YOLO9000: Better, Faster, Stronger
- Joseph Redmon, Ali Farhadi. 2016
- https://arxiv.org/abs/1612.08242
- http://pjreddie.com/yolo9000/
abst
- sotaのリアルタイム物体検出システム
- 9000以上の物体カテゴリを検出できる
- PASCAL VOC, COCOのような通常のdetection タスクでsota.
- YOLOv2のサイズを変えることでaccとスピードのトレードオフを調整できる
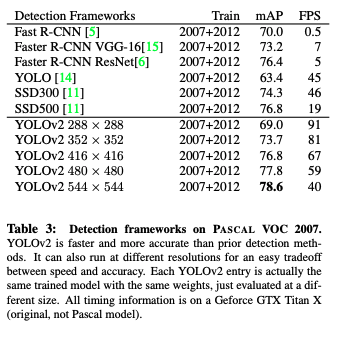
- 67FPSで78.6mAP, 40FPSまで下げると78.6mAP.(VOC2007)
- Faster RCNN with ResNetやSSDを上回る精度とスピード.
- 物体検出と分類を同時に訓練する方法を提案する
- COCOのdetectionとImageNetのclassificationで同時に訓練.
- ラベルつけられたdetectionデータがない物体クラスでもdetectionをpredictできる
- 200クラス中44クラスしかdetectionデータがなかったのに,19.7mAPを達成(ImageNet detection, validation)
- COCOに含まれない156クラスは16.0mAP
5. conclusion
- リアルタイム物体検出システムyolov2とyolo9000を提案した
- yolov2
- sotaで他の手法より速い.色々な画像サイズで実行すれば,スピードと精度のトレードオフを調節できる
- yolo9000
- detectionとclassificationを同時に最適化することで9000以上の物体カテゴリ用リアルタイムフレームワーク.
- 色々なソースからのデータを結合するのにWordTreeを使い,同時最適化手法でImageNetとCOCOを同時に学習した.
- detectionとclassificationのデータ量の問題を解決する第一歩
- 色々なソースからのデータを結合するのにWordTreeを使い,同時最適化手法でImageNetとCOCOを同時に学習した.
- 本手法の多くは物体検出以外にも一般化される
- WordTree表現はimage 分類にリッチな,詳細なoutput空間を与える
- 階層的分類を使ったdataset の組み合わせはclassificationとsegmentationに有用
- マルチスケール訓練などは多くのCVタスクに有用
- 将来的に,弱教師あり学習に類似の技術を適用したい.
- また,弱ラベルを分類データに訓練中に割り当てる強力なマッチング戦略を使ってdetection結果を改善するつもり
- CVの分野は巨大なラベルつきデータに恵まれており,異なるソースと構造のデータを一緒に使って強力なモデルを作る方法を引き続き探る
- detectionとclassificationを同時に最適化することで9000以上の物体カテゴリ用リアルタイムフレームワーク.
- yolov2
1. intro
- detection手法は速度・精度は向上したが扱える物体の数は制約されている
- detectionデータセットがclassificationとtaggingに比べて限られている
- detectionをclassificationと同じレベルまでスケールさせたい
- 現在のdetectionシステムのスコープを拡大するために既存の大量のclassificationデータを使う手法を提案する
- classificationの階層的viewを使い,異なるdataset同士を組み合わせる
- detectionとclassification両方のデータで物体検出を訓練するアルゴリズムを提案する
- ラベル付けられたdetection画像をlocalizationに使い,classification画像はvocabularyとrobustnessを高めるのに使う.
2. Better
- yoloは多くの欠点がある.classification精度を保ちつつ,これらを改善する
- error analysisによりFastRCNNに比べてlocalizationエラーが多い事がわかる
- region proposalベースの手法より比較的recall が低い
- CVではモデルを大きく,深くする傾向にあるが,本手法は精度と同時に速度も必要とする
- そのためネットワークをシンプル化し,表現を学習しやすくする方法を取る
batch norm
- 他の正則化手法なしで収束を大きく改善する
- すべての畳込みレイヤにこれを加えることで2%のmAP増加を得た
- モデルの正則化もできている
- overfittingなしで,dropoutをモデルから取り除くことができた
- モデルの正則化もできている
高解像度classifier
- すべてのsota detection手法はImageNetのpretrainedモデルを使っている.
- AlexNetに始まり,多くは256x256以下の入力画像を使う
- yoloはclassifierに224x224を入力し,detectionには448に増やす
- ? end2endなのだから同じサイズで入力したものを分岐させているのではないの?
- ネットワークは物体検出の学習と新しい入力解像度への調整を同時に切り替えしなければならないことを意味する
- ? 意味がわからない
- ネットワークは物体検出の学習と新しい入力解像度への調整を同時に切り替えしなければならないことを意味する
- ? end2endなのだから同じサイズで入力したものを分岐させているのではないの?
- yolov2では最初にclassification netを448x448でImageNetデータで10epochファインチューニングする
- これによりネットワークは高解像度の入力に対して準備する時間を得る
- その後,出来上がったネットワークをdetectionでfine tuneする
- これにより最大4% mAPが上がる
- その後,出来上がったネットワークをdetectionでfine tuneする
- これによりネットワークは高解像度の入力に対して準備する時間を得る
convolutional with anchor boxes
- yoloはconv後のfully connectedでbounding boxの座標を直接推定していた
- Faster RCNNは手作業で選んだpriorを使ってbounding boxを予測する
- 彼らのregion proposal network(RPN)はconvolutional layerだけを使ってboxのオフセットとアンカーボックスの確信度を予測する
- prediction layerがconvなのでRPNはfeature mapのすべての位置でこれらのオフセットを予測できる
- ?
- 座標ではなくoffsetにすることでシンプルになり学習しやすい
- yoloからfully connectedを取り除き,anchor boxを使ってbounding boxを予測する
- convの出力を高解像にするためにpoolingを取り除く
- networkの入力を448x448ではなく416に縮める
- convのダウンサンプルが32の倍数なので,最終的なfeature mapが13x13になるようにする
- こうすることでfeature mapの幅・高さが奇数になり,中心が1つに定まる
* class予測を位置予測と分離し,各anchor boxごとにクラスとobjectnessを予測するようにする
* objectnessはyoloと同様に正解とのIOU.class予測は物体があるとしての条件付き確率
- こうすることでfeature mapの幅・高さが奇数になり,中心が1つに定まる
- anchor boxにしたことでaccuracyが少し下がる
yoloは98boxが予測の上限だったが,anchor boxにすると1000以上同時に予測できる
* anchor なし: 69.5mAP, 81% recall
* anchor あり: 69.2mAP, 88% recall
- Faster RCNNは手作業で選んだpriorを使ってbounding boxを予測する
dimension clusters
- anchor box を手動で決めていることが問題となる
- 形は学習で変えられるが,良い初期値を持っていたほうがいい.
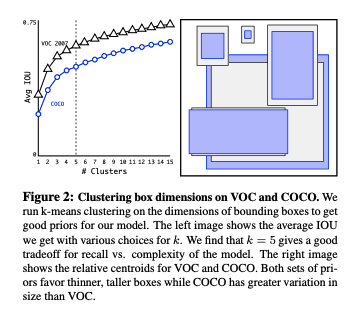
- k-meansで訓練データ中のbounding boxをクラスタリングしてpriorの形を決める
- ユークリッド距離を使うと大きいboxでエラーが大きくなるので,正解bboxとのIOUを使って,1-IOUを距離としてkmeansを行う
- priorの数がcentroidの数kとなるが,kを変えてaverage IOUをプロットした.kが大きくなると平均IOUは上がるが,(増やした分,priorとの比較やpriorの更新に必要な計算が増えるので)モデルの複雑さが増える.
- k=5をトレードオフ点として採用した
- 横長のboxは少なく,縦長が多くなった
- k-meansで訓練データ中のbounding boxをクラスタリングしてpriorの形を決める
- 形は学習で変えられるが,良い初期値を持っていたほうがいい.
direct location prediction
- anchorの2つ目の問題が,訓練初期にモデルが不安定になること
- boxの(x, y)位置を予測するときに特に顕著
- RPNではt_x, t_y, (x, y)を次で予測
- $ x = (t_x * w_a) - x_a $
- $ y = (t_y * h_a) - y_a $
- t_x = 1ならboxをその幅だけ右に移動する
- t_x = -1なら同様に左に移動
- この方法では制約がないので,boxがどの地点へも移動できる
- ランダム初期化すると,意味のある地点に安定するまでに長い時間がかかる
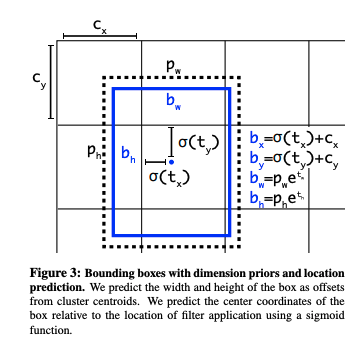
オフセットの代わりに,yolo同様にgrid cellに対する相対座標を使う - これにより0から1の間にground truthが収まる.
- 出力をlogistic activationで制約し,これを実現する
- 各cell において5つのbounding boxを予測する
- 各bboxについて,5つの座標を出力する(t_x, t_y, t_w, t_h, t_o)
- 左上角からのオフセットがc_x, c_yで,bbox のpriorがp_w, p_hの大きさなら予測は次のようになる
-
- $ b_x = \sigma(t_x) + c_x $
- $ b_y = \sigma(t_y) + c_y $
- $ b_w = p_w e^{t_w}$
- $ b_h = p_h e^{t_h}$
- $ P_r(object) * IOU(b, object) = \sigma(t_o)$
- このように制約をかけてparametrizeしたことで,学習しやすくなり,安定する
- priorの大きさクラスタリングとこの予測方法で最大5%改善した(mAPが?)
Fine-Grained Features
- 13x13feature mapでの予測は大きい物体には十分だが,小さい物体用にはもっと高解像度の特徴があったほうが良い
- Faster RCNNとSSDはnetwork中の色々な解像度のfeature map上でproposal networkを動かしている
- これらとは異なり,本研究では単純に,前の26x26レイヤから特徴を持ってくるpassthrough layerを追加した
- このレイヤはchannel方向にfeature をstackする.resnetのidentity mappingに似ている
- 26x26x512が13x13x2048になり,もともとの出力featureと連結できる.その上でdetectorが動作する
- これにより1%性能向上
- このレイヤはchannel方向にfeature をstackする.resnetのidentity mappingに似ている
- これらとは異なり,本研究では単純に,前の26x26レイヤから特徴を持ってくるpassthrough layerを追加した
- Faster RCNNとSSDはnetwork中の色々な解像度のfeature map上でproposal networkを動かしている
multi-scale training
- modelはconvとpoolしか使わないので,入力サイズを変えることもできる
- 入力画像サイズを固定せずに,数iterationごとに変える
- 10batchesごとに,ランダムであたらしい画像サイズを選ぶ:32の倍数でダウンサンプルするので,{320, 352, ..., 608}から.
- 最小が320, 最大が608x608になる
- 10batchesごとに,ランダムであたらしい画像サイズを選ぶ:32の倍数でダウンサンプルするので,{320, 352, ..., 608}から.
- 入力画像サイズを固定せずに,数iterationごとに変える
- ネットワークが異なる解像度でも予測できるようになる
- 288x288 だと90FPS以上,高解像度にすると78.6mAP on VOC2007,リアルタイム処理.
Further experiments
3. Faster
- 精度と同時に速度もほしい
- 多くのdetectionフレームワークはVGG16をベース特徴抽出に使っているが,これは過度に複雑である.
- yoloはGooglenetをベースにした独自ネットワークを使っていた.これはVGGより少ない計算量だが,少し精度が劣る
- ImageNetでVGGは90.0%, yoloは88.0%
- yoloはGooglenetをベースにした独自ネットワークを使っていた.これはVGGより少ない計算量だが,少し精度が劣る
- 多くのdetectionフレームワークはVGG16をベース特徴抽出に使っているが,これは過度に複雑である.
darknet-19
- 新しいモデル, darknet-19を導入する
- VGG同様,convで3x3フィルタを使い,プーリング後にchannelを2倍にする
- global average poolingを使う
- 1x1フィルタをfeature 表現を圧縮するのに使う
- batch normを使う
- このモデルは19のconvとmaxpool 5個を持つ
- yoloのときよりも計算量が少なく,ImageNetのtop1accが72.9, top5accが91.2%
Training for classification
- ImageNet 1000クラス分類データセットでDarknetを160epoch訓練
- パラメタ詳細は省略
- data拡張:random crop, rotation , hue, saturation, exposure shifts
- 最初に224x224で訓練し,448x448でfine tuneする
- fine tune は10 epoch
- top1 acc: 76.5%, top5acc: 93.3%
training for detection
- 最後のconvレイヤを取り除いて3x3, 1024フィルタの convとその後に1x1convを追加.
- 1x1のchannel数はdetectionに必要な数
- 5boxes, 5coordinates, 20classの場合は125フィルタになる
- passthrough layerを最後の3x3x512レイヤから2番めから最後のconvへと追加する
- 1x1のchannel数はdetectionに必要な数
4. stronger
- 分類と検出を同時に訓練する手法を提案する
- detection用画像bbox等のラベルを持つ
- 分類可能なカテゴリ数を増やすために,クラスラベルのみがラベル付けされた画像を使用する
- 訓練中はdetectionとclassificationデータセットの画像をmixする
- classification画像を見たときは,classification担当部分だけlossをbackporpする
- この手法の難しいところ:
- detectionは「犬」等の一般的なラベルを持ち,classificationはもっと広く深いラベルを持つ.「ヨークシャーテリア」など
- softmaxで分類することはクラスが相互排他的であることを仮定している
- なのでそのままImageNetとCOCOをくっつけることはできない
* そこで,multi-labelモデルを使う
- なのでそのままImageNetとCOCOをくっつけることはできない
Hierarchical classification
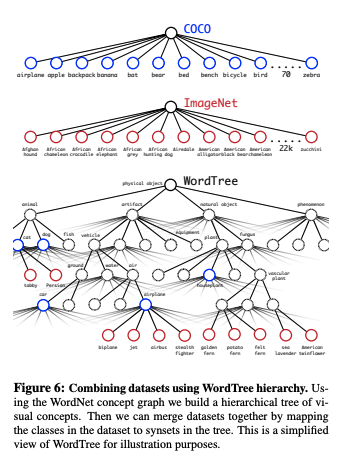
- ImageNetのラベルは言語の概念と関係を構造化したデータベースのWordNetから作られている
- ex. 犬->猟犬->テリア-> ヨークシャーテリア, ノーフォークテリア
- 多くの分類手法はラベルがフラットな構造を仮定しているが,データセットを組み合わせるときは構造がほしい
- WordNetは有向グラフであり木ではない
- dogはcanineでもありdomestic animalでもある
- ImageNetの概念から階層的木を作ることで簡単にする
- WordNetのroot(physical object)まで1つのパスしかないものを最初に木に加える
- できるだけ少しずつ残りの概念を木に加えていく
- 概念がrootまで2つ以上のパスを持っているなら短い方を採用する
- 出来上がった木をWordTreeと呼ぶ
- terrierノードにおいては,terrierが既知としてNorolk terrierやYorkshire terrierの事後確率を求める
- 絶対確率を求めたければ,rootから対象ノードへたどりながらその条件確率を掛けていく
- root(pysical object)の確率は1とする
- 概念がrootまで2つ以上のパスを持っているなら短い方を採用する
- できるだけ少しずつ残りの概念を木に加えていく
- wordTree 1kは中間ノードを加えて1369クラス
- norfolk terrier がラベル付けされていればdogとmammalもラベルになるように訓練
- hierarchical Darknet19はtop1accで71.9%, top5accで90.4%
- 369ノードの追加があったが精度の低下が少ない
- この方法は種類がわからない犬画像に対しても,犬という予測はできる,というようなメリットがある
- objectnessの値をroot(physical object)の確率として使用することでdetectionにも拡張できる
dataset combination with wordTree
- wordTreeは複数のデータセットを組み合わせるのに汎用的に使える
- 各データセットのクラスをwordTreeの対応するクラスにマップすればいい
joint classification and detection
-
full ImageNet releaseのtop9000クラスとCOCO detectionから9418クラスのWordTreeを作った
- ImageNetがでかいのでCOCOからoversamplingして4:1でImageNetが大きくなるようにした
- detection画像のときは通常のbp
- classification lossはラベルの対応するレベルより上だけbpする
- ラベルが犬なら,その下のGerman shepherd対Golden Retrieverに対するerrorを割り当てない(原文には「割り当てる」と書いてあるが,文脈的に「割り当てない」が正しい気がする)
- classification lossはラベルの対応するレベルより上だけbpする
- classification 画像のときはclassification lossだけをbpする
- 最も高い確率でそのクラスを予測しているbboxを見つけ,その予測木で計算する
- 正解とIOU0.3だけオーバーラップしていると仮定してobjectness lossをbpする
-
ImageNet detectionタスクでevaluateする
- 全体で19.7mAP, detection dataを見たことがないdisjointな156オブジェクトクラスに対して16mAP
- DPMより高い
- 全体で19.7mAP, detection dataを見たことがないdisjointな156オブジェクトクラスに対して16mAP
-
新しい種類の動物は学習しているが,衣類や道具は苦手
- COCOが服のラベルを持っていないから