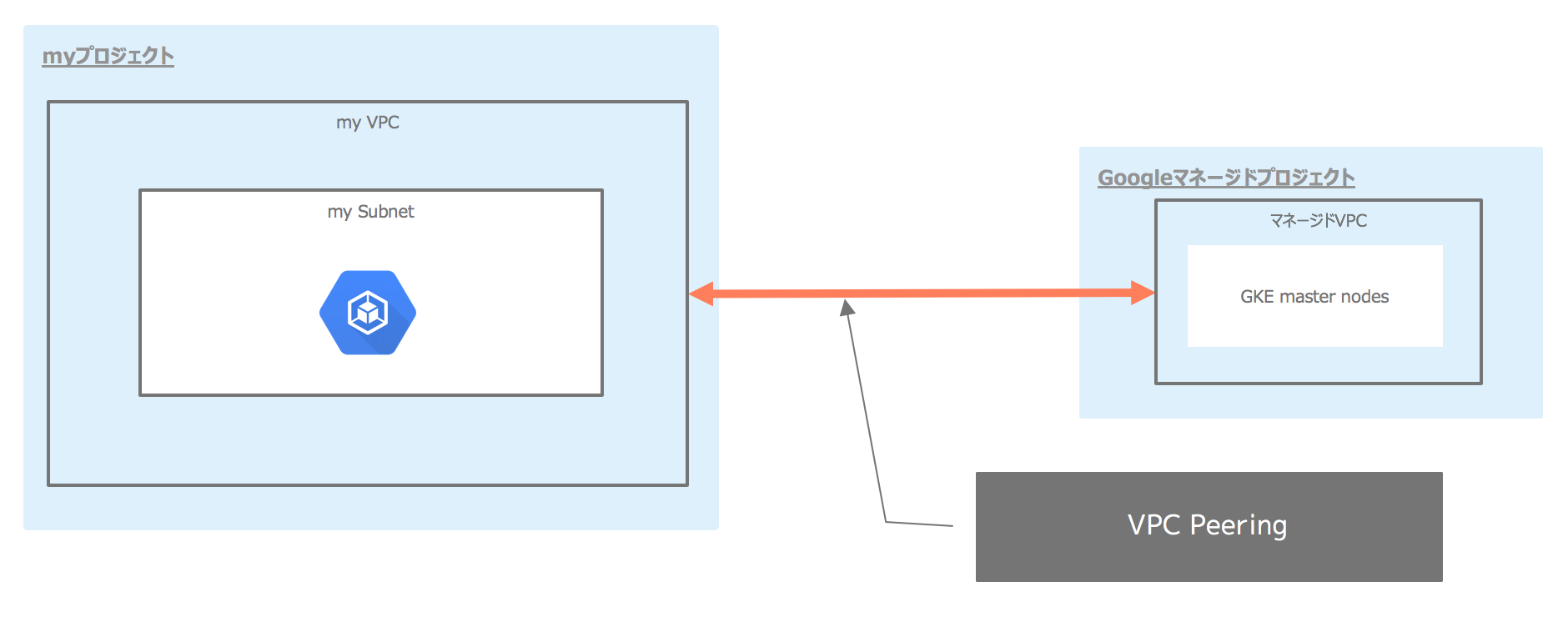
Privateクラスタを作成すると、Googleのマネージドプロジェクト上にGKE master nodeが出来上がり、VPC Peeringによって相互のVPCが接続されます。
Shared VPC構成をとっていたので、ホストプロジェクトには全てのサービスプロジェクト分のGKEクラスタ群のVPC Peeringが存在し、Peering本数はデフォルトのQuotaである25本に達する勢いでした。
私の過ち
VPC Peeringを全部削除しちゃいました。GUIから。ごっそりと。
VPC network peering のページには以下のような項目が存在します。
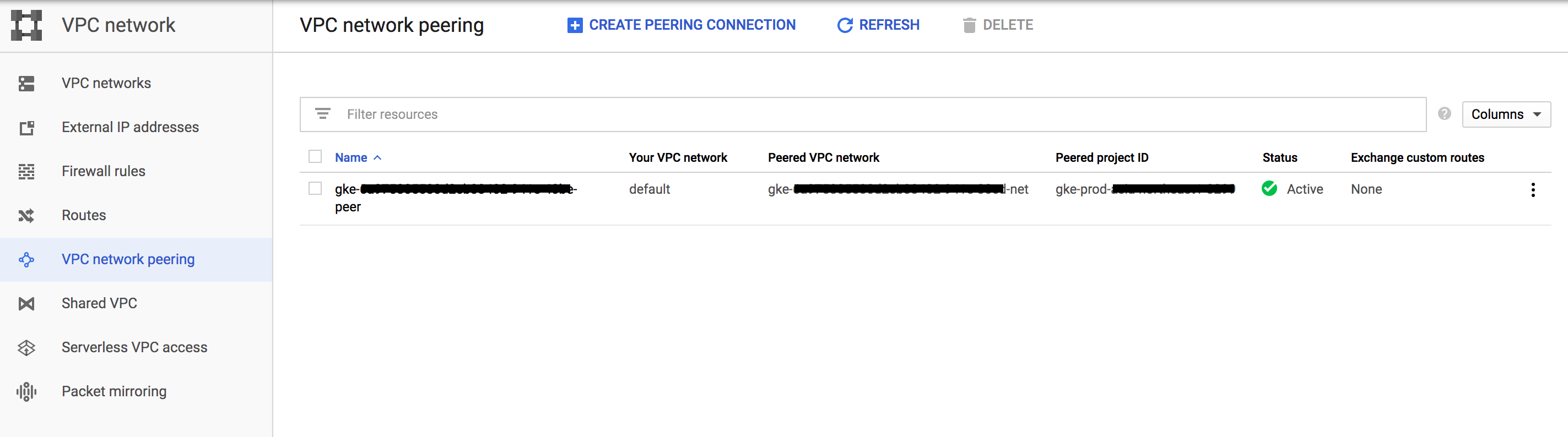
-
Name- VPC Peeringの名前
- 命名は
gke-xxx-peerの形
-
Your VPC network- Peering元のVPCネットワーク名
-
Peered VPC network- Peering先のVPCネットワーク名
- GCP側で勝手に作成されるVPCです
- 命名は
gke-xxx-netの形
-
Peered project ID- Peering先のVPCネットワークが所属するGCPプロジェクト名
- 命名は
gke-prod-xxxの形
今回私は Peered project ID の命名に対して大きな勘違いがあり、VPC Peeringの削除に至ってしまいました。
というのも、私が構築していたサービスプロジェクトの環境識別子のひとつがprodであり、gke-prod-xxxに登場するprodと何か関係があると思いこんでしまったのです。
例えば、dev環境であればgke-dev-xxxとなるはずでは、と考えてしまったのが事の発端でした。
prodという環境識別子のついた環境を再構築する任務を担っていた私は、Peered project IDがgke-prod-xxxとなっているVPC Peeringを全て、つまり開発・検証環境用のVPC Peeringも全て削除してしまいました。
いま思えばもう少し手前で立ち止まって考えれば分かったような気がしますが、チェックボックスにチェックを入れてDELETEボタンをポチっとするだけの簡単なお仕事は私をそこまでの思考に至らせるまでもなくVPC Peeringの全削除を完遂させてしまいました。
もちろん、焦る
焦りました。
GKE master nodeへの通信が遮断されたため、Kubernetes APIへのアクセスは完全に遮断され、kubectlコマンドは一切受け付けられない状態に陥っていました。
各環境を利用しているメンバーから「繋がらない」の声があがり、冷静にGKEのドキュメントを読み返しつつ、私の過ちが原因であることを完全に認識しました。
Private clusters have the following restrictions:
Deleting the VPC peering between the cluster master and the cluster nodes, deleting the firewall rules that allow ingress traffic from the cluster master to nodes on port 10250, or deleting the default route to the default internet gateway, causes a private cluster to stop functioning.
https://cloud.google.com/kubernetes-engine/docs/how-to/private-clusters
↑
読み返したドキュメントの抜粋です。書いてあるんです、しっかり。causes a private cluster to stop functioningって。
復旧の糸口を探す
クラスタ利用中のメンバーに状況連絡しつつ、復旧の糸口を探しました。
GoogleのSAの方に問い合わせしたところ、「VPCのauditログが残っていればそこから復旧できる」と教えて頂き、最終的にはその方法で復旧しました。
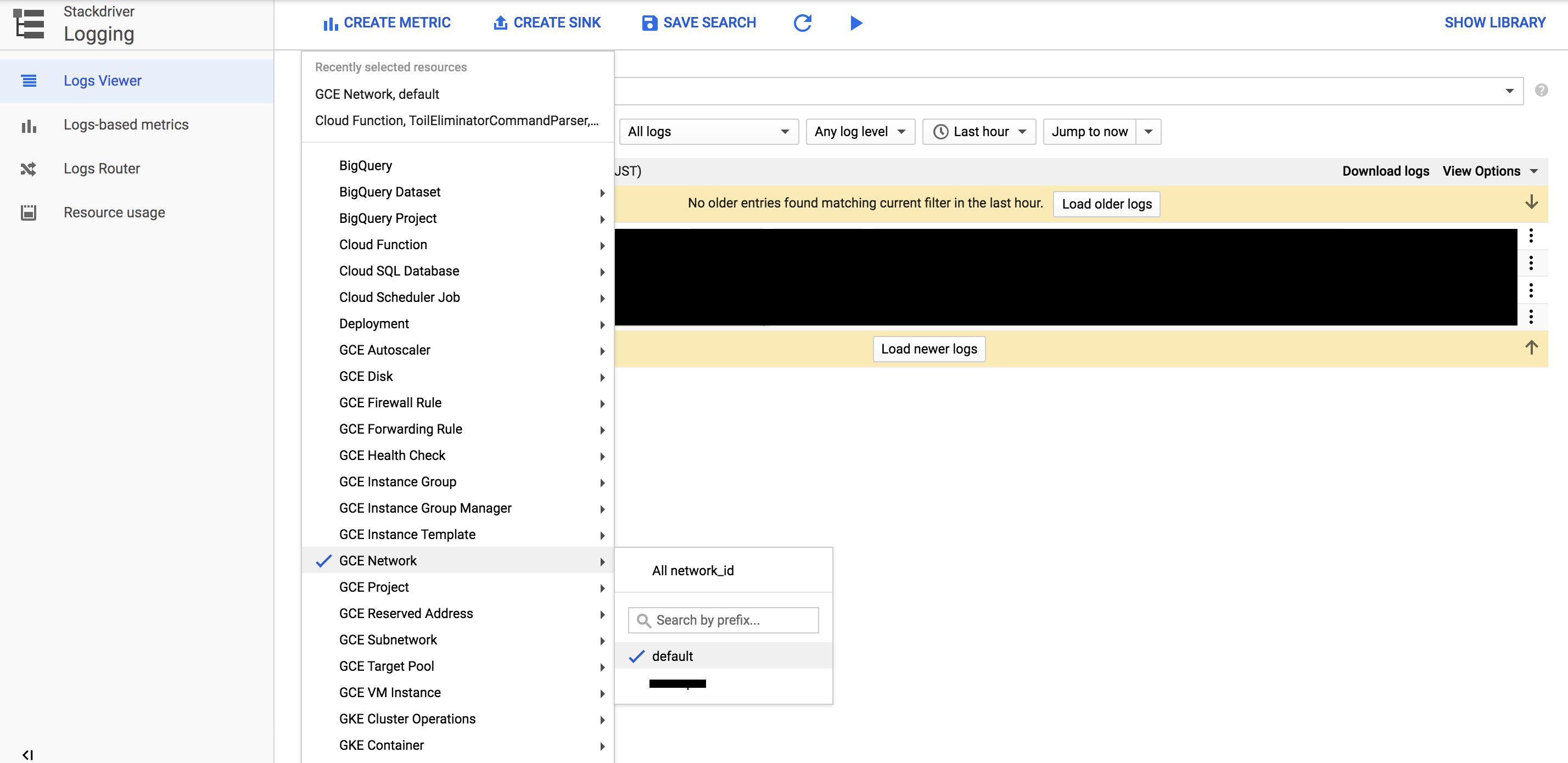
Stackdriver LoggingにてGCE Networkを選択し、利用しているVPCを選択すればPeering作成時のログを発見できます。
ログが大量にある場合はaddPeeringという文字列を含むログを検索すると良い感じに抽出できます。
{
...
protoPayload:{
request: {
@type: "type.googleapis.com/compute.networks.addPeering"
autoCreateRoutes: true
name: "gke-xxx-peer"
peerNetwork: "https://www.googleapis.com/compute/v1/projects/gke-prod-xxx/global/networks/gke-xxx-net"}
}
...
}
これはログの一部ですが、Name Peered VPC network Peered project IDの全ての情報がログに記載されていることが分かります。
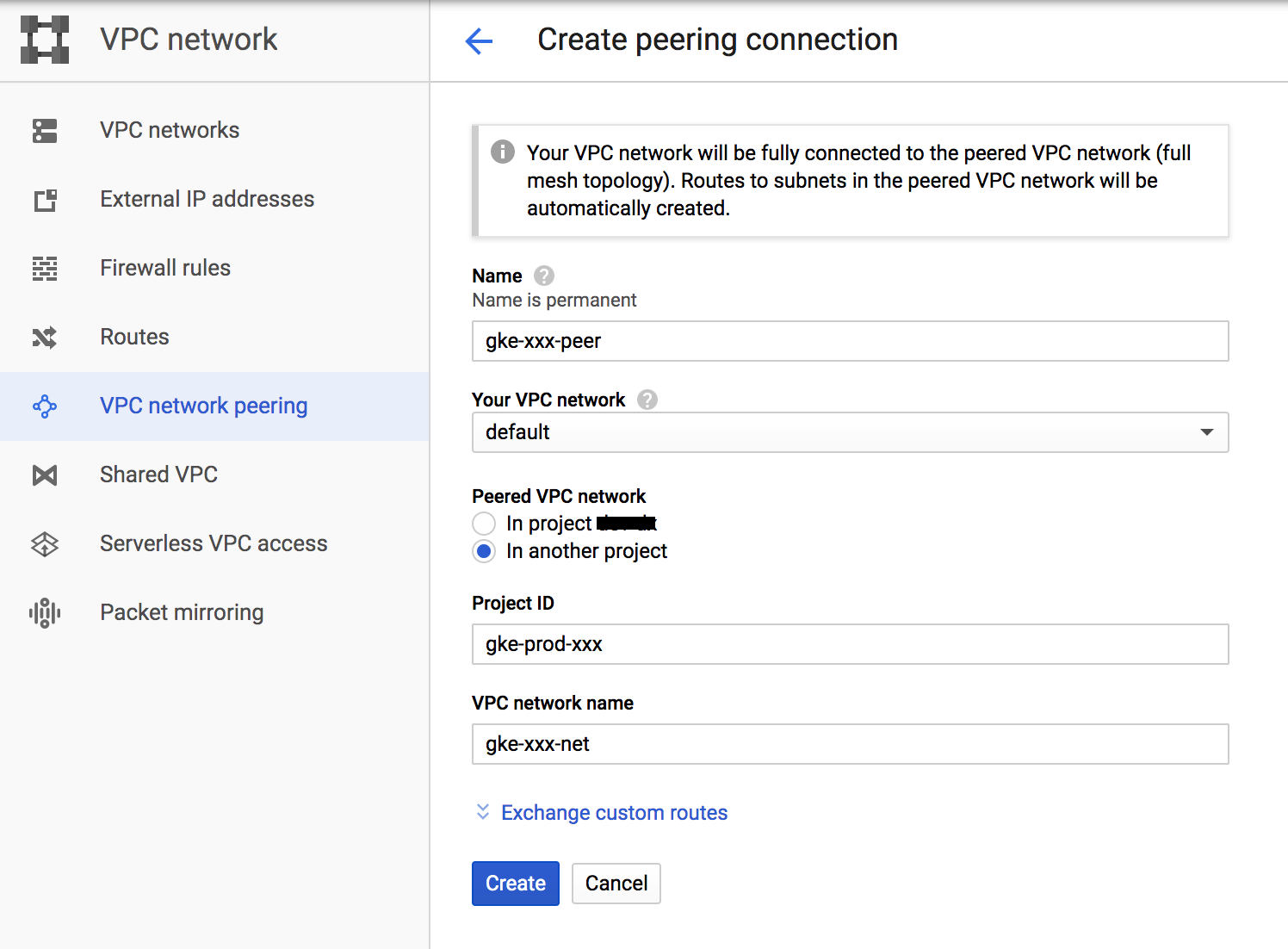
ログから確認した情報を元にVPC Peeringを再作成すれば復旧完了です。
もしもの時の運用を考えると、このVPC Peering作成に必要な情報はGKEのPrivateクラスタ作成時に控えておくのが堅いなと思いました。
学んだこと
- マネージドサービスのマネージドな部分はユーザに公開されていることもある
- その公開されているリソースを変更・削除すると最悪サービスとしての機能が停止してしまう
サービスの構成について理解し普段から各種リソースに意識して目を向けていれば、今回のような事態は起こらなかったはずだと強く思いました。
(gke-prod-xxxの命名が標準であることなんて普段からVPC Peeringを見ていれば自明だったはずですし...)
これは完全に私見なのですが、特にGCPはマネージドな部分の一端がユーザに公開されているケースが多い気がしています。
以前Cloud Functionを動かす際に、裏で利用されているIAMポリシーが削除されており正常に動作せずハマったというのがありました。(→GCPのIAMポリシー周りでドハマりした話)
まとめ
マネージドサービスはとても便利ですが、何がマネージされているかはしっかりと理解してなきゃいけないなと、当然ですが、改めて感じました。
引き続きマネージドサービスとはうまく付き合っていきたいなと思わされる2019年でした。
明日はAdvent Calendarラストです!!
ちょっと早いですが、皆さま良いお年をmm