はじめに
この記事で作ったプログラムをC#で作り直しました。

以下は元の制作記事です。
PDFファイル自動リネームツールについて
タイトル通りPDFのプロパティのタイトル名でPDFをリネームするアプリを作ってみました。
なおChatGPTにPythonプログラムは書かせてみました。
何に使うの?
課題:意味不明なファイル名
インターネットでマニュアルをダウンロードした場合、ファイル名がその会社の文書管理番号や略語になってる場合がよくあると思います。
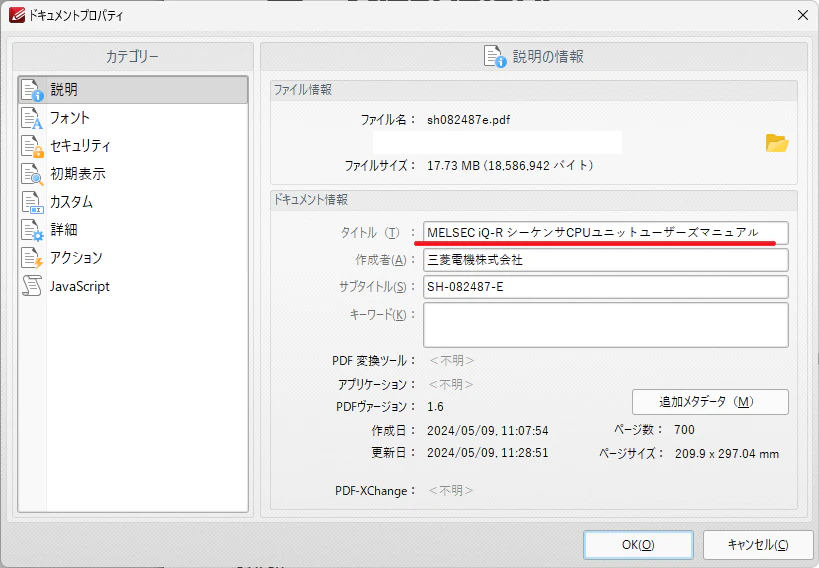
例えば下記のマニュアルをダウンロードすると [sh082487e.pdf] というファイル名になります。
このファイル名だと後で再び見るときにわからないですね。
[MELSEC iQ-R シーケンサCPUユニットユーザーズマニュアル] という名前にリネームしたいのですがこれを毎回手作業でするのは大変です。

解決方法:プロパティのタイトルを活用
ということでリネームを自動化するためにPDFのプロパティに含まれるタイトルをそのままPDFファイル名にリネームすれば楽できるのではと考えました。なおプロパティを見ているのでプロパティが空の場合や無題などになってる場合はあきらめて人力でリネームしましょう。
Python Program
基本版
pdf_rename.py
import os
import tkinter as tk
from tkinterdnd2 import TkinterDnD, DND_FILES
import PyPDF2
import unicodedata
import re
def extract_title_from_pdf(pdf_path):
try:
with open(pdf_path, 'rb') as f:
reader = PyPDF2.PdfReader(f)
if reader.is_encrypted:
try:
reader.decrypt('')
except Exception:
return None
title = reader.metadata.title
return title
except Exception:
return None
def convert_fullwidth_to_halfwidth(text):
return unicodedata.normalize('NFKC', text)
def rename_pdf_with_title(pdf_path):
title = extract_title_from_pdf(pdf_path)
if title:
# 全角英数字を半角に変換
title = convert_fullwidth_to_halfwidth(title)
# ファイル名に使えない文字を除去
valid_title = ''.join(c for c in title if c.isalnum() or c in (' ', '_', '-')).rstrip()
new_file_name = f"{valid_title}.pdf"
new_file_path = os.path.join(os.path.dirname(pdf_path), new_file_name)
os.rename(pdf_path, new_file_path)
return new_file_path
else:
return None
def drop(event):
data = event.data.strip()
print(f"Raw event data: {data}") # ログ出力
# 波括弧で囲まれたパスと囲まれていないパスを処理
file_paths = re.findall(r'\{([^}]+)\}|([^\s]+)', data)
# file_paths = [('E:/pdf_rename/aa/簡易説明書_ユニットカタログ/a.pdf', '')] のような形で返されるので、タプルから正しいパスを抽出
file_paths = [fp[0] or fp[1] for fp in file_paths]
print(f"Extracted file paths: {file_paths}") # ログ出力
results = []
for pdf_path in file_paths:
pdf_path = pdf_path.strip()
print(f"Processing file path: {pdf_path}") # ログ出力
if os.path.isfile(pdf_path):
new_pdf_path = rename_pdf_with_title(pdf_path)
if new_pdf_path:
results.append(f"'{os.path.basename(pdf_path)}' が '{os.path.basename(new_pdf_path)}' にリネームされました。")
else:
results.append(f"'{os.path.basename(pdf_path)}' のタイトル情報が見つかりませんでした。")
else:
results.append(f"'{pdf_path}' は有効なファイルパスではありません。")
result_label.config(text="\n".join(results))
root = TkinterDnD.Tk()
root.title("PDFタイトルをファイル名に反映")
root.geometry("600x400")
frame = tk.Frame(root)
frame.pack(expand=True, fill=tk.BOTH)
label = tk.Label(frame, text="ここにPDFファイルをドラッグ&ドロップしてください", pady=20)
label.pack()
result_label = tk.Label(frame, text="", justify=tk.LEFT, wraplength=580)
result_label.pack(pady=20)
root.drop_target_register(DND_FILES)
root.dnd_bind('<<Drop>>', drop)
root.mainloop()
必要なライブラリのインストール
必要ライブラリ
- PyPDF2 - PDFファイルの読み書きを行うためのライブラリ
- tkinterdnd2 - Tkinterでドラッグ&ドロップ機能を実現するためのライブラリ
- pycryptodome - 暗号化されたPDFファイルの読み取りに必要なライブラリ(PyPDF2で必要となる場合があります)
インストールコマンド
pip install PyPDF2 tkinterdnd2 pycryptodome
実行
実行方法
python pdf_rename.py
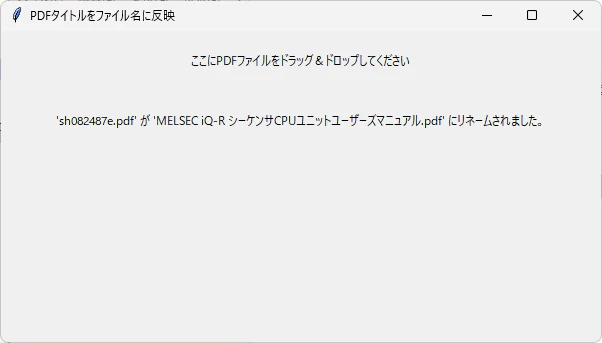
実行結果
やったね^^
機能
- 複数ファイルのDrag&Dropにも対応しています
- タイトル名がないときは実行されません
- なおWindows以外では未確認です

このプログラム作った時のプロンプト
ChatGPTとの格闘
まあ実際は何回もデバッグして作ったので2時間くらい格闘しました。
使用したプロンプト
PDFファイルのタイトル情報を読み取り、そのタイトルを元にPDFファイルをリネームするPythonプログラムを作成してください。このプログラムは次の要件を満たす必要があります:
1. **PyPDF2**ライブラリを使用してPDFファイルのタイトルを取得します。
2. 全角英数字を半角に変換します。
3. タイトル情報を元に、ファイル名を適切に変更します。ファイル名に使えない文字は除去します。
4. **tkinterdnd2**ライブラリを使用して、ドラッグ&ドロップでPDFファイルを指定できるようにします。
5. スペースや特殊文字を含むファイルパスも正しく処理できるようにします。
6. ファイルパスの取得と処理の各段階でログを出力し、デバッグを容易にします。
さらに、プログラムを実行するために必要なライブラリと、そのインストール方法も教えてください。
まとめ
判断が簡単でデータが大量にある場合はソフトを作らせることで作業を自動化できそうな感じですね。
その後の Python Program 改良版
ログ機能とファイル重複対応を追加
pdf_rename.py
import os
import tkinter as tk
from tkinterdnd2 import TkinterDnD, DND_FILES
import PyPDF2
import unicodedata
import re
LOG_FILE = os.path.join(os.path.dirname(__file__), 'rename_log.txt')
def log_message(message):
with open(LOG_FILE, 'a', encoding='utf-8') as log_file:
log_file.write(message + '\n')
print(message)
def extract_title_from_pdf(pdf_path):
try:
with open(pdf_path, 'rb') as f:
reader = PyPDF2.PdfReader(f)
if reader.is_encrypted:
try:
reader.decrypt('')
except Exception:
return None
title = reader.metadata.title
return title
except Exception:
return None
def convert_fullwidth_to_halfwidth(text):
return unicodedata.normalize('NFKC', text)
def rename_pdf_with_title(pdf_path):
title = extract_title_from_pdf(pdf_path)
if title:
# 全角英数字を半角に変換
title = convert_fullwidth_to_halfwidth(title)
# ファイル名に使えない文字を除去
valid_title = ''.join(c for c in title if c.isalnum() or c in (' ', '_', '-')).rstrip()
new_file_name = f"{valid_title}.pdf"
new_file_path = os.path.join(os.path.dirname(pdf_path), new_file_name)
# ファイル名が重複する場合は末尾に番号を付ける
if os.path.exists(new_file_path):
base, ext = os.path.splitext(new_file_path)
i = 1
while os.path.exists(new_file_path):
new_file_path = f"{base}({i}){ext}"
i += 1
os.rename(pdf_path, new_file_path)
return new_file_path
else:
return None
def drop(event):
data = event.data.strip()
log_message(f"Raw event data: {data}") # ログ出力
# ファイルパスを正しく分割
file_paths = re.findall(r'\{([^}]+)\}|\"([^\"]+)\"|([^\s]+)', data)
# 正しいファイルパスを抽出
file_paths = [fp[0] or fp[1] or fp[2] for fp in file_paths]
log_message(f"Extracted file paths: {file_paths}") # ログ出力
results = []
for pdf_path in file_paths:
pdf_path = pdf_path.strip()
log_message(f"Processing file path: {pdf_path}") # ログ出力
if os.path.isfile(pdf_path):
new_pdf_path = rename_pdf_with_title(pdf_path)
if new_pdf_path:
results.append(f"'{os.path.basename(pdf_path)}' が '{os.path.basename(new_pdf_path)}' にリネームされました。")
else:
results.append(f"'{os.path.basename(pdf_path)}' のタイトル情報が見つかりませんでした。")
else:
results.append(f"'{pdf_path}' は有効なファイルパスではありません。")
result_label.config(text="\n".join(results))
for result in results:
log_message(result)
def clear_logs():
result_label.config(text="")
open(LOG_FILE, 'w', encoding='utf-8').close() # ログファイルをクリア
root = TkinterDnD.Tk()
root.title("PDFタイトルをファイル名に反映")
root.geometry("600x400")
frame = tk.Frame(root)
frame.pack(expand=True, fill=tk.BOTH)
label = tk.Label(frame, text="ここにPDFファイルをドラッグ&ドロップしてください", pady=20)
label.pack()
result_label = tk.Label(frame, text="", justify=tk.LEFT, wraplength=580)
result_label.pack(pady=20)
clear_button = tk.Button(frame, text="ログをクリア", command=clear_logs)
clear_button.pack(pady=10)
root.drop_target_register(DND_FILES)
root.dnd_bind('<<Drop>>', drop)
root.mainloop()