この記事はなに?
3行でまとめるとこうだよ。
- Pythonの高速Webフレームワーク FastAPI に
- rinna株式会社が公開している日本語特化の事前学習済みモデル(計4.7GB)を載せて、
- 文章の空欄埋めや自動生成をできるDockerコンテナを Cloud Run で動かしてみた
学習済みモデルを2件まとめてDockerイメージ内に組み込むから、イメージサイズはかなり膨れ上がるよ。 モデルだけで4.7GB、他を合わせるとおよそ5GBのコンテナイメージになる。
だけど Google Cloud Run には「Dockerイメージのサイズが大きくても起動が早い」という強みがあるから、たとえDockerコンテナイメージのサイズが5GBを超える巨大なものだったとしても、ある程度まともな速度でコンテナを起動してくれるかもしれない...という(甘い)期待のもとにこの構成を試してみたよ。
▼ 参考
Cloud Run のコンテナ イメージ ストリーミング テクノロジーのため、コンテナ イメージのサイズは、コールド スタートやリクエストの処理時間に影響しません。また、コンテナ イメージのサイズは、コンテナの使用可能なメモリにはカウントされません。
はじめにFastAPIとrinna社の学習済みモデルについてのごく簡単な紹介をして、その後、実装の説明をしていくからね。
筆者プロフィール
Kenpal株式会社 でITエンジニアとして色々いじってる faable01 です。ものづくりが好きで、学生時代から創作仲間と小説を書いたりして楽しんでいたのですが、当時はその後自分がIT技術者になるとはつゆ程も思っていませんでした。紆余曲折あり、20代の半ばを過ぎた頃に初めてこの業界と出会った形です。
直近では個人として、22年9月10日からオンライン開催されていた技術書典13に出展し、Nuxt3 + TailwindCSS + AWS CDK に関する初学者向けの書籍を出したりしました。趣味は「技術記事を口語で書くこと」です。
それから、業務日報SaaS 「RevisNote」 を運営しています。リッチテキストでの日報と、短文SNS感のある分報を書けるのが特徴で、組織に所属する人数での従量課金制です。アカウント開設後すぐ使えて、無料プランもあるから、気軽にお試しください。
FastAPIについて
高パフォーマンスで使いやすいPython製のWebフレームワークだよ。
自動でSwaggerUI形式(あるいはReDoc形式)のドキュメントを生成してくれる機能があったりと、開発者に優しい上に性能も遜色ない(むしろ高い)フレームワークだから、使い所は幅広いはずだよ。
FastAPI は、Pythonの標準である型ヒントに基づいてPython 3.6 以降でAPI を構築するための、モダンで、高速(高パフォーマンス)な、Web フレームワークです。
今回は、この FastAPI のことはじめを兼ねて、FastAPIにrinna社の学習済みモデルを搭載して動かしてみるよ。
rinna株式会社が公開している事前学習済みモデルについて
AIりんなで知られる rinna株式会社 は、AIキャラクターサービスの研究・開発・提供を事業として行っていて、Hugging Face や GitHub 上で、さまざまな事前学習済みモデルを公開してくれているよ。
今回は、rinna社が公開するモデルのうち、自然言語処理に関する下記のモデルをFastAPIに組み込んで動かすよ。
さっそく実装する
python_fastapi_otameshi というディレクトリを作って、その中で作業するよ。
最終的には、次のようなファイル構成にするからね。
python_fastapi_otameshi
├── .devcontainer # 開発時のVSCodeリモートコンテナ用
│ └── devcontainer.json
├── .dockerignore # Dockerビルド対象外リソースを指定するファイル
├── .gitignore # git管理対象外リソースを指定するファイル
├── Dockerfile # Dockerイメージ構成ファイル
├── deploy.sh # GCPへのデプロイを行うシェルスクリプト
├── main.py # FastAPIのエントリーポイント
├── models # 学習済みモデル置き場
│ └── rinna
│ ├── japanese-gpt2-medium # rinna/japanese-gpt2-medium から git clone する
│ │ └── 略
│ └── japanese-roberta-base # rinna/japanese-roberta-base から git clone する
│ └── 略
├── requirements.txt # Pythonが必要とするパッケージを記述するファイル
├── routers # FastAPIのルートごとの実装ファイル置き場
│ ├── __init__.py
│ └── rinna
│ ├── __init__.py
│ ├── gpt2.py # rinna/japanese-gpt2-medium を動かすルート
│ └── roberta.py # rinna/japanese-roberta-base を動かすルート
└── setup_models.sh # 必要な学習済みモデルを git clone して配置するシェルスクリプト
あと、「記事はいいからコードだけ教えて」っていう人は、下記に今回の記事で書いたコードをまとめてるから、そっちを見るといいよ。
まずはサイズが大きくて時間のかかる学習済みモデルのダウンロードから始めようか
モデルのダウンロード
rinna社の rinna/japanese-roberta-base と rinna/japanese-gpt2-medium を Hugging Face からダウンロードするよ。
そのためにはいくつかの方法があるのだけれど、今回は説明の手っ取り早さから、シンプルにそれぞれのリポジトリを git clone して取得して配置するスクリプトを書くよ。スクリプトの内容は次の通りだからね。
#!/bin/bash
# このスクリプトを配置したディレクトリに移動
cd "$(dirname "$0")"
# ---- 前提 ----
# 学習済みモデルは基本的にサイズが大きく、100MBを超えるので git lfs が必要。
# なければ、Macなら brew install git-lfs などでインストールしておく。
git lfs install
# ---- rinna/japanese-roberta-base ----
mkdir -p models/rinna/japanese-roberta-base
git clone --depth 1 https://huggingface.co/rinna/japanese-roberta-base models/rinna/japanese-roberta-base
# ---- rinna/japanese-gpt2-medium ----
mkdir -p models/rinna/japanese-gpt2-medium
git clone --depth 1 https://huggingface.co/rinna/japanese-gpt2-medium models/rinna/japanese-gpt2-medium
# ---- 補足 ----
# 単に各モデルの最新版を利用したいだけなので、
# 上記で git clone コマンドに depth オプションに 1 を指定している。
#
# depthオプションは git clone 時に取得する履歴の数を指定するものであり、
# --depth 1 なら、最新の 1 件の履歴だけを取得する。
#
# このように --depth 1 でサイズを抑えた git clone のことを
# 一般に shallow clone と呼ばれている。
echo "Done."
スクリプトにある通り、学習済みモデルのサイズは中々に大きくて、通常のgitで扱えるサイズの上限であるところの100MBを超えてしまうよ。だから、サイズの大きなファイルをgitで扱うのに便利な git lfs を使って、学習済みモデルを git clone しているよ。
もし git lfs が自分のPCにインストールされていなければ、Macであれば brew install git-lfs などで先にインストールしておいてね。
setup.sh を書けたら、これを実行して models/rinna ディレクトリ配下にモデルがダウンロードされるのを待つ...のは時間が勿体無いから、その間に他の部分の実装を全部済ませちゃおうか (ちなみにこのスクリプトが完了するまでに、大体10GB程度の通信量がかかるから、WiMAXのような通信量に上限のある回線を使ってる人は気をつけてね)
まずは ignore系ファイルの定義からいくよ。
ignore系ファイルの定義
下記のignore系ファイルを作っていくよ。
- .gitignore
- .dockerignore
.gitignore は、学習済みモデルのディレクトリを管理対象外にしたいから、こうする。
__pycache__
.DS_Store
deploy.sh
models
.dockerignore は 学習済みモデルのディレクトリに存在する超巨大な .git ディレクトリがDockerイメージに含まれないようにしたいから、 こうする。
**/.git
**/__pycache__
ちなみに、もし .git ディレクトリを除外対象に指定せずにDockerイメージをビルドすると、 イメージサイズが4.7GBほど肥大化する から気をつけてね。
ignore系ファイルはこれだけ! 次はFastAPIを動かすための環境構築をするよ。
FastAPIを動かすための環境構築
まずは必要なパッケージの定義だね。FastAPIそのものはもちろんのこと、FastAPIを動かすためのUvicorn、それから学習済みモデルを動かすための各種パッケージが必要だから、requirements.txtは次のように定義するよ。
fastapi==0.85.1
uvicorn==0.19.0
torch==1.12.1
transformers==4.23.1
sentencepiece==0.1.97
VSCodeリモートコンテナ等を使わずにローカル環境でそのまま動作確認したい人なら、あとは、これを pip install するだけで環境構築はおしまいだよ(なお筆者のローカル環境はPython3.9で動作確認済み)。
だけど、ローカル環境を汚したくない人もいるだろうし、そもそも最終的に Cloud Run にデプロイするために必要だから、今のうちに Dockerfile の定義も行おうね。(ついでにVSCodeリモートコンテナ用の devcontainer.json も書くよ)
DockerfileはとりあえずPython3.9系列の適当な軽量イメージをもとに作っていくよ。こんな感じだね。
FROM python:3.9.15-slim-bullseye
RUN pip install --upgrade pip
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
EXPOSE 8080
ENV PYTHONUNBUFFERED True
# transformersをオフラインで使う前提なので TRANSFORMERS_OFFLINE で強制する
ENV TRANSFORMERS_OFFLINE=1
WORKDIR /app
COPY main.py .
# cp -rf routers . と同じ振る舞いをさせたい時に、例えば
# COPY routers .
# とすると、routersディレクトリの中身がカレントディレクトリに展開されるので、
# 期待と異なることに注意。
COPY routers/ ./routers/
COPY models/ ./models/
# uvicorn main:app --host 0.0.0.0 --port 8080
# ローカルで動作確認するなら --reload オプションをつけると便利。
# またコンテナを用いず動作確認するなら、環境変数の設定が必要なので、下記のように実行すると便利。
# TRANSFORMERS_OFFLINE=1 uvicorn main:app --host 0.0.0.0 --port 8080 --reload
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8080"]
Dockerfileはこれだけ! 今回はrinna社の学習済みモデルを使用するときに、自分でダウンロードしたモデルを使って動かしたいから、環境変数 TRANSFORMERS_OFFLINE に 1 を設定しているよ。
あとはVSCodeリモートコンテナ用の devcontainer.json だね。最低限の拡張機能だけを入れるとして、こんな感じにすればいいね。
{
"name": "python-fastapi-otameshi-dockerfile",
"context": "..",
"dockerFile": "../Dockerfile",
"extensions": [
"ms-python.python"
]
}
環境構築はこれくらいかな。以降は適宜好きな環境で作業してね。
次は実際に、FastAPIで学習済みモデルを動かすAPIを実装していくよ。
FastAPIで学習済みモデルを動かすAPIを実装する
FastAPIで動かす各ルートの実装から始めるよ。まずは rinna/japanese-roberta-base で 「マスクされた文字列の中身を予想する処理」 を実行するルートを作っていこうか。
「マスクされた文字列の中身を予測する」というのは、例えば 「4年に1度[MASK]は開かれる」 という文章を入力してやると、[MASK] に入るであろう文字列 ( オリンピック など) を予測して、出力してくれる処理のことだよ。
この処理のデモンストレーションは、Hugging Face 上でも試すことができるから、よかったら触ってみてね。
この「マスク文字列の予測処理」をFastAPIのルート /rinna/roberta に実装すると、こんな感じになるよ。
from pydoc import doc
from fastapi import APIRouter
from transformers import T5Tokenizer, RobertaForMaskedLM
import torch
import time
# ---- rinna/japanese-roberta-base ----
# https://huggingface.co/rinna/japanese-roberta-base
model_path = "models/rinna/japanese-roberta-base"
print(f"Loading {model_path}")
before = time.time()
tokenizer = T5Tokenizer.from_pretrained(model_path)
tokenizer.do_lower_case = True
model = RobertaForMaskedLM.from_pretrained(model_path)
after = time.time()
print(f"Loaded {model_path} in {round(after - before, 1)} seconds")
router = APIRouter()
@router.get("/rinna/roberta", tags=["rinna"])
def roberta(text: str):
"""
## 概要
引数の文字列に[MASK]があれば、その部分を予測する。
## 例
```sh
# http://localhost:8080/rinna/roberta?text=春になればそこかしこに[MASK]が咲きます。
curl --get --data-urlencode 'text=春になればそこかしこに[MASK]が咲きます。' http://localhost:8080/rinna/roberta
```
上記クエリで下記のような応答が返る。
```json
{"prediction_words":["桜","サクラ","梅","花","さくら","バラ","コスモス","ひまわり","椿"]}
```
"""
text = "[CLS]" + text
tokens = tokenizer.tokenize(text)
print("tokens:", tokens)
# [MASK]の位置を取得
masked_index = tokens.index("[MASK]")
token_ids = tokenizer.convert_tokens_to_ids(tokens)
token_tensor = torch.LongTensor([token_ids])
position_ids = list(range(0, token_tensor.size(1)))
position_id_tensor = torch.LongTensor([position_ids])
with torch.no_grad():
outputs = model(input_ids=token_tensor,
position_ids=position_id_tensor)
predictions = outputs[0][0, masked_index].topk(10)
# 予測結果を表示する。
# なおその際、下記をおこなっている。
# - 単語から "_" を除去する
# - 候補から "<unk>" を除外する
# - 重複を除去する
prediction_words = list(dict.fromkeys([
tokenizer.convert_ids_to_tokens([index_t.item()])[0].replace("▁", "")
for index_t in predictions.indices
if tokenizer.convert_ids_to_tokens([index_t.item()])[0] != "<unk>"
]))
return {"prediction_words": prediction_words}
マスクされた文字列の予測を行う /rinna/roberta ルートの実装はこんなところだね。DocStringを書いておけば、後でFastAPIを起動したときに、APIルートごとの仕様を /docs redoc などのルートで確認できるから便利だよ。
次は rinna/japanese-gpt2-medium で 「文章の続きを自動生成する処理」 を実行するルートを作っていくよ。
「文章の続きを自動生成する処理」というのは、例えば次のような入出力を行う処理を指すからね。
# 入力
生命、宇宙、そして万物についての究極の疑問の答えは
# 出力
生命、宇宙、そして万物についての究極の疑問の答えは私達の文化が人間という銀河系システムの中心に位置しており
その中で日々生きるということにあるのかもしれません。
この処理も、rinna/japanese-roberta-base と同様に Hugging Face上でデモンストレーションを試すことができるよ。(ただしこっちのモデルはサイズが大きくて、読み込み・実行ともに時間がかかるかも)
この「文章の続きを自動生成する処理」をFastAPIのルート /rinna/gpt2 に実装すると、こんな感じになるよ。
from fastapi import APIRouter
from transformers import T5Tokenizer, AutoModelForCausalLM
import time
# ---- rinna/japanese-gpt2-medium ----
# https://huggingface.co/rinna/japanese-gpt2-medium
model_path = "models/rinna/japanese-gpt2-medium"
print(f"Loading {model_path}")
before = time.time()
tokenizer = T5Tokenizer.from_pretrained(model_path)
tokenizer.do_lower_case = True
model = AutoModelForCausalLM.from_pretrained(model_path)
after = time.time()
print(f"Loaded {model_path} in {round(after - before, 1)} seconds")
router = APIRouter()
@router.get("/rinna/gpt2", tags=["rinna"])
def gpt2(text: str):
"""
## 概要
引数の文章の後に続く文章を予測する。
## 例
```sh
# http://localhost:8080/rinna/gpt2?text=春になればそこかしこに
curl --get --data-urlencode 'text=春になればそこかしこに' http://localhost:8080/rinna/gpt2
```
上記クエリで下記のような応答が返る。
```json
{"generated_text":"春になればそこかしこに綺麗な花を咲かせていますが、まだつぼみが多い季節なので その姿も華やかです。そんな春の陽気に誘われて行楽地にも出かけたくなるお天気に恵まれました"}
```
"""
# repetition_penaltyを設定して、ループせず最適な文章を出すようにする
input_ids = tokenizer.encode(text, return_tensors="pt")
outputs = model.generate(
input_ids, min_length=10, max_length=50,
repetition_penalty=2.0, do_sample=True,
top_k=400, top_p=0.95, num_return_sequences=3,
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id,
)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
return {"generated_text": generated_text}
文章の続きを自動生成するルート /rinna/gpt2 の実装はこんな感じだね。model.generate()の引数に渡すパラメータを変えてやると、色々と出力結果が変わるから、ここは好きなように調整してね。
学習済みモデルを動かすルートはこの2つだけだね! ここまでに実装した各ルートをエントリーポイントからimportしやすいように、各階層に __init__.py を作るよ。
from . import roberta
from . import gpt2
from . import rinna
最後にエントリーポイントを実装しよう。
import routers
from fastapi import FastAPI
from os import environ
# transformers をオフラインで使う前提
assert environ["TRANSFORMERS_OFFLINE"] == "1"
# 別ファイルに定義した各ルートを登録する。
# さらにFastAPIはデフォルトで、下記のドキュメントルートを生成してくれる。
# - /docs : Swagger UI 形式のドキュメント
# - /redoc : ReDoc 形式のドキュメント
app = FastAPI()
app.include_router(routers.rinna.roberta.router)
app.include_router(routers.rinna.gpt2.router)
これでFastAPIの実装は完了だね! 動作を確認したければ、プロジェクトのルートディレクトリ python_fastapi_otameshi で下記のコマンドを実行してね。
# なおVSCodeリモートコンテナ内で動作確認するなら環境変数TRANSFORMERS_OFFLINEは定義済みなので指定せずともOK
TRANSFORMERS_OFFLINE=1 uvicorn main:app --host 0.0.0.0 --port 8080 --reload
FastAPIが起動したら、次のようなURLで各ルートの動作確認ができるよ。
# http://localhost:8080/rinna/roberta?text=春になればそこかしこに[MASK]が咲きます。
{"prediction_words":["桜","サクラ","梅","花","さくら","バラ","コスモス","ひまわり","椿"]}
# http://localhost:8080/rinna/gpt2?text=春になればそこかしこに
{"generated_text":"春になればそこかしこに綺麗な花を咲かせていますが、まだつぼみが多い季節なので その姿も華やかです。そんな春の陽気に誘われて行楽地にも出かけたくなるお天気に恵まれました"}
FastAPIの実装と動作確認はここまでで完了だね。
最後に、ここまでに実装したFastAPIアプリケーションを、Dockerコンテナイメージとしてビルドして、GCPのコンテナ実行サービスであるところの Google Cloud Run にデプロイするよ(その過程で、GCPのイメージ管理サービス Google Container Registry (GCR) へのアップロードも行うからね)。
Google Cloud Run へのデプロイ(と、そのためのビルド&プッシュ)
コマンドを暗記しておくのも大変だから、ビルドとデプロイの工程をシェルスクリプトにまとめるよ。
今回はとりあえず動作を確認できる手軽さを優先して、Cloud Runへの未認証アクセスを許可するからね。一通りのコマンドをまとめると、こんな感じのシェルスクリプトになるよ。
#!/bin/bash
# このスクリプトを配置したディレクトリに移動
cd "$(dirname "$0")"
# 認証しないと後でDockerイメージをpusuするときに下記のエラーが出る
# - You don't have the needed permissions to perform this operation, and you may have invalid credentials.
gcloud auth configure-docker
GCP_PROJECT_ID='[自分のGCPのプロジェクトIDを指定してね]'
DOCKER_IMAGE_NAME='python-fastapi-otameshi'
VERSION='latest'
# キャッシュを使いたくなければ --no-cache オプションをつける
#
# また、使っているPCが M1Mac なら --platform linux/amd64 オプションをつけないと、
# CloudRun にアップロードしたときに下記のエラーが生じるはず
#
# ````
# terminated: Application failed to start: Failed to create init process: failed to load /usr/local/bin/uvicorn: exec format error
# ```
#
# 参考: https://stackoverflow.com/questions/66127933/cloud-run-failed-to-start-and-then-listen-on-the-port-defined-by-the-port-envi
docker build --platform linux/amd64 --tag asia.gcr.io/${GCP_PROJECT_ID}/${DOCKER_IMAGE_NAME}:${VERSION} .
docker push asia.gcr.io/${GCP_PROJECT_ID}/${DOCKER_IMAGE_NAME}:${VERSION}
gcloud iam service-accounts create pfo-account --project $GCP_PROJECT_ID
# 東京リージョンにデプロイする(未認証でのアクセスを許可)
gcloud run deploy python-fastapi-otameshi \
--image asia.gcr.io/${GCP_PROJECT_ID}/${DOCKER_IMAGE_NAME}:${VERSION} \
--service-account pfo-account \
--allow-unauthenticated \
--region=asia-northeast1 \
--cpu 2 \
--memory 8Gi \
--project $GCP_PROJECT_ID
スクリプト中のコメントにも書いたけど、筆者の使用PCはM1Macだから、docker buil時に --platform linux/amd64 を指定しているよ。この辺りは環境に応じて適宜書き換えてね。
あと、前提として GCP の各リソースについてCUIでの操作ができる gcloud CLI が必要だよ。もしもまだ自分のPCに gcloud CLI がインストールされていなければ、下記のページから自分の環境に合った gcloud CLI をインストールしておいてね。
スクリプトを実行して、次のように表示されたら Google Cloud Run へのデプロイは完了だよ。
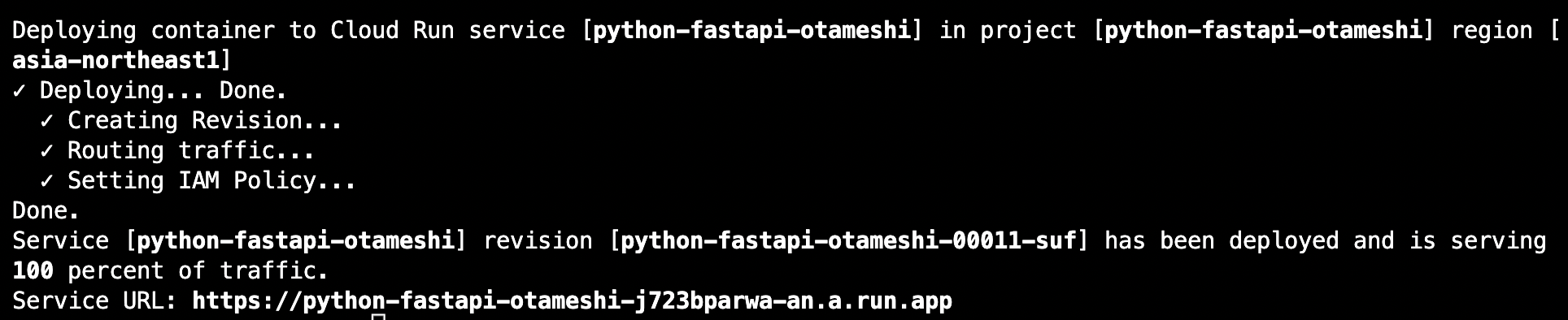
最後に表示されている Service URL が Cloud Run にデプロイしたアプリケーションのエンドポイントだよ。
(この記事を公開する前にリソースを削除してるから、これを読んでいる人が上記にアクセスしても404 Not Found にしかならないはずだけどね)
上記キャプチャだとエンドポイントが https://python-fastapi-otameshi-j723bparwa-an.a.run.app とのことだね。実際に動作するか試してみると、こんな感じだよ(特に意味はないけど、今度はターミナルからcurlコマンドで動作確認してみるよ)。
~ % curl --get --data-urlencode 'text=秋になれば駅前の通りは[MASK]で溢れます' https://python-fastapi-otameshi-j723bparwa-an.a.run.app/rinna/roberta
{"prediction_words":["観光客","コスモス","紅葉","自転車","人","チョコレート","女子高生","カメラマン","学生"]}
~ % curl --get --data-urlencode 'text=秋になれば駅前の通りは' https://python-fastapi-otameshi-j723bparwa-an.a.run.app/rinna/gpt2
{"generated_text":"秋になれば駅前の通りは見渡す限り花でいっぱいになるんですよ。 その大きな理由は、緑が多く新鮮な空気を含むことでしょうね!(笑) 高熱を出し続けてしまいこのままでは職場の方たちもきっと困ったことになる"}
無事に、マスク予測と文章生成のルート双方が動作していることが確認できたね。
なお、デプロイ直後は起動しているインスタンスが起動しているはずだからすぐ応答が返ってくるはずだけど、しばらく誰のアクセスも受けないと、Cloud Run はインスタンスを一旦アイドル状態に遷移させて、その後停止させるよ。
停止状態から新たにアクセスを受けるときには コンテナが立ち上がるまでのコールドスタートと、さらにそこからFastAPIそのもの起動の時間を要する から、今回の構成 (CPU 2, Memory 8GB で 5GBのイメージを動かす) だと大体 30秒 くらいかかるみたいだね。
(下記画像はGCPコンソールのCloud Runダッシュボードより)
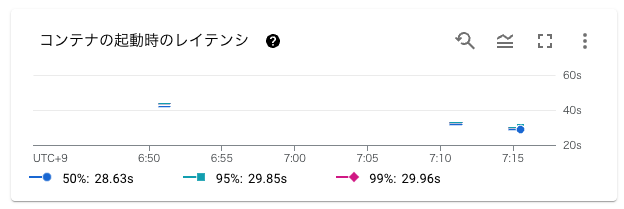
この記事の冒頭で、
Google Cloud Run には「Dockerイメージのサイズが大きくても起動が早い」という強みがあるから、たとえDockerコンテナイメージのサイズが5GBを超える巨大なものだったとしても、ある程度まともな速度でコンテナを起動してくれるはず...
と書いたけど、さすがに5GBを超える巨大なコンテナだと、ちょっと時間がかかるみたいだね。いくらコンテナそのものが迅速に立ち上がったとしても、FastAPIが読み込むべきリソースのサイズが大きすぎて時間がかかるという話なのだろうと推測しているよ。
もっと軽量なモデルなら事情は違うはずだから、業務でこの構成を使うなら、軽いモデルを使ったAPIを提供する場合がいいと思うよ。あるいは、常時コンテナを起動しておくタイプの運用にするのがいいだろうね。
(今回は記事執筆のしやすさから、2つの学習済みモデルを搭載した激重コンテナを作ったけど、単にイメージを軽くしたいなら、モデルごとに異なるイメージを作成して、実際に Cloud Run でもモデルごとに分割したアプリを提供するのが妥当だろうね)
まとめ
-
Pythonの高速Webフレームワーク FastAPI にrinna株式会社が公開している日本語特化の事前学習済みモデルを載せて、文章の空欄埋めや自動生成をできるDockerコンテナを Cloud Run で動かしてみたよ
-
rinna社はさまざまな学習済みモデルを公開していて、今回はその中から
rinna/japanese-roberta-baseで マスクされた文字列を予測するタスク を、rinna/japanese-gpt2-mediumで 文章の続きを生成するタスク を実行してみたよ -
Google Cloud Run はコンテナサイズが大きくてもコールドスタートが早いという特徴があるけど、今回のような5GB超あるコンテナイメージだと、FastAPIそのものの起動時間(正確にはFastAPIがモデルを読み込む時間)も要してしまうからか、さすがに起動には30秒程度かかったよ ( CPU 2, Memory 8GB で確認 )
-
もっと軽いコンテナ(正確にはより軽いモデルを組み込んだコンテナ)なら、より迅速に起動が完了してくれるはずだけど、今回のような規模のものを扱うなら、コンテナを分割したり、あるいはインスタンスを常時起動するタイプの運用にするのが妥当だと思うよ
※今回の記事で書いたコードは下記リポジトリにまとめてあります
余談
この記事を読んで同じ(もしくは類似の)構成での Cloud Run の検証を行った後、デプロイしたリソースが不要になったなら、ちゃんとそれらを消しておこうね。
特に、「Cloud Runはインスタンス停止中なら課金されないから大丈夫...」と安心して放置していると、 GCR(Google Container Registry) のイメージ保管で想定外の料金がかかってしまうはずだから気をつけよう。
(とはいえ単なるイメージ保管にかかる料金だけなら、22年10月現在は $0.023GB/月 なので、すぐに巨大な金額が請求されるわけではないよ。ただしGCRを利用したときにかかる料金は他にも存在するから、詳しくは下記ページから確認してね)
おまけ(FastAPIのドキュメントルートの紹介)
FastAPIには、自身に定義された各ルートの情報をドキュメントとして出力してくれるルートがデフォルトで用意されているよ!
具体的には、
-
/docsで SwaggerUI形式のドキュメント
-
/redocで ReDoc形式のドキュメント
という風にドキュメントを表示してくれるよ! 各ルートのDocStringもドキュメントに反映してくれたりと、何かと便利だよ。今回の実装ではさほどドキュメントのための記述を行なっていないけど、実務では便利なはずだから、よかったら使ってみてね。