これから数回の記事に分けて、シンプルな(JavaScriptを伴わない)Webページをスクレイピングしてテキストデータと画像データの収集を行います。
すべての記事を読めば以下のことが理解できるようなものにする予定です。
- スクレイピングをするにあたりどんな順番で何をすべきか
- Scrapyがどういう原理で動作するのか
- Scrapyを使ったシンプルなWebページのスクレイピング方法
- 画像ファイルの収集方法
- 収集した情報ををデータベースに登録する方法
この記事では、事前準備としてスクレイピングの実行可否を判断するまでにどん手順を踏むかをまとめています。
スクレイピングが初めてではない方にとってはあまり参考になる情報はないかもしれません。
具体的にScrapyを使うのは次回以降の記事になります。
スクレイピングの注意事項の理解
いきなり水を差すようではありますが、まず最初にWebスクレピングを行うことはノーリスクではないということを理解しましょう。
ルールの範囲内でWebスクレイピングを行う権利は法律でも認められていますが、それを逸脱してしまうと、多くの方々に迷惑をかけたり、場合によってはご自身に法的リスクが降りかかったりする恐れがあります。
プログラミングミスなどで意図せずにそうなってしまった場合でも、実装者の責任が問われる可能性があります。
そういった危険があるということを承知した上で何かあったときに自己責任を取れる方でなければ、Webスクレイピングはおすすめしません。
ここでは簡単なごく一部のことにだけ触れておきます。
不安な方はググればたくさんの情報が見つかりますのでぜひご確認ください。
- 法律を守る
- 収集したデータは著作権法で認められている範囲で利用する(著作権法)
- 個人を特定できるような情報を収集しない(個人情報保護法)
- アクセス先サーバーに負荷をかけて提供サービスに影響を与えない(刑法 偽計業務妨害罪 など)
- アクセス先サイトのスクレイピングに対する姿勢を尊重する
- 利用規約などでスクレイピングが禁止されているのであれば行わない
- robots.txt、robots metaタグなどで禁止されている行為は行わない
- スクレイピングを行うプログラムを実行する際には慎重を期す
- 最低限の設定を必ず行う(クロール間隔時間、最大接続数など)
- 段階的に正常動作することを確認しながら少しずつ規模を拡大する
- エラーハンドリングをきちんと実装する
収集する情報の決定
と言うわけで、この記事のスクレイピング対象自体は何でもよいですので、**【猫の写真の画像データおよび写真撮影情報の収集】**を行うことにします。
スクレイピング対象サイトの選定
サイト候補の検索
とりあえず「猫写真」でググると以下のような結果になりました。
猫がかわいいですね。
上位2件にPixabayとPHOTOHITOがヒットしましたので、どちらかのサイトで目標が達成できそうかどうか調査していきましょう。
収集したい情報があるかどうかの確認
何はともあれ、収集したい情報がそのサイト内にないのであればスクレイピングする意味がありません。
実際に各サイトを見てみましょう。
Pixabay
Google検索結果リンク
Google検索結果のページを開くと猫の写真がたくさん出てきました。
一枚目の写真をクリックして表示されるページには、写真画像と撮影情報があります。
他の写真も何枚かクリックしてみて、同様の情報があることがわかりました。
PHOTOHITO
Google検索結果リンク
こちらのサイトでも何枚か写真をクリックしてみると、Pixabayと同じようなデータがありました。
いずれのサイトでも、各写真の詳細ページをスクレイピングすればほしい情報が収集できそうです。
スクレイピングが禁止されていないかどうかの確認
ほしい情報がそこに存在することはわかりましたので、次にそのサイトでスクレイピングが禁止されていないかどうかを調べます。
以下のことを行うとよいでしょう。
- 当該サイト内にスクレイピング禁止の旨が書かれていないかどうかを調べる
- 利用規約、サービス規約、ご利用ガイド、Q&A、FAQ、など
- サイト内ページの全検索機能があれば、「スクレイピング」「scraping」などの単語を検索する
- 「(サービス名) スクレイピング scraping」でググる
- 世の中にすでにそのサイトのことを調べていたり、スクレイピングしていたりする人がいれば参考になるかもしれない
Pixabay
サービス規約内に以下の記述がありましたので、スクレイピングはしない方がいいでしょう。
In connection with your use of the Service you must not engage in or use any data mining, robots, scraping or similar data gathering or extraction methods
(Google翻訳:本サービスの使用に関連して、データマイニング、ロボット、スクレイピング、または同様のデータ収集または抽出方法に従事または使用してはなりません。)
PHOTOHITO
スクレイピングへの言及は見つかりませんでしたので、禁止されてはいないようです。
以降はPHOTOHITOに絞って調査を続けます。
robots.txtの確認
robots.txtとは、サイト管理者がクローラーに対してどのページをクロールしてほしいか(してほしくないか)を指示するためのテキストファイルです。
内容によってはここでスクレイピングをあきらめなければなりません。
以下の点を確認していきます。
- そもそもrobots.txtが存在しているか
- サイト内でクロールが禁止されているパス
robots.txtの存在確認
robots.txtは必ずホストの最上位ディレクトリに配置されています。
PHOTOHITOのrobots.txtを確認するには、Webブラウザーから以下のURLにアクセスしてください。
https://photohito.com/robots.txt
User-Agent: *
Sitemap: http://photohito.com/smp/sitemap_index.xml
Disallow: /ajax
Disallow: /cgm
Disallow: /photo/check/
Disallow: /photo/upload/default/
Disallow: /user/notice/
Disallow: /search/photo/
Disallow: /photo/orgshow/
Disallow: /contact/violation/
Disallow: /contact/differene/
Disallow: /gallery/
(中略)
Disallow: /dictionary/slideshow/*/
Disallow: /dictionary/brotherList/*/
Disallow: /dictionary/childList/*/
ファイルが存在しました。
この指示に従うようにしましょう。
もし存在してなかった場合には、すべてのページのクロールが許可されているとみなすことができます。
クロールが禁止されているパスの確認
PHOTOHITOのrobots.txtはDisallowディレクティブ(クロール禁止パス)が並んでいるだけのシンプルな内容です。
多くのパスが禁止されていますのでほしい情報が収集できるかどうかはまだわかりません。
/gallary/以下のクロールが禁止されていますので、もし画像データがここに配置されていたら困ってしまいます。
以降の手順で具体的に調査していきます。
スクレイピング処理が実装が可能かどうかの感覚的な判断
この手順では大まかに以下のことを確認します。
- Webブラウザーで実際にサイトをブラウズして目的の情報があるページまでたどり着く
- そのURLのクロールが禁止されていないかを確認する
- HTMLのツリー構造を解析して、収集したい情報を抽出するためのパターンを見つける
- HTML要素を抽出するためのXPathまたはCSSセレクターが書けそうかを考える
写真の一覧ページ
Google検索結果に出てきた下記ページにアクセスしてみましょう。
https://photohito.com/dictionary/%E7%8C%AB/
このURLのクロールはrobots.txtで禁止されてはいません。
(Googleがクロールしているからこそ検索に引っかかるので当然ですが)
写真の詳細ページへのリンクの調査
このページには写真が一覧表示されていて、それらが各写真の詳細ページへのリンクになっています。
後々スクレイピングするときには、これらのリンクを上から順に1つずつたどっていくのがいいでしょう。
HTML上でどのようになっているのかを確認しておきます。
主要なWebブラウザーにはWebページ開発者用の解析ツールが用意されていますのでそれを使います。
ここではGoogle Chromeの例を紹介します。
確認したい要素(今回は1枚目の写真)を右クリックすると下記メニューが出ますので「検証」を選びます。
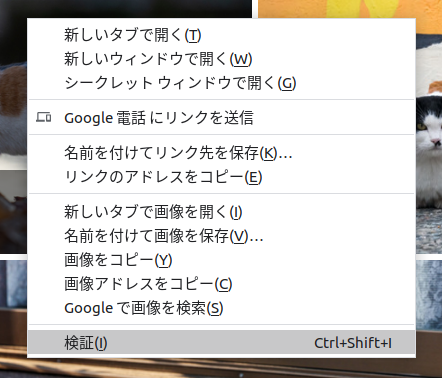
するとブラウザー内に下記のような開発者ツールが表示され、右クリックした要素が選択されている状態になります。
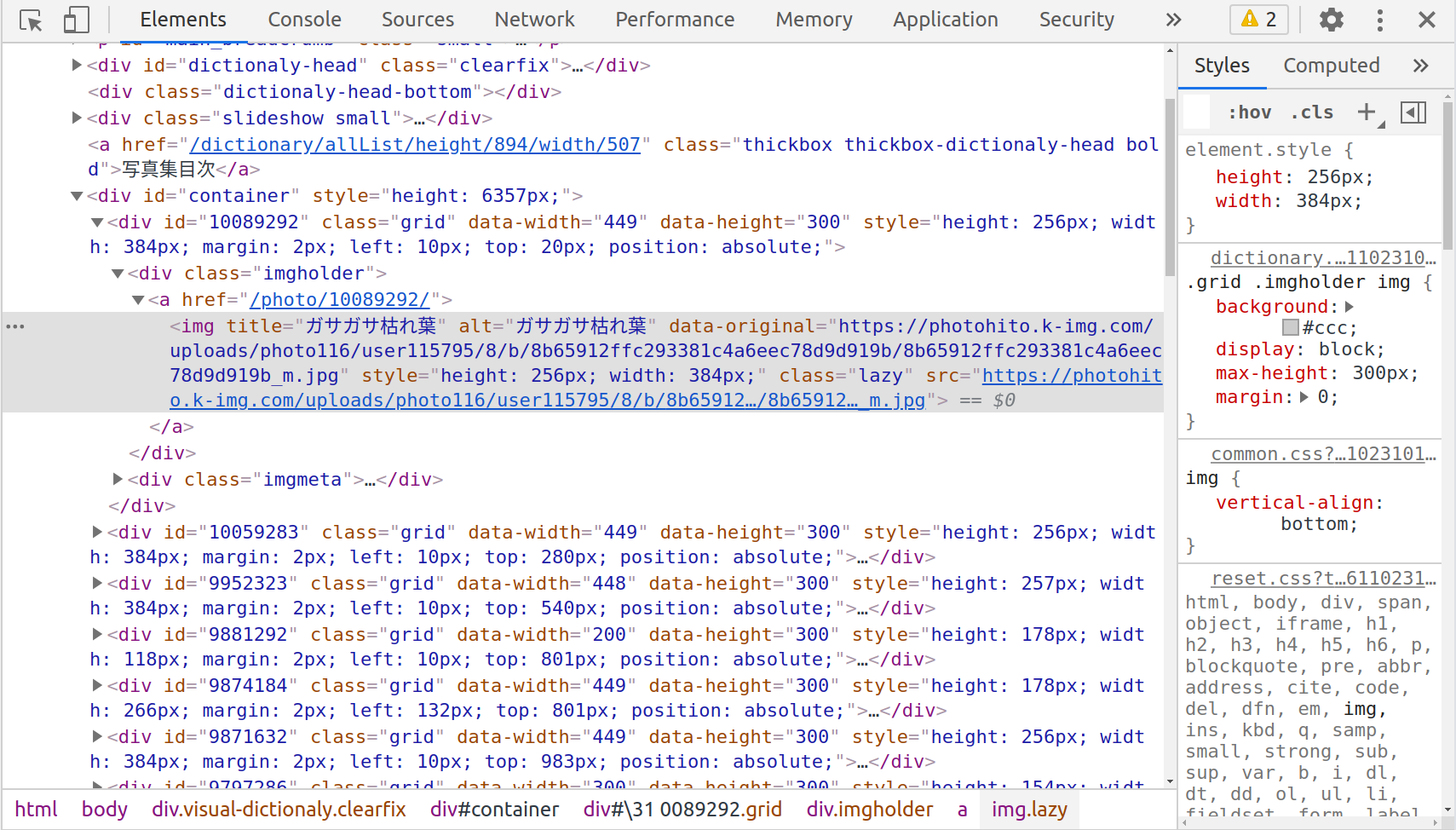
その付近をよく観察すると以下のようなパターンが見えます。
- 写真をクリックしたときのリンク先URLは相対パスで
/photo/数値/になっている -
数値の部分が写真を一意に識別できる情報なのではないか?
確認のために、別の何枚かの写真についても同様の手順でHTML要素を見てみます。
いずれも同じパターンになっていましたので、おそらく大丈夫でしょう。
各写真の詳細ページへのリンクURLがどのようなパターンかはわかりました。
しかし、HTML内にたくさんあるa要素の中から写真画像のa要素を特定するにはどうすればよいでしょうか?
いくつかのアイデアが考えられます。
HTMLツリー全体のうち何番目に現れるa要素が写真画像なのかを調べる
単純ではありますが、再現性が保証が難しく、ページ構成が少し変わるとすぐに破綻してしまいますのでおすすめしません。
写真画像のa要素出現箇所をclass属性やid属性などで絞り込む
これはよく使われる手法です。
まずはこの手法で目的の要素を特定できないかどうか検討してみましょう。
ただし一部のサイトではclass属性やid属性が無意味な文字列で難読化されていたり、アクセスする度に文字列が変わったりするなどのスクレイピング対策が施されていることがあります。(Google検索結果ページがそうです)
そのようなサイトではこの手法をあきらめざるをえません。
href属性の値が"/photo/数値/"となっているa要素を探す
これも悪い考えではないでしょう。
ただし、わざわざパターンマッチ処理を書かなければなりません。
別のよい方法があればそちらを採用したいです。
※Scrapyには【特定のパターンにマッチするURLを自動でクロールする】という便利な機能ではこれの手法を使います
今回の例ではclass属性で要素を絞り込む方法が使えそうです。
開発者ツールを見ると、目的とする<a href="/photo/数値/">のすぐ上に親要素<div class=imgholder>があります。
そこにマウスカーソルを持っていくとWebページ内の写真画像にフォーカスが当たります。
別の写真のHTML要素も見てみましょう。
開発者ツールでCtrl+Fを押すと出る検索ボックスに"imgholder"と入力してみます。
検索結果は30個ありました。
検索ボックス右に次を検索するためのボタン(下矢印っぽいもの)があるのでそれを連打してみます。
するとWebページ内の写真(だけ)に次々とフォーカスが当たっていくのが確認できました。
ここまで調査できれば、以下の結論を出してもよいでしょう。
写真一覧ページ内の<div class=imgholder>要素をすべて抽出し、その子要素の<a href="相対パス">のリンク先にアクセスすれば各写真の詳細ページにたどり着ける
では、次に1枚目の写真をクリックして写真の詳細ページを見ていきましょう。
写真の詳細ページ
本記事執筆時は1枚目は以下の写真でした。
https://photohito.com/photo/10089292/
このページもクロール可能ですので問題ありません。
写真画像ダウンロードリンクの調査
まずは写真画像をダウンロードするためのURLがどうなっているのか見てみましょう。
大きな写真画像を右クリックして「検証」を選びます。
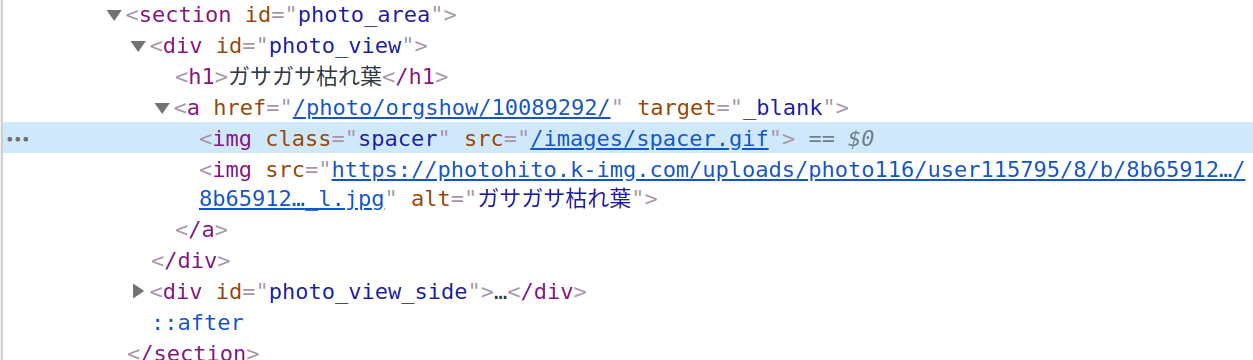
どうやら<img src="画像URL">がそれっぽいです。
一応そのURLをWebブラウザーのアドレスバーにコピペして実行してみると、写真がきちんと表示されるのが確認できると思います。
また、画像URLがWebページとは別のサーバーになっていますので、そのサーバーのrobots.txtも確認しておきます。
https://photohito.k-img.com/robots.txt
robots.txtが存在しませんので、クローラーが画像をダウンロードしても問題ないようです。
では画像URLの含まれるimgタグの特定方法を検討します。
周りを見渡すとclass属性で要素を特定できそうな気がします。
親要素<div id="photo_view">は使えそうでしょうか?
"photo_view"(ダブルクォートも含む)で検索してみると1件に絞られましたので大丈夫そうです。
よって以下の結論に至ります。
写真の詳細ページの<div id="photo_view">要素内にある<img src="画像URL">の画像URLにアクセスして写真画像をダウンロードする
写真撮影情報の調査
ページの右下の方には以下の情報がありました。
これらの情報をすべて収集してみましょう。

「撮影情報」のテキスト部分を「検証」します。
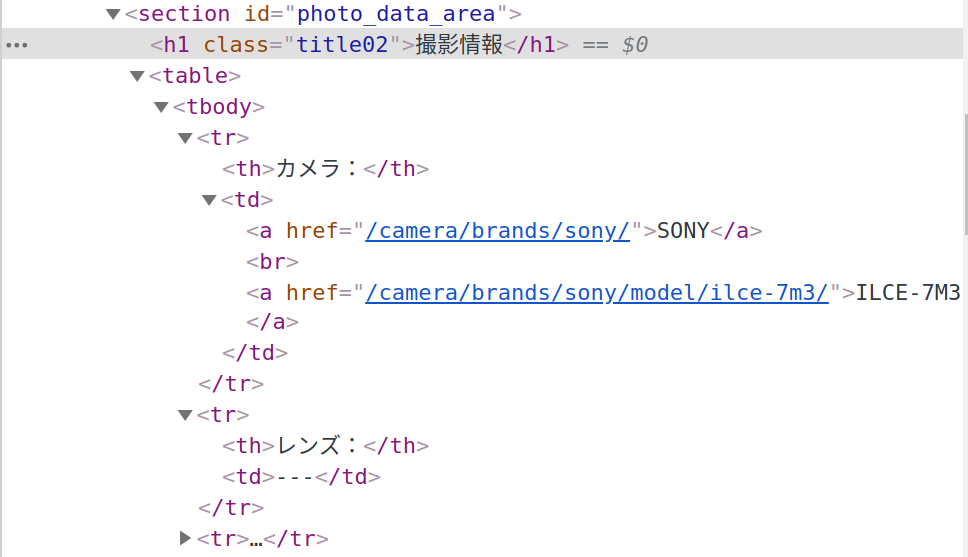
撮影情報は、id属性がphoto_data_areaである要素以下のtableを解析すればよさそうです。
またEXIFデータについてはid属性をexif_areaを置き換えれば同様の解析ができそうです。
table内の解析は具体的にどうすればよいでしょうか?
この段階ではそこまで検討しなくてもよいでしょう。
- 目的とする情報が含まれている要素を特定できる
- 情報は一定のパターンで格納されている
これらのことが確認できていれば、だいたい何とかなります。
(場合によっては力技のコードを書くことになるかもしれませんが)
以下の結論を出します。
<section id="photo_data_area">および<section id="exif_area">の子要素のtable内のtdのテキストから、撮影情報とEXIFデータを取得する。
まとめ
今回の記事では以下のことを行いました。
- スクレイピングの注意点を確認
- 2つのサイトのスクレイピング可否の判断
- スクレイピング処理が実装可能かの感覚的な判断
そして以下の結論が得られました。
PHOTOHITOをスクレイピングすれば、猫の写真の画像データおよび写真撮影情報が収集できる
次回はscrapy shellというツールを使って、対象ページのHTMLから目的の情報を抽出するためのXPathもしくはCSSセレクターを構築していきます。
ご精読ありがとうございました。
参考にした情報
- スクレイピングの注意事項
書籍紹介
この書籍が非常にわかりやすく、クローリング・スクレイピングを行うのに必要な知識がひととおり学べます。
Pythonクローリング&スクレイピング[増補改訂版]
![Pythonクローリング&スクレイピング[増補改訂版]](https://qiita-user-contents.imgix.net/https%3A%2F%2Fws-fe.amazon-adsystem.com%2Fwidgets%2Fq%3F_encoding%3DUTF8%26MarketPlace%3DJP%26ASIN%3D4297107384%26ServiceVersion%3D20070822%26ID%3DAsinImage%26WS%3D1%26Format%3D_SL250_%26tag%3Dezotaka-22?ixlib=rb-4.0.0&auto=format&gif-q=60&q=75&s=a6ea8ea009d23f0039fc8b98db8d61c8)
免責事項
- コンテンツや情報において、必ずしも正確性を保証するものではありません。また合法性や安全性なども保証しません。
- 掲載された内容によって生じた損害等の一切の責任を負いかねますので、ご了承ください。