Scikit-Learnのv0.21.1以降ではLightGBMに似た、HistGradientBoosting(以下HGB)というアルゴリズムが使えると聞いたので試してみました。
環境
AnacondaでJupyterを使用しました。
Sckit-learnの更新
まずはscikit-learnヴァージョンの更新。
Anaconconda promptで下記コードを打ち、v0.21.1にします。
pip install scikit-learn==0.21.1
データ
kaggleのタイタニックコンペのデータを使用しました。
Jupyterを開き、下記コードを入力。
使用ライブラリ、タイタニックデータを読み込みます。
import pandas as pd
import numpy as np
import random as rnd
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC, LinearSVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
from sklearn.model_selection import cross_val_score
from sklearn.experimental import enable_hist_gradient_boosting
from sklearn.ensemble import HistGradientBoostingClassifier
# from sklearn.ensemble import HistGradientBoostingRegressor
from lightgbm import LGBMClassifier
train = pd.read_csv("データのあるフォルダ/train.csv")
test = pd.read_csv("データのあるフォルダ/test.csv")
データを前処理します。欠損を埋め、アルファベットを数字に変換。
このページを参考にさせていただきました。【Kaggle初心者入門編】タイタニック号で生き残るのは誰?
train["Age"].fillna(train["Age"].median(), inplace=True)
train['Embarked'].fillna('C', inplace=True)
train["Sex"][train["Sex"] == "male"] = 0
train["Sex"][train["Sex"] == "female"] = 1
train['Sex']= train['Sex'].astype(float)
train["Embarked"][train["Embarked"] == "S" ] = 0
train["Embarked"][train["Embarked"] == "C" ] = 1
train["Embarked"][train["Embarked"] == "Q"] = 2
train['Embarked']= train['Embarked'].astype(float)
test["Age"] = test["Age"].fillna(test["Age"].median())
test["Sex"][test["Sex"] == "male"] = 0
test["Sex"][test["Sex"] == "female"] = 1
test['Sex']= test['Sex'].astype(float)
test["Embarked"][test["Embarked"] == "S"] = 0
test["Embarked"][test["Embarked"] == "C"] = 1
test["Embarked"][test["Embarked"] == "Q"] = 2
test['Embarked']= test['Embarked'].astype(float)
test.Fare[152] = test.Fare.median()
とりあえずこのデータでいきます。
さっそくHGBを試してみます。今回は分類なのでHistGradientBoostingClassifier()を使いました。
比較の為に、LightGBM,やランダムフォレスト等を全てデフォルト設定で同時に実行し、
結果を表示します。
X_train = train.drop(['Survived','Name','PassengerId','Cabin','Ticket'], axis=1)
y_train = train["Survived"]
SVM = SVC()
RF = RandomForestClassifier()
LR = LogisticRegression()
HGBC = HistGradientBoostingClassifier()
LGB= LGBMClassifier()
scores = []
modelnames = ['HistGradient','SVM','RandumForest','LightGBM','LogisticRegression']
models = [HGBC,SVM,RF,LGB,LR]
for i in models:
score = cross_val_score(i, X_train, y_train, scoring = 'accuracy' , cv = 5).mean()
scores.append(score)
pd.DataFrame(scores, index=modelnames,
columns=['CV Scores']).sort_values(by = 'CV Scores', ascending = False)
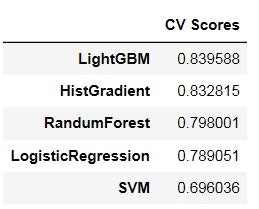
パラメータは全てデフォルト設定ですが、確かにLightGBMに近い精度が出るようです。
今後、ハイパラ調整など、もう少し詳しくやってみたいと思います。