初めて記事を書きます!
いいねもらえるとうれしいです!
概要
今回は、最近自分がやってみたかったスクレイピングを
"退屈なことはPythonにやらせよう ―ノンプログラマーにもできる自動化処理プログラミング"
を参考にやってみました。
対象
今回ダウンロードしたものは、上田麗奈さんの大人気連載の"上田麗奈のこの色いいな"で紹介されている写真です。残念ながら連載自体は最近、最終回を迎えてしまったのですが....
しかしながらいつ、ネット上からなくなってもおかしくないので最終回をきっかけとしてダウンロードしてみました。
方法
まず、作成したプログラムのimage_download_uedareina.pyを示します。
# ! python3
# ダウンロードする
import requests, os, bs4, re
# 目的の画像があるURL
url = 'https://webnewtype.com/column/color/'
column_title ='上田麗奈のこの色いいな'
# カレントディレクトリにフォルダの作成
os.makedirs(column_title, exist_ok=True)
# ページネーションからページ数を取得(1p~4p)
res = requests.get(url)
res.raise_for_status()
soup = bs4.BeautifulSoup(res.text, "lxml")
pagenation_elems = soup.select('.pagerBox .pageNumber a')
# print(pagenation_elems)
# [<a href="/column/color/p1/">1</a>,
# <a href="/column/color/p2/">2</a>,
# <a href="/column/color/p3/">3</a>,
# <a href="/column/color/p4/">4</a>]
page_content_link = [] #コラムの記事のurl
for page_item in pagenation_elems:
#p1~p4までのURLを作成(https://webnewtype.com/column/color/p1)のような
page_number_href = page_item.get("href")#/column/color/p1/
page_number_p = page_number_href.split('/').pop(-2)
#print(page_number_p)#p1
print(os.path.join(url,page_number_p))# https://webnewtype.com/column/color/p1
#ページのリストからコンテンツのリンク取得 例えば<a href="/column/color/174394/">の'174394'の部分
res = requests.get(os.path.join(url,page_number_p))
res.raise_for_status()
soup = bs4.BeautifulSoup(res.text, "lxml")
contents_elems = soup.select('#columnList .listBox ul li a')#<a href="/column/color/174394/">
#print(contents_elems)
for page_item in contents_elems:
page_content_href = page_item.get("href")#/column/color/174394/
page_content_link.append(page_content_href.split('/').pop(-2))# 174394
# print(page_content_link)#'174394', '172685', '170305', '168548',...........
for item in page_content_link:
#記事ページを取得
article_link = os.path.join(url,item)#https://webnewtype.com/column/color/174394/
res = requests.get(article_link)
res.raise_for_status()
soup = bs4.BeautifulSoup(res.text, "lxml")
article_class = soup.select('.related_imgArea li')#<a href="/column/color/174394/1/">
article_elem = soup.select('.related_imgArea li .imgArea .imgBox img')
article_title = soup.select('#columnContents .column_titleBox h1')
article_title = article_title[0].getText()#上田麗奈フォトコラム最終回・その日一日限りの色を求めて
#ファイル名に / : * ? " < > | は使えないので_に置換
article_title = article_title.translate(str.maketrans({'/': '_', ':': '_', '*': '_', '?': '_', '"': '_', '<': '_', '>': '_', '|': '_'}))
#記事ごとのサブフォルダを作成
os.makedirs(os.path.join(column_title,article_title), exist_ok=True)
print(article_title)
if article_elem == []:
print('画像が見つかりませんでした。')
else:
#<a href="/column/color/174394/20/">の20ように写真の最後を得ることで写真の枚数を知る
article_number = article_class[-1].a.get("href")
#/column/color/174394/20/ の20の数字を取得(この記事の写真の枚数)
image_number = article_number.split('/')[-2]#20
#print(image_number)#記事の画像の枚数
for i in range(int(image_number)):
#<img src="https://webnewtype.com/rsz/S1/174394/1027813.jpg/w98h98/"
# alt="上田麗奈フォトコラム最終回・その日一日限りの色を求めて">
article_url = article_elem[i].get('src')#https://webnewtype.com/rsz/S1/174394/1027813.jpg/w98h98/
#一度 /単位でURLを分ける .split('/')
#['https:', '', 'webnewtype.com', 'rsz', 'S1', '174394', '1027779.jpg', 'w98h98', '']
article_url = article_url.split('/')
del article_url[-2]#''を消去
del article_url[-1]#'w98h98' を消去
#つなぎ直す https://webnewtype.com/rsz/S1/174394/1027813.jpg/ になる
article_url = '/'.join(article_url)
#print(article_url)
res = requests.get(article_url)
res.raise_for_status()
#print('{}.'.format(os.path.basename(article_url))) # 1027813.jpg
#画像のダウンロード
#jpgファイルを作成
image_file = open(os.path.join(column_title,article_title,os.path.basename(article_url)), 'wb')
#細かくチャンクごとに分けてダウンロード
for chunk in res.iter_content(100000):
image_file.write(chunk)
image_file.close()
関数解説
まずモジュールをいくつか使用しているのではじめにプログラムを実行してみてNo moduleがでた場合はそれぞれダウンロードしてみてください。
また、変数名は参考書のサンプルを加工したものなのでいくつかふさわしくないものがあるかもしれません。
わかりにくかったら質問お願いします。
基本的には
res = requests.get('URL')
でurlを読み込みます。
res.raise_for_status()
で正しくダウンロードできているかの確認
soup = bs4.BeautifulSoup(res.text, "lxml")
でテキストに変換して加工しやすくします
class = soup.select('#id .class li a pなど')
でclassやidなどを指定して必要なものを選択します。
href = page_item.get("href")
でURLを取り出します。
そのあとは.split .join .appendをうまく使いながらURLを加工してダウンロードするリンクを整えます。
こんな感じでダウンロードできていたら成功です。

補足
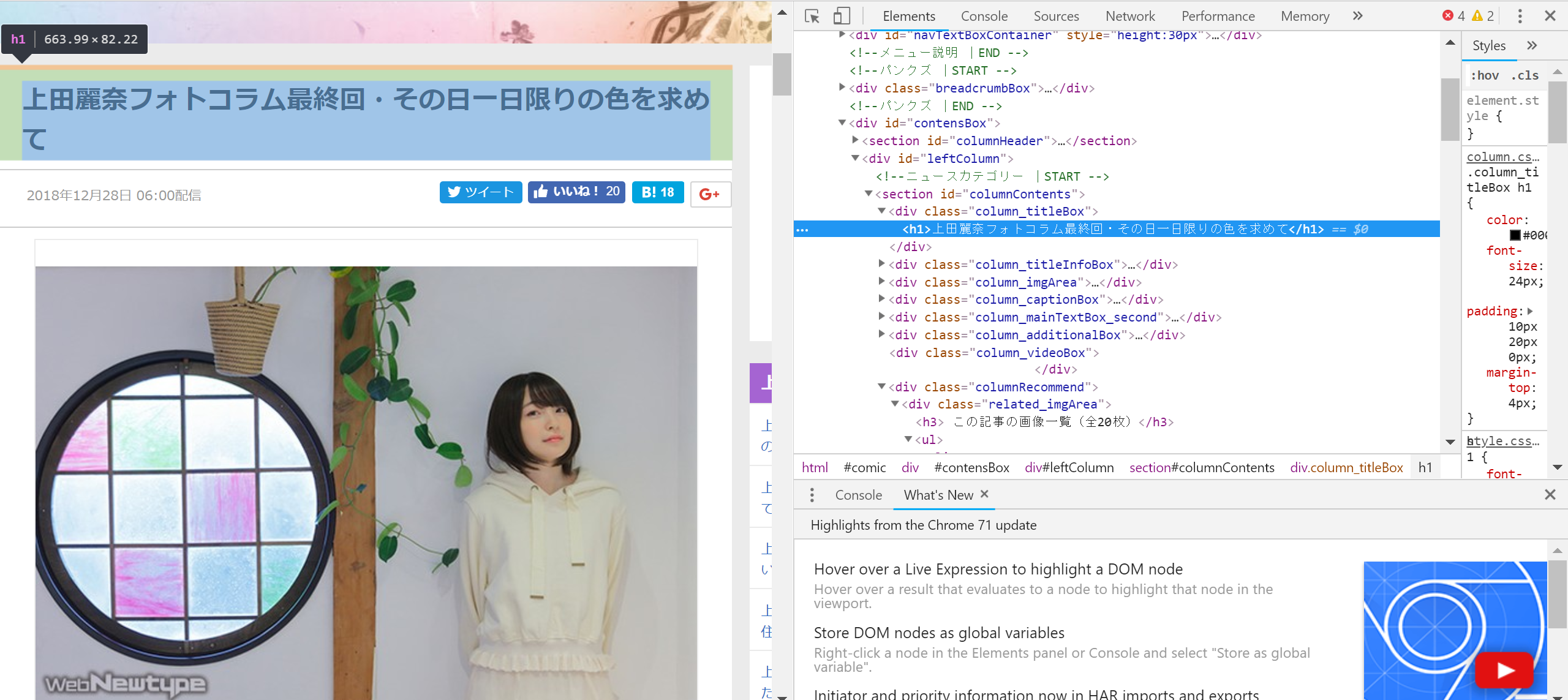
何回もセレクトをしていますがどこに注目しているかは写真の通りです。
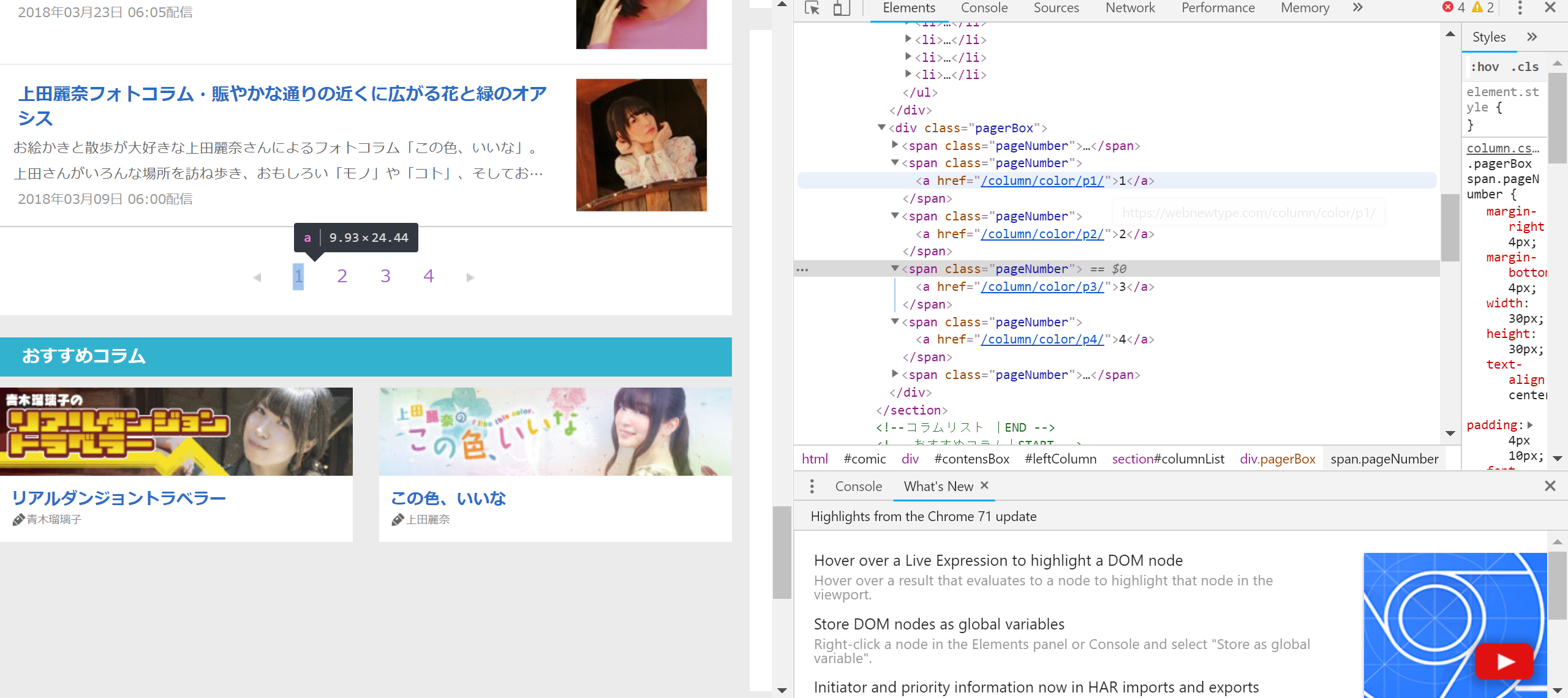
pagenation_elems = soup.select('.pagerBox .pageNumber a')
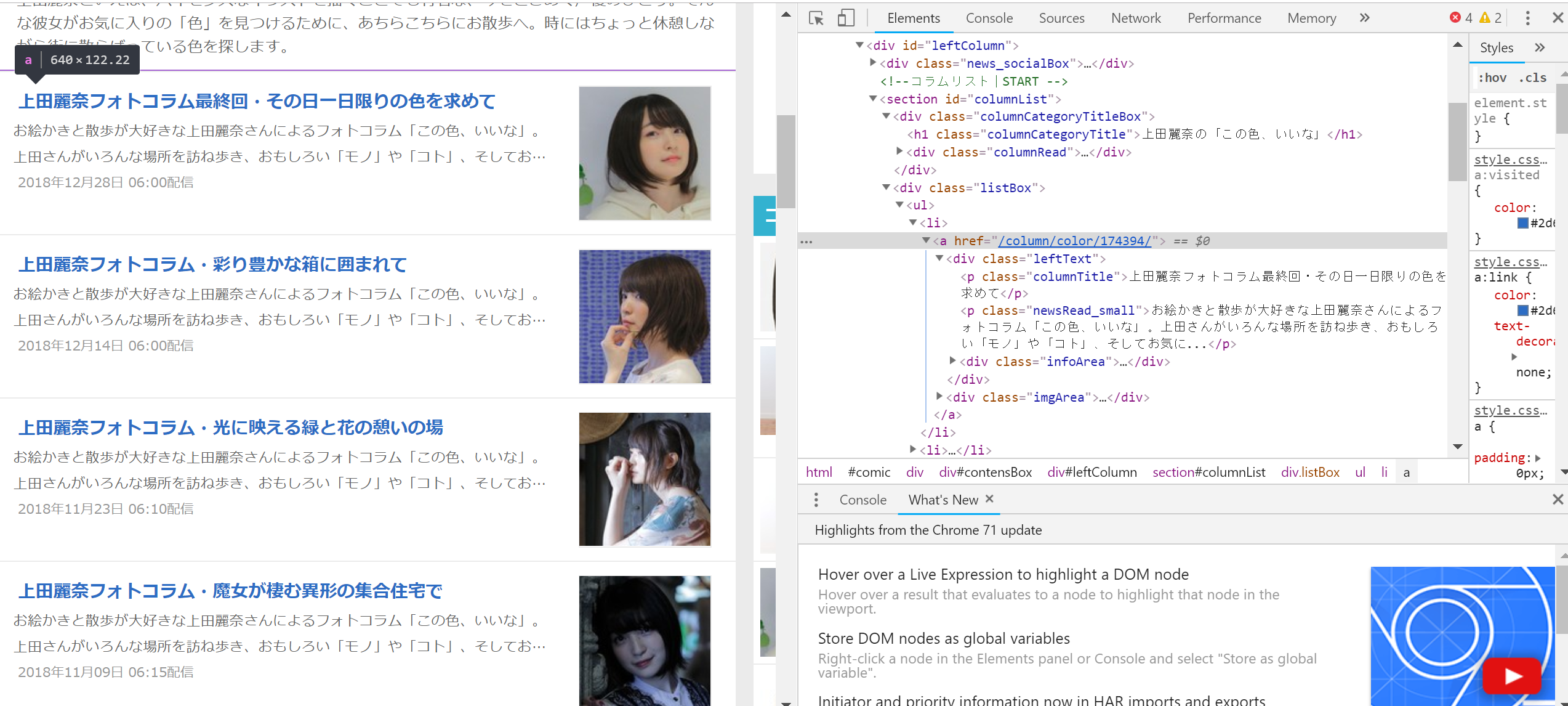
contents_elems = soup.select('#columnList .listBox ul li a')
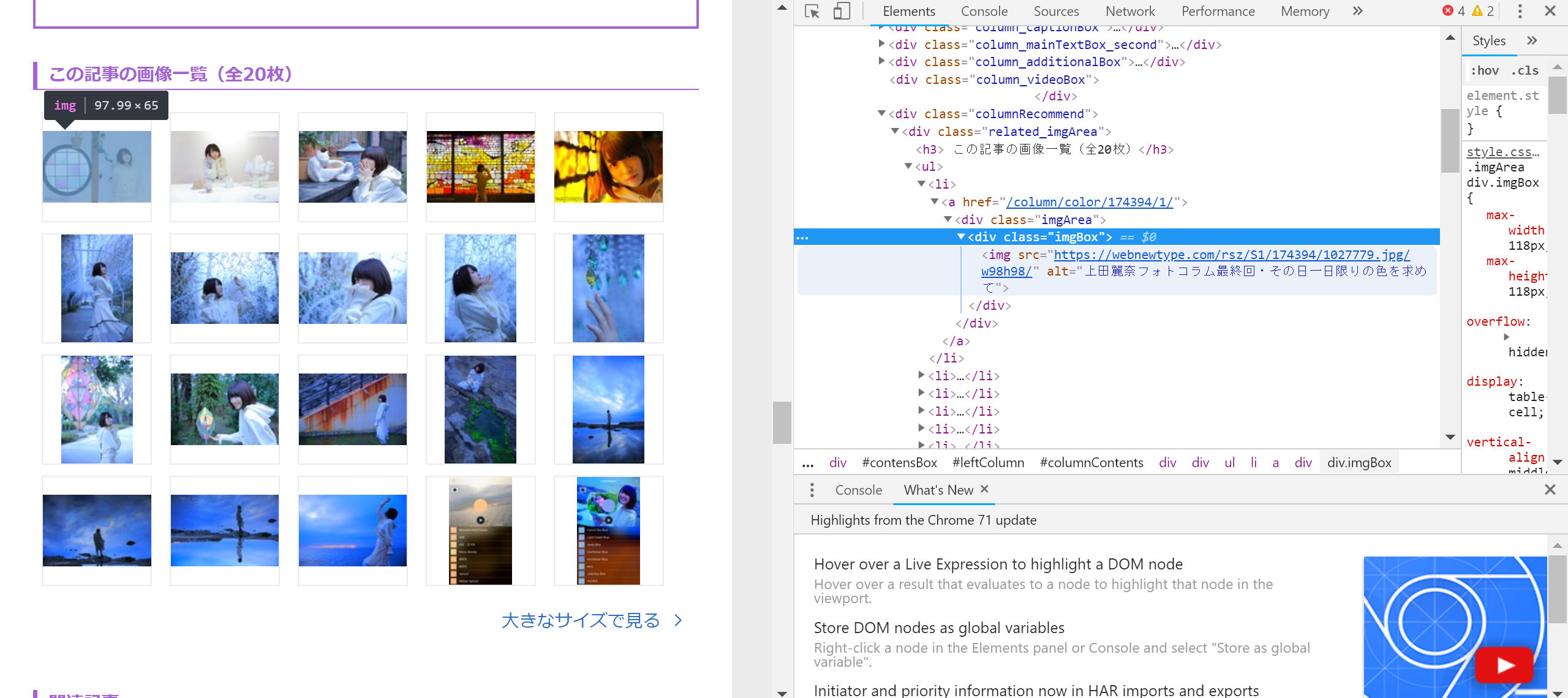
article_class = soup.select('.related_imgArea li')#<a href="/column/color/174394/1/">
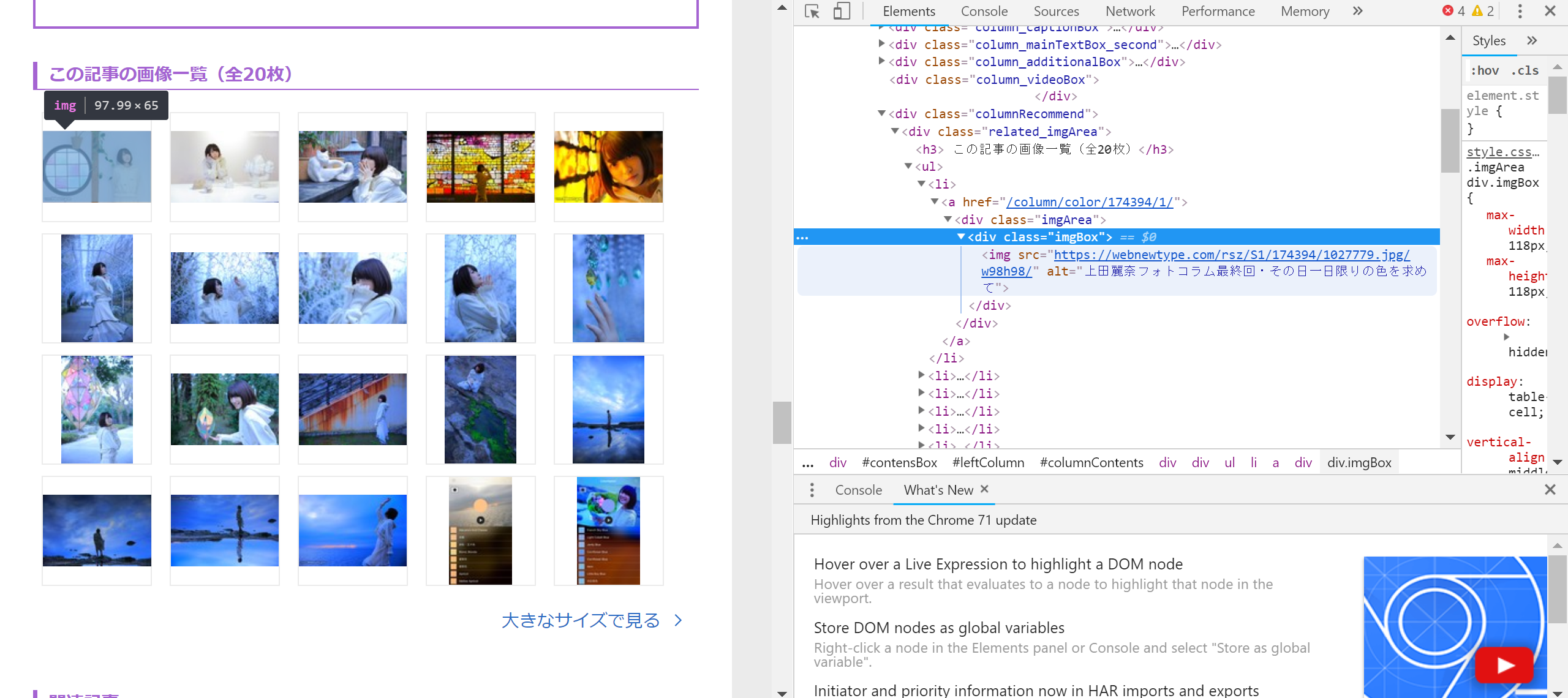
article_elem = soup.select('.related_imgArea li .imgArea .imgBox img')#画像のリンク
article_title = soup.select('#columnContents .column_titleBox h1')# タイトル
まとめ
妹にダウンロード中の画面を見せたところちょっと怖いと言われましたが、内田真礼のもお願いと言われました。
簡単な説明のみですこし寂しいかもしれませんが、質問をしてくださればなるべく答えるようにします。
上田麗奈さん誕生日おめでとうございます。