この記事はZOZOテクノロジーズ #3 Advent Calendar 2020 8日目の記事です。
やりたいこと
最近業務でKubeflow Pipelinesを扱うことが増えてきているのですが、コンポーネント間のデータの扱い方を忘れてしまうことが多いのでタイトルの通り、Kubeflow Pipelinesにおけるデータの扱い方についてまとめます。
より具体的には以下のようなコンポーネントへの入出力ケースについてまとめます。
| No. | 入出力として扱うオブジェクト |
|---|---|
| 1 | 単一の文字列、数値 |
| 2 | 複数の文字列、数値 |
| 3 | csvファイル |
| 4 | joblibファイル |
| 5 | 関数などのオブジェクト |
前回の記事(Kubeflow Pipelinesにおけるコンポーネント間のデータ受け取り方・渡し方まとめ - その1)ではNo.1, 2について解説したので、そちらも併せてご覧ください。
本記事ではNo.3 ~ 5について解説します!
環境
前回と同様の環境です。
$ pip install kfp==1.0
$ pip show kfp
Name: kfp
Version: 1.0.0
Summary: KubeFlow Pipelines SDK
...
以下が事前に宣言されているものとしています。
from kfp.components import func_to_container_op
from kfp import dsl
# 以下をご自身のKubeflow Pipelinesの環境に置き換えてください
HOST = "https://your-kubeflow-pipelines-host"
今回の記事で記載しているコードは前回の記事と同様にコピペで動作確認ができます。
csvファイルを扱う
pandasのDataFrameを使い、以下のような処理の流れで処理を行います。
step 1. make_csvコンポーネントで適当なDataFrameを作る
step 2. csvファイルとして保存する
step 3. csvファイルのパスをread_csvコンポーネントに渡す
step 4. read_csvコンポーネントでcsvファイルのパスを読み、DataFrameをreadする
ひとまずコードを載せます。
from kfp.components import InputPath, OutputPath
@func_to_container_op
def make_csv(output_csv_path:OutputPath('CSV')):
import subprocess
subprocess.run(['pip', 'install', 'pandas'])
import pandas as pd
# step 1
df = pd.DataFrame(data=[[1,2,3],[3,4,5]],
columns=['col_a', 'col_b', 'col_c'],
index=['idx_1','idx_2'])
# step 2
df.to_csv(output_csv_path, index=True)
print(f'File path: {output_csv_path}')
@func_to_container_op
def read_csv(input_csv_path:InputPath('CSV')):
import subprocess
subprocess.run(['pip', 'install', 'pandas'])
import pandas as pd
# step 4
df = pd.read_csv(input_csv_path, index_col=0)
print(f'input_csv_path: {input_csv_path}')
print(f'type: {type(input_csv_path)}')
print(df.head())
@dsl.pipeline(name='Sample Pipeline')
def my_pipeline():
make_csv_task = make_csv()
# step 3
read_csv_task = read_csv(input_csv=make_csv_task.outputs['output_csv'])
kfp.Client(host=HOST).create_run_from_pipeline_func(my_pipeline, arguments={})
実行結果
make_csvのログ
File path: /tmp/outputs/output_csv/data
read_csvのログ
input_csv_path: /tmp/inputs/input_csv/data
type: <class 'str'>
col_a col_b col_c
idx_1 1 2 3
idx_2 3 4 5
ポイント解説
subprocessによる外部ライブラリのインストール
今回はDataFrameを扱うためにpandasを利用していますが、pandasはpythonの標準ライブラリではありません。
@func_to_container_opアノテーションは手軽にコンポーネントを作ることができますが、pandasやnumpyのような外部ライブラリを使用する場合は都度インストールする必要があります。
Dockerイメージを作る時に必要なrequirements.txtを用意するかわりに、このようなハードコーディングをしなければならないということです。
今回はサンプルを提示するために@func_to_container_opアノテーションでコンポーネントを作りましたが、依存する外部ライブラリが多い場合にはDockerイメージを作って管理するべきです。
OutputPathによるファイルパスの受け渡し
保存先の指定方法
make_csvコンポーネントのcsvの保存先としてoutput_csv_pathを指定しています。
しかし、コンポーネントを呼び出す際には保存先を明示していません。
@func_to_container_op
def make_csv(output_csv_path:OutputPath('CSV')):
...
# step 2
df.to_csv(output_csv_path, index=True)
print(f'File path: {output_csv_path}')
...
@dsl.pipeline(name='Sample Pipeline')
def my_pipeline():
make_csv_task = make_csv() # ここでファイルの保存先を渡していない
...
(前述のコードを一部抜粋)
Kubeflow PipelinesではOutputPathに対して暗黙的にファイルの保存先が指定されています。
その保存先というのが、ログで出力した/tmp/outputs/output_csv/dataとなっています。
出力の受け渡し方法
read_csvコンポーネントの入力としてmake_csvコンポーネントの出力を渡す際に、make_csvで宣言した変数名とは違うキー名になっていることに気付いたでしょうか。
@func_to_container_op
def make_csv(output_csv_path:OutputPath('CSV')):
...
# step 2
df.to_csv(output_csv_path, index=True)
print(f'File path: {output_csv_path}')
...
@dsl.pipeline(name='Sample Pipeline')
def my_pipeline():
make_csv_task = make_csv()
# step 3
# 参照するkey名がoutput_csv_pathではない
read_csv_task = read_csv(input_csv=make_csv_task.outputs['output_csv'])
...
make_csvコンポーネントではファイル出力先の変数としてoutput_csv_pathを使っていますが、出力を参照する際にはmake_csv_task.outputs['output_csv']となっており、_pathというsuffixが無くなっています。
このように、Kubeflow PipelinesではOutputPathの出力を渡す際に省略されるsuffixがいくつか存在します。
具体的には以下のsuffixを省略してキー名を参照します。
_file_path_file_path
例を挙げると、以下のようにキー名が変換されます。
-
csv_file_path→csv -
csv_file→csv -
csv_file_path_file_path→csv_file_path
このあたりの話はドキュメントには詳細に記載されていなかった(と思われる)ので、この仕様に気付くまでに時間がかかりました…。
InputPathによるファイルパスの受け取り
引数の指定方法
上記でOutputPathの例のように、InputPathでも同様のsuffixが省略されます。
read_csvでは引数名としてinput_csv_pathを使っていますが、read_csvに渡す引数名はinput_csvになります。
...
@func_to_container_op
def read_csv(input_csv_path:InputPath('CSV')):
import subprocess
subprocess.run(['pip', 'install', 'pandas'])
import pandas as pd
# step 4
df = pd.read_csv(input_csv_path, index_col=0)
...
@dsl.pipeline(name='Sample Pipeline')
def my_pipeline():
make_csv_task = make_csv()
# step 3
# input_csv_pathではない
read_csv_task = read_csv(input_csv=make_csv_task.outputs['output_csv'])
kfp.Client(host=HOST).create_run_from_pipeline_func(my_pipeline, arguments={})
joblibファイルを扱う
ここではjoblib形式としていますが、pickle形式でも何でも構いません。
セクションは分けましたが、結局はcsvファイルを扱う時と変わりありません。
@func_to_container_op
def make_joblib(output_joblib_file:OutputPath('joblib')):
import subprocess
subprocess.run(['pip', 'install', 'joblib'])
import joblib
with open(output_joblib_file, 'wb') as f:
joblib.dump(['a', 'b'], f)
print(f'File path: {output_joblib_file}')
@func_to_container_op
def read_joblib(input_joblib_path:InputPath('joblib')):
import subprocess
subprocess.run(['pip', 'install', 'joblib'])
import joblib
with open(input_joblib_path, 'rb') as f:
my_list = joblib.load(f)
print(my_list)
print(type(my_list))
@dsl.pipeline(name='Sample Pipeline')
def my_pipeline():
'''パイプライン本体'''
make_joblib_task = make_csv()
# 引数名がinput_joblib_pathではない & outputsのキー名がoutput_joblib_fileではない
read_joblib_task = read_joblib(input_joblib=make_joblib_task.outputs['output_joblib'])
kfp.Client(host=HOST).create_run_from_pipeline_func(my_pipeline, arguments={})
実行結果
make_joblibのログ
File path: /tmp/outputs/output_joblib/data
read_joblibのログ
['a', 'b']
<class 'list'>
関数などのオブジェクトを扱う
ここまででほとんどのデータ形式はカバーできましたが、関数やクラスなどのオブジェクトはどうでしょうか。
joblibやpickleなどの圧縮形式で保存できる関数やクラスはありますが、pickleなどでシリアライズできない場合、dillというライブラリを使うことでその問題を解消できるケースが多いと思われます。
またdillでもシリアライズできない場合として関数やクラスがグローバル変数を参照しているようなケースがありますが、この場合にはcloudpickleを使うことで解決できます。
参考: Pythonのシリアライズモジュール pickle marshal dill cloudpickle を比較する
関数をシリアライズするシチュエーションとして、各コンポーネントで共通した関数を使うような場合が考えられます。
基本的にコンポーネントはDockerイメージとして保存する必要があるため、「処理した結果をストレージに保存する」といったutilsとして使いたい機能をDockerイメージ内に別個のファイルとして保存する必要があります。
そこで、utilsとして使いたい関数をObjectとして渡すことによってこの問題を解決します。
以下では「受け取った値を二乗してreturn」という関数と「prefixを付け加えてreturn」という関数をコンポーネントに受け渡す例を記載します。
@func_to_container_op
def utils(square_path:OutputPath('function'),
add_prefix_path:OutputPath('function')):
# 受け取った値を二乗して返す
def square(val:int):
return val ** 2
# 受け取った値にhello_を付け加えて返す
def add_prefix(line:str):
prefix = 'hello_'
return prefix + line
import subprocess
subprocess.run(['pip', 'install', 'dill'])
import dill
with open(square_path, 'wb') as f:
dill.dump(square, f)
with open(add_prefix_path, 'wb') as f:
dill.dump(add_prefix, f)
@func_to_container_op
def comp(square_func_path:InputPath('function'),
ap_func_path:InputPath('function'),
val:int,
line:str):
import subprocess
subprocess.run(['pip', 'install', 'dill'])
import dill
with open(square_func_path, 'rb') as f:
square = dill.load(f)
with open(ap_func_path, 'rb') as f:
add_prefix = dill.load(f)
print(f'squared: {square(val)}')
print(f'add_prefix: {add_prefix(line)}')
@dsl.pipeline(name='Sample Pipeline')
def my_pipeline():
'''パイプライン本体'''
utils_task = utils()
task1 = comp(square_func=utils_task.outputs['square'],
ap_func=utils_task.outputs['add_prefix'],
val=11,
line='world')
task2 = comp(square_func=utils_task.outputs['square'],
ap_func=utils_task.outputs['add_prefix'],
val=22,
line='good_bye')
kfp.Client(host=HOST).create_run_from_pipeline_func(my_pipeline, arguments={})
実行結果
task1のログ
squared: 121
add_prefix: hello_world
task2のログ
squared: 484
add_prefix: hello_good_bye
出力されたDAG図
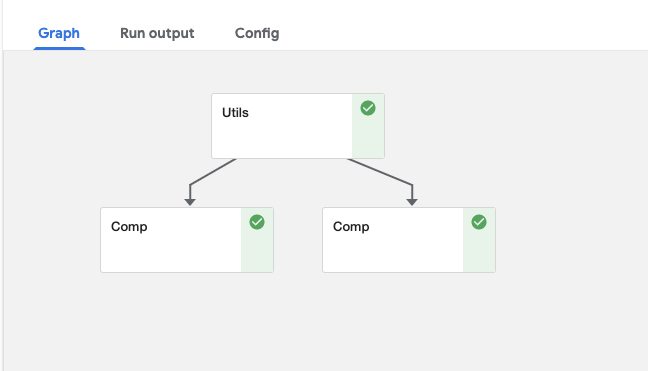
このようにutilsというコンポーネントを作り、その関数を各コンポーネントに渡すことで共通した関数を使い回すことができています。
が、この方法では関数を渡すコンポーネントが増えた場合にDAGがかなり見辛い状態となってしまうのが難点です。
(より良い方法をご存知であればコメント等で教えていただきたいです、、、)
おまけ
今回のサンプルではpythonの関数に@func_to_container_opアノテーションをつけてコンポーネントを組んでいました。
実際にパイプラインを作成する際には各処理を別個のpyファイルに記述し、各pyファイルをDockerイメージとして保存しコンポーネント化することが多いと思います。
コンポーネントはyamlファイルとして管理することになりますが、以下のようにコンポーネントの入出力を記述する必要があります。
name: Sample Component
description: This is a sample component.
inputs:
- name: project_name
description: "Project name."
type: String
- name: input_file_path
description: "Path to input file."
type: String
outputs:
- name: output_file_path
description: "Path to output file."
type: GCSPath
implementation:
container:
image: gcr.io/my-project/my-component:latest
command:
[
python,
/app/src/sample_component.py,
--project_name,
{ inputValue: project_name },
--input_file_path,
{ inputPath: input_file_path },
--output_file_path,
{ outputPath: output_file_path },
]
書いてあることはコンポーネントで起動するDockerイメージのパスとコンテナの起動コマンドですが、コンポーネントを作るたびにこのファイルを書くのは面倒くさいですね。
これを自動的に生成してくれる**create_component_from_func**という関数があります。
from kfp.components import OutputPath, create_component_from_func
def utils(square_path:OutputPath('function'),
add_prefix_path:OutputPath('function')):
def square(val:int):
return val ** 2
def add_prefix(line:str):
prefix = 'hello_'
return prefix + line
with open(square_path, 'wb') as f:
dill.dump(square, f)
with open(add_prefix_path, 'wb') as f:
dill.dump(add_prefix, f)
if __name__ == '__main__':
# 以下の関数でcomponent.yamlを自動生成
create_component_from_func(
utils,
output_component_file='component.yaml',
base_image='python:3.7',
packages_to_install=[
'dill',
]
)
第一引数にcomponent化したい関数を設定しbase_imageでイメージを指定、packages_to_installでインストールしたいパッケージを指定するだけです。便利。
まとめ
今回は以下の形式をコンポーネント間で受け渡す方法について見てきました。
- csvファイル
- joblibファイル
- 関数などのオブジェクト
キモとなるのはInputPathとOutputPathの取り扱いで、暗黙的に処理される部分が多いことがわかったかと思います。
業務ではこのようなファイル形式を扱うことが多いため、これからKubeflow Pipelinesを使う方の役に立てれば幸いです。
今回紹介した方法以外により良い方法をご存知の方がいればコメント等でお知らせください!