SpineNet: Learning Scale-Permuted Backbone for Recognition and Localization
- Xianzhi Du, Tsung-Yi Lin, Pengchong Jin, Golnaz Ghiasi, Mingxing Tan, Yin Cui, Quoc V. Le, Xiaodan Song
- CVPR 2020
- 論文
-
https://arxiv.org/abs/1912.05027
- この記事で読んでいるのはv2
-
https://arxiv.org/abs/1912.05027
- コード
ひとことまとめ
-
どんなもの?
- 物体検出を主目的としたバックボーンネットワークの提案
-
先行研究と比べてどこがすごい?
- 従来のCNNが採用する層が進むごとに解像度を落として深さを増やしていくメタアーキテクチャを否定し,解像度と層の深度を独立させた
- COCOの物体検出で52.1% APを達成(SoTAはCascade Mask R-CNNの53.3).iNaturalistの画像分類でResNet-50を5%上回るtop-1 accuracy
-
技術や手法のキモはどこ?
- CNNのfeature mapのスケールがモデル内のどこでも増減でき(scale permutation),feature map間の接続は層をまたいでも構わない(cross-scale connection)
- これを実現させるため,Neural Architecture Searchを使って膨大な探索空間から自動でモデル設計している
- CNNのfeature mapのスケールがモデル内のどこでも増減でき(scale permutation),feature map間の接続は層をまたいでも構わない(cross-scale connection)
-
どうやって有効だと検証した?
- SpineNetをRetinaNetのバックボーンとして用い,COCOでの物体検出でYOLO, ResNet-FPN, NAS-FPN等と比較
- ImageNetとiNaturalistでの画像分類でResNet-50と比較
- ablation study
-
議論はある?
- 特になし
-
次に読むべき論文は?
- [44] Neural Architecture Search(NAS)
- ニューラルネットの自動設計手法
- [22] RetinaNet
- 物体検出フレームワーク
- [6] NAS-FPN,および[42] Auto-FPN
- NASを物体検出に適用した先行研究
- [5] DropBlock
- 正則化手法
- [28] swish activation
- 活性化関数
- [44] Neural Architecture Search(NAS)
abst
- 畳み込みネットワークは解像度を下げながら中間特徴にencodeしていくが,認識と位置推定を同時に行う物体検出には有効ではない
- これを解決するためにencoder-decoder構造が提案されているが,複数スケールの強い特徴生成には効果的ではない
- backboneが解像度減少していくため
- これを解決するためにencoder-decoder構造が提案されているが,複数スケールの強い特徴生成には効果的ではない
- 中間特徴が並べ替えられ,クロススケールの接続を持つバックボーンであるSpineNetを提案する
- 物体検出タスクでのNeural Architecture Searchにより(ネットワーク構造が)自動的に学習される
- SpineNet-190はCOCOで,sotaのdetectorを遥かに上回る52.1% APを達成
- 分類タスクにtransfer learningした結果,チャレンジングなiNaturalistデータセットで5% のtop-1 accuracy改善
6. Conclusion
- decoderネットワークがあったとしても,畳み込みスケール減少モデルは同時に認識と位置推定するには効果的ではないことを示した
- これを解決するスケール並べ替えモデルを提案した
- スケール並べ替えモデルの有効性を示すため,SpineNetを物体検出タスクでNeural Architecture Searchで学習し,画像分類で直接利用できることを示した
- これを解決するスケール並べ替えモデルを提案した
- 将来,スケール並べ替えモデルは多くの視覚タスクでバックボーンのメタアーキテクチャ設計となるだろう
1. イントロ
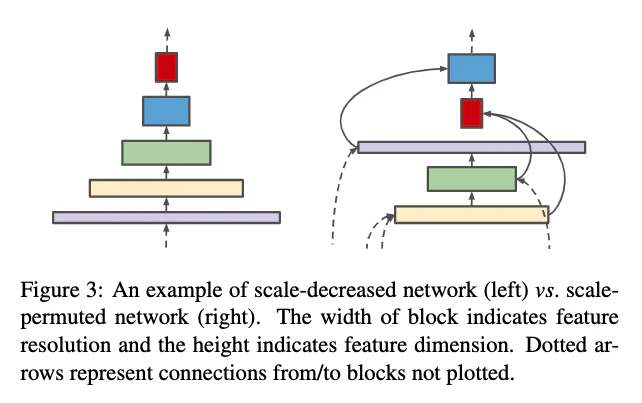
- 畳み込みネットワークは幅と深さが増えるほど強力になる[10, 43]が,メタアーキテクチャデザインは変わっていない
- すなわち,入力画像の解像度を減少させながら中間特徴へencodeすることである
- ネットワークアーキテクチャデザインの改善はほとんどが深さの増加と特徴解像度グループ内での接続による[19, 10, 14, 45]
- LeCunら[19]は解像度を下げるデザインの目的について,「特徴の存在を検知するのに高解像度が必要なことがあるが,同じくらい高い精度でその位置を検出する必要はない」としている(= 位置は多少ずれていても問題ない)
- すなわち,入力画像の解像度を減少させながら中間特徴へencodeすることである
- スケール減少モデルは,マルチスケール視覚認識タスクで強い特徴を伝達することはできないかもしれない.(物体検出とセグメンテーション)
- Linら[21]が小さい物体を検出できないことを示している
- [21, 1]などはこれを解決するためマルチスケールencoder-decoder構造を提案している
- scale-decreased ネットワークはencoderとして使用され,モデルのバックボーンと呼ばれる
- 特徴の解像度を復元するためにバックボーンの後にdecoderが適用される
- decoderの設計はbackboneとはぜんぜん違う.
- たいていcorss-scaleの接続が連なっており,backboneからの低レベルと高レベルの特徴を結合して強力なmulti-scale feature mapを作っている
- たいていbackboneのほうがdecoderよりパラメタと計算量が多く,decoderはそのままでbackboneのサイズを増やす戦略が一般的
- 本論文では「スケール減少モデルはdetection用のバックボーン設計にふさわしいのか?」という問に答える
- 直感的に,スケール減少モデルはダウンサンプリングで空間情報を捨てており,decoderがそれを復元するのは難しい
- そこでスケール並べ替え(scale-permuted)モデルというメタアーキテクチャを提案する.バックボーン設計として2つの改善点がある
- 中間feature mapのスケールがどこでも増減できる
- これによりモデルは深くなっても空間情報を保持できる
- feature map間の接続はfeature scale間を超えることができる
- 複数スケールの特徴を融合できる
- 中間feature mapのスケールがどこでも増減できる
- メタアーキテクチャ設計としてシンプルなルールを決めたが,実現しようとするとモデルの深さにつれて組み合わせが爆発する
- 手動で捜索せず,Neural Architecture Search(NAS)[44]でアーキテクチャを学習する
- バックボーンモデルはCOCO dataset[23]の物体検出タスクで学習
- NAS-FPN[6]が成功しているので,シンプルな1ステージRetinaNet[22]を実験で使った
- 彼らはfeature pyramid networkを学習していたが,本手法はbackbone 構造を学習し,直接,クラス分類とbox回帰のサブネットワークに接続する
- つまりバックボーン(=encoder)とdecoderの境界をなくしたのであり,バックボーンモデル全体がfeature pyramid networkだとみなせる
- 彼らはfeature pyramid networkを学習していたが,本手法はbackbone 構造を学習し,直接,クラス分類とbox回帰のサブネットワークに接続する
- 手動で捜索せず,Neural Architecture Search(NAS)[44]でアーキテクチャを学習する
- ResNet-50[10]をベースラインとして,そのbottleneck blockを探索空間の特徴ブロックの候補にした.次の2つを学習した
- 特徴ブロックの並べ替え(permutations)
- 各特徴ブロックについて,2つの入力の接続(通常の入力とskip connection入力で2つ入力があるので,それらをどこから持ってくるかという話だろうか)
- 探索空間内のすべての候補モデルは,feature blockの順番を変えているだけなので,計算量は変わらない
- 学習されたスケール並べ替えモデルは,ResNet-50-FPNを(+2.9% AP)で上回った
- スケールと,residual blockとbottleneck blockを選択できるようにするとさらに効率性に-10% FLOPsの改善が見られた
- この学習されたアーキテクチャをSpineNetと呼ぶ
- 学習されたスケール並べ替えモデルは,ResNet-50-FPNを(+2.9% AP)で上回った
- ImageNetとiNaturalist分類データセットで評価した
- SpineNetは物体検出で学習した構造だが,分類にもtransferできた
- iNaturalist fine-grained classification datasetで,ResNetを5% accuracy上回った
- スケール並べ替えバックボーンは多目的であり,他の視覚認識タスクにも適用できる可能性がある
- iNaturalist fine-grained classification datasetで,ResNetを5% accuracy上回った
- SpineNetは物体検出で学習した構造だが,分類にもtransferできた
2. 関連研究
- ImageNet分類で高いaccuracyのモデルをbackboneに使うと,他の視覚推定タスクで高精度になることを示したものがある[16, 21, 1]
- しかしImageNet向けに作られたbackboneは,decoderを組み合わせたとしても,localizationタスクには効果的ではない場合がある[21, 1]
- DetNet[20]は特徴をdown-sampleするとlocalization能力が落ちるとしている
- HRNet[40]はparallel multi-scale inter-connected branchを追加することでこれを解決しようとした
- Stacked Hourglass[27]とFishNet[33]はskip connectionのある再帰的down-sampleとup-sampleアーキテクチャを提案
- scale-decreasedなbackboneではなく,donwn-sampleとup-sample両方を使ってbackboneを作ることを考えている
- しかしImageNet向けに作られたbackboneは,decoderを組み合わせたとしても,localizationタスクには効果的ではない場合がある[21, 1]
2.2. Neural Architecture Search
- Neural Architecture Search(NAS)は,手作りのモデルよりも画像分類で良い結果を出している[45, 25, 26, 41, 29, 38]
- NASは与えられた探索空間で,特定の報酬を最適化することでアーキテクチャを学習する
- 分類以外の適用例:(Auto-DeepLab[24]以外の手法はscale-decreasedなbackbone)
- NAS-FPN[6],Auto-FPN[42]は物体検出にNASを適用して多層feature pyramid network学習した初期の研究
- DetNAS[2]はbackboneを学習し,標準的なFPN[21]と組み合わせる
- Auto-DeepLab[24]はbackboneを学習し,DeepLabV3[1]のデコーダと組み合わせ,semantic segmentationする
3. 提案手法
- 提案するbackboneは,固定のstem networkに学習されるscale permuted networkが続く構造
- stemはscale-decreased アーキテクチャである
- stemのブロックは,後続のscale-permutedネットワークの入力として使うことができる
- stemはscale-decreased アーキテクチャである
- scale-permuted ネットワークはビルディングブロックのリスト${ B_1, B_2, ..., B_N}$から構成される
- 各ブロック$B_k$は関連する特徴レベル$L_i$を持つ
- $L_i$ブロックにおけるfeature mapは入力解像度の$\frac{1}{2^i}$の解像度を持つ
- 同じレベルのブロックは同じ構造を持つ
- $L_3$から$L_7$へと5つの出力ブロックを定義し,1x1 convが各出力ブロックに適用される
- それぞれ同じ次元数を持つmulti-scale feature $P_3$から$P_7$を作るため
- 残りのビルディングブロックは出力ブロックの前の中間ブロックに使われる
- 各ブロック$B_k$は関連する特徴レベル$L_i$を持つ
- NASにおいて,最初に中間・出力ブロックのためのscale permutation をサーチし,次にブロック間のcross-scale connectionを決める
- 探索空間にブロック調節を加えることでさらに改善できる
3.1. 探索空間
Scale permutation
- ブロックはその前にある(順番が若い)親ブロックからのみ接続(入力)を取る
- 中間・出力ブロックをそれぞれpermuteすることで探索空間を定義し,結果として空間のサイズは$(N-5)!5!$となる
- scale permutationはそれ以外のアーキテクチャ要素よりも先に決定する
- 中間・出力ブロックをそれぞれpermuteすることで探索空間を定義し,結果として空間のサイズは$(N-5)!5!$となる
Cross-scale connections
- 探索空間にある各ブロックにつき2つの入力connectionを定める
- 親ブロックは順番が若いブロックか,stem networkのブロックならどれでもよい
- 異なるfeature levelにあるブロックを接続するときは空間的および特徴次元数についてresamplingが必要
- 探索空間のサイズは$\Pi_{i=m}^{N + m -1}$
- Nはビルディングブロックの数,mはstem networkにある候補ブロックの数
Block adjustments
- ブロックはスケールレベルとタイプを調節できる
- 中間ブロックは${-1, 0, 1, 2}$の中からレベルを調節する
- 探索空間のサイズは$4^{N-5}$になる
- すべてのブロックは{$bottleneck block, residual block $}の2つからタイプを選ぶことができる
- 探索空間のサイズは$2^N$
- 中間ブロックは${-1, 0, 1, 2}$の中からレベルを調節する
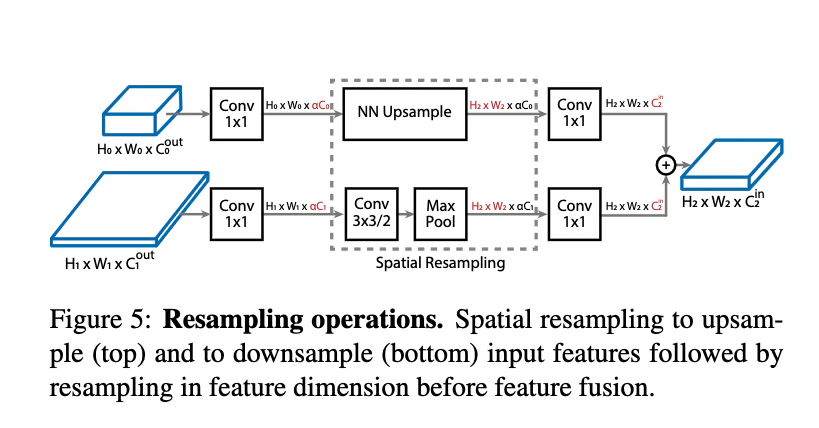
3.2. cross-scale connectionsにおけるリサンプリング
- cross-scale feature 融合において,親ブロックとターゲットブロックで解像度やfeature dimensionが異なるので,一致させるために空間的&特徴リサンプリングを行う
- $C$はresidual またはbottleneckブロックにおける$3 \times 3$convolution の特徴の次元数
- $C^{in}$と$C^{out}$はブロックの入力と出力の次元数とする
- ボトルネックブロックについては,$C^{in} = C^{out} = 4C$
- residual blockについては$C^{in} = C^{out} = C$
- $C^{in}$と$C^{out}$はブロックの入力と出力の次元数とする
- 計算コストを下げるため,スケーリングファクター$\alpha$(デフォルト0.5)を導入する
- 親ブロックの出力特徴次元数$C^{out}$を$\alpha C$に調節する
- その後,up-samplingではニアレストネイバー補完,down-samplingではstride-2 3x3 convolution(必要ならstride-2 max poolingが続く)を使って,対象の解像度に合わせる
- 最後に,特徴次元数$\alpha C$をターゲットの特徴次元数$C^{in}$に合わせるために1x1畳み込みが適用される
- FPN[21]に従い,2つのリサンプルされた入力feature mapは要素ごとの加算で統合する
- $C$はresidual またはbottleneckブロックにおける$3 \times 3$convolution の特徴の次元数
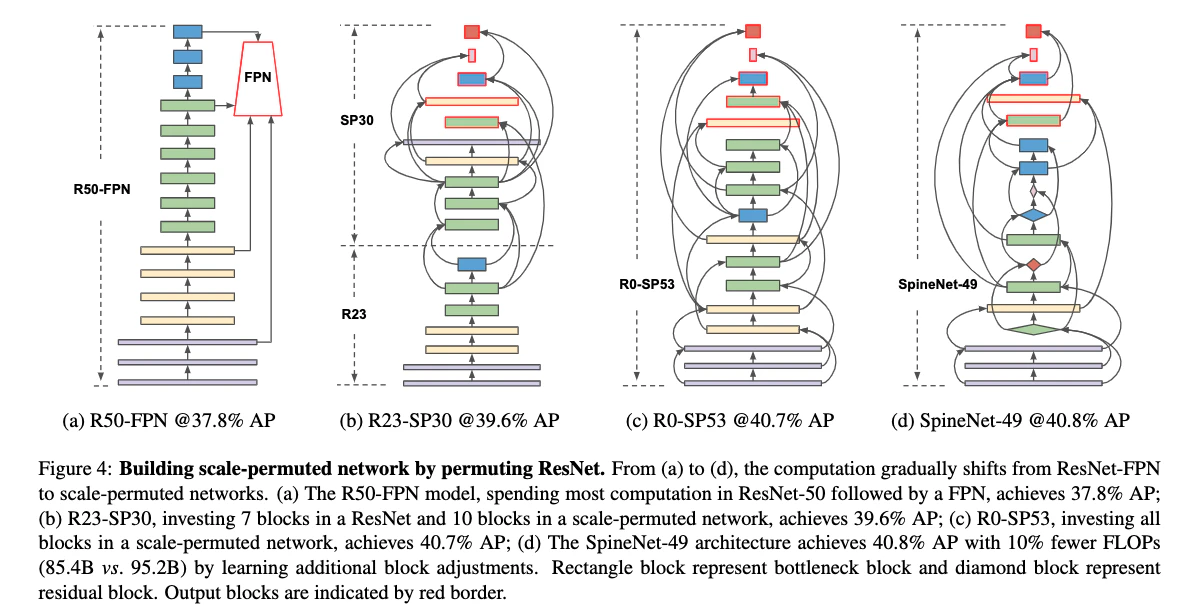
3.3. ResNetの並べ替えによるscale-permuted model
- scale-permuted modelをResNetのブロックで作るが,同じビルディングブロックを使ってscale-permuted modelとscale-decreased modelのフェアな比較がしたい
- scale-permuted modelがmulti-scale出力を生成するように変更を加えた
- ResNetの$L_5$ブロックの一つを$L_6$と$L_7$に置き換え,$L_5$, $L_6$, $L_7$の特徴次元数を256にした
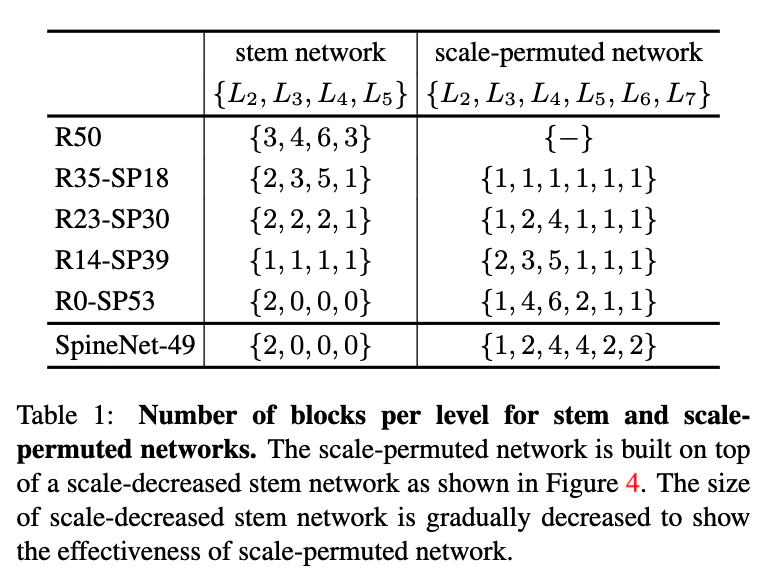
- 完全なscale-decreasedとscale-permutedの比較に加えて,前者のstemネットワークから後者のネットワークへと次第にシフトしていくモデルのfamilyを作った.
- $R \left[ N\right]-SP\left[ M\right] $はN個の特徴レイヤが手作業で作ったstemにあり,M個の特徴レイヤが学習されたscale-permuted networkにあることを示す
- フェアな比較のため,探索空間がscale permutationとcross-scale connectionのみを含むようにした
- モデルアーキテクチャを生成するcontrollerを訓練するのに強化学習を用いた
- [6]同様,生成されたモデルにおいて,それ以降のブロックのどれにも接続しない中間ブロックはその対応するレベルの出力ブロックと接続することにした
- scale-permuted modelがmulti-scale出力を生成するように変更を加えた
3.4. SpineNetアーキテクチャ
- ResNet-50のビルディングブロックを使ったが,この選択が最適ではないかもしれない
- そこで3.1.で導入したブロック調節を追加し,学習された構造をSpineNet-49とした
- SpineNet-49をベースに,latencyと性能のトレードオフを変化させてもうまく動くようなSpineNetのfamilyを作った
- SpineNet-49S
- ベースと同じ構造で,すべてのfeature dimensionが0.65の倍率で削減されている
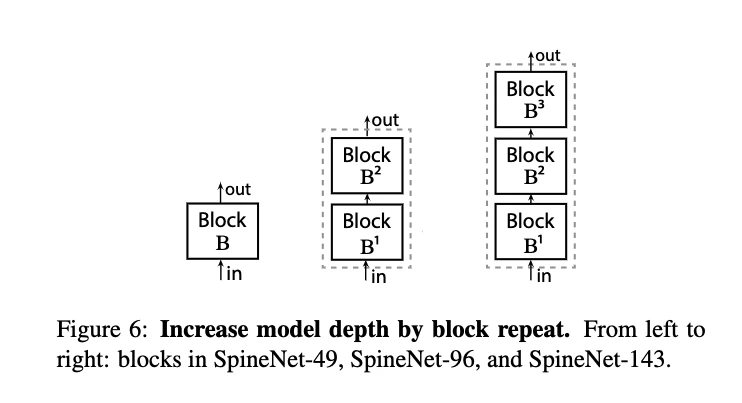
- SpineNet-96
- 各ブロック$B_k$を2倍にすることでモデルサイズが2倍になっている
- $B_k$が$B_{k}^1$と$B_{k}^2$に複製され,直列に接続される
- $B_{k}^1$は入力の親ブロック,$B_{k}^2$は出力のターゲットブロックに接続
- $B_k$が$B_{k}^1$と$B_{k}^2$に複製され,直列に接続される
- 各ブロック$B_k$を2倍にすることでモデルサイズが2倍になっている
- SpineNet-143, SpineNet-190
- 各ブロックを3倍と4倍に増加し,リサンプリング操作において$\alpha$を1.0としたもの
- SpineNet-49S
- DetNas[2]ではShuffleNetv2 ブロックやefficient model scaling[38]を使っているが,これらは使用しなかった
- 今回の研究とは平行に適用可能かもしれない
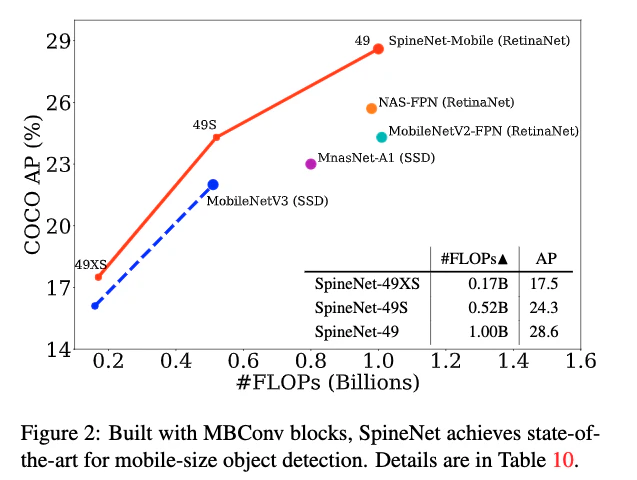
4. 応用
4.1. 物体検出
- SpineNetはRetinaNetのResNet-FPN backboneを置き換えて,一緒に学習される
- クラスとboxのサブネットのアーキテクチャは[22]に従った
- SpineNet-49S
- 4つの共有畳み込みレイヤ.特徴次元は128
- SpineNet-49/96/143
- 4つの共有畳み込みレイヤ.特徴次元は256
- SpineNet-190
- 7つの共有畳み込みレイヤ.特徴次元は512
- SpineNet-49S
- クラスとboxのサブネットのアーキテクチャは[22]に従った
- SpineNetがMask R-CNN[9]のバックボーンとしても使えて,box検出とinstance segmentaiton両方を改善することを示した
4.2. 画像分類
- SpineNetの汎用性を示すため,画像分類に適用した
- $P_3$から$P_7$のfeature pyramidを利用して分類ネットワークを作った
- 最後の特徴マップは$P = \frac{1}{5}\sum_{i = 3}^7 U(P_i)$で,feature mapの平均とupsamplingで生成される
- $U(\cdot)$は最大のfeature mapである$P_3$とスケールを同じにするためのニアレストネイバーupsampling
- Pには256次元特徴ベクトルを作るために通常のglobal average poolingが適用される
- その後,線形分類器とsoftmaxが続く
5. 実験
- 物体検出については,SpineNetをCOCOデータセット[23]で評価
- train2017 で訓練
- main resultsは test-devのCOCO APで,残りはval2017での結果を示した
- 分類
- SpineNetをImageNet ILSVRC-2012[31]とiNaturalist-2017[39]で訓練し,Top-1とTop-5 validation accuracyを報告する
5.1. 実験設定
- 物体検出では640,896,1024, 1280のサイズでSpineNetに画像を入力
- 長辺が指定サイズと合うようにスケールし,短辺はゼロ埋めして正方形にする
- 分類では224x224の入力サイズ
- 訓練ではデータ拡張(スケール・アスペクト比の拡張,ランダムクロップ,水平フリップ)
訓練の詳細
- 物体検出では[22, 6]に従い基本的に同じ訓練手法を取った.プロトコルAと呼ぶ
- Cloud TPU v3
- SGD
- 重み減衰 4e-5
- モメンタム 0.9
- COCO train2017で事前訓練なしのフロムスクラッチ
- バッチサイズ 256
- エポック数 250
- 初期学習率 0.28
- 最初の5エポックでlinear warmup適用
- ステップごとに学習率を0.1x減衰, 最後の30と10エポックでは0.01x
- [8]に従い,0.99モメンタムでsynchronized batch normalization-> ReLUを適用し,正則化にDropBlock[5]を実装した
- [6]同様,ランダムスケール[0.8, 1.2]の間でマルチスケール訓練を適用
- RetinaNetの基本アンカーサイズをSpineNet-96以下のモデルでは3,143以上のモデルでは4にした
- 報告した結果では,改善版プロトコルBを採用した
- DropBlockを除去
- ランダムスケール[0.5, 2.0]のより強力なマルチスケール訓練を適用
- エポック数 350
- 最も競争力のある結果を得るのに,プロトコルCを用いた
- より強い正則化のためにstochastic depth[15]を追加
- ReLUをswish activation[28]で置き換え
- エポック数 500
- 画像分類
- バッチサイズ 4096
- エポック数 200
- cosine learning rate decay[11]
- 学習率の線形スケーリング
- 最初の5エポックでのgradual warmup[7]
NASの詳細
- アーキテクチャサーチのため,[44]で提案されたRNNベースのコントローラを実装した
- 知る限り,並べ替え操作のサーチが可能な唯一の方法であるため
- サーチのバリデーションのために7392枚の画像をtrain2017から除外
- サーチの高速化のために,(縮小版のアーキテクチャ)proxy SpineNetを設計
- SpineNet-49を一様にスケールダウンしている
- 特徴次元が0.25倍,リサンプリングにおける$\alpha$が0.25,box・クラス用ネットワークの特徴次元が64
- SpineNet-49を一様にスケールダウンしている
- 探索空間の爆発を防ぐため,中間ブロックは(そのブロックから)5ブロック以内の親ブロックのみ探索でき,出力ブロックはすべてのブロックを探索できるようにした
- 各サンプルにおいて,5エポックで512の解像度でproxy taskが訓練される
- 除外しておいたvalidation setでのproxy taskのAPが報酬として収集される
- コントローラは子モデルをサンプルするために100個のCloud TPU v3を並列に使用する
- R35-SP18, R23-SP30, R14-SP39, R0-SP53, SpineNet-49のアーキテクチャで,最適なものはそれぞれ6k, 19k, 13k, 13k, 14kのアーキテクチャをサンプルした結果見つかった
- サーチの高速化のために,(縮小版のアーキテクチャ)proxy SpineNetを設計
5.2. 学習されたscale-permuted アーキテクチャ
- 2つの隣接する中間ブロックが接続され深いpathwayを構成している場合がよく見受けられる
- 出力ブロックはより長距離の接続を好む
5.3. ResNet-FPN vs. SpineNet
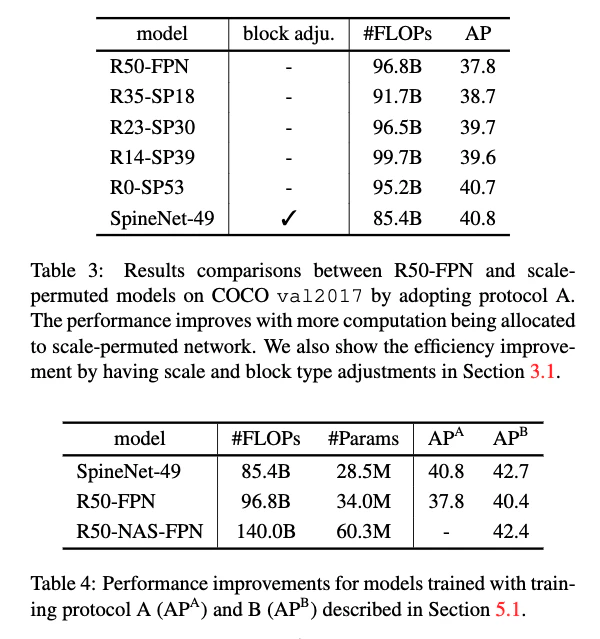
- 3.3で導入した4つのscale-permuted modelと,ResNet50-FPNを比較する
- 表3から,本論文の主張であるscale-decreased backboneが物体検出に向いていないこと,scale-permuted modelに置き換えると性能が上がることがわかる
- SpineNet-49はR0-SP53に比べてFLOPsが10%減少し,効率性が向上している(ニューラルネットのFLOPsは計算の複雑さを表すので減少したほうが良い)
- 精度は同じ.両者の違いは探索にスケールとブロックタイプ調節を加えたこと
5.4. 物体検出の結果
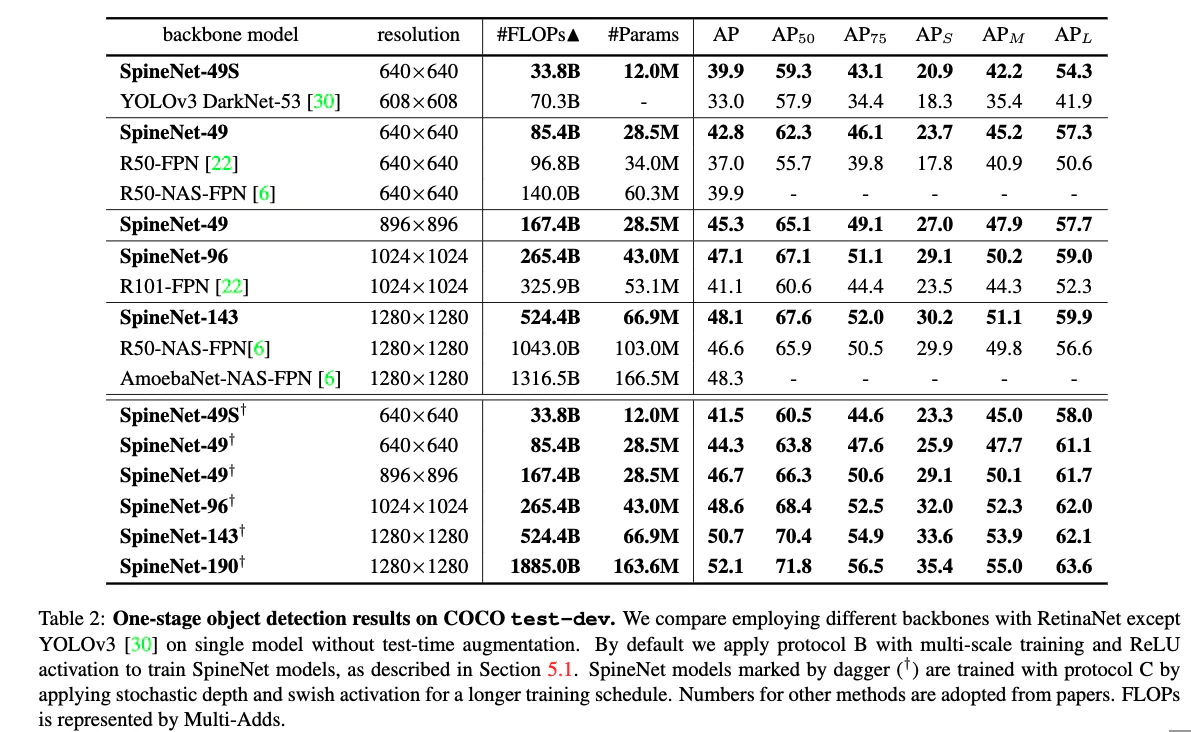
- RetinaNet detectorを使ってCOCO bounding box detectionでのSpineNetの評価を行う.結果は表2
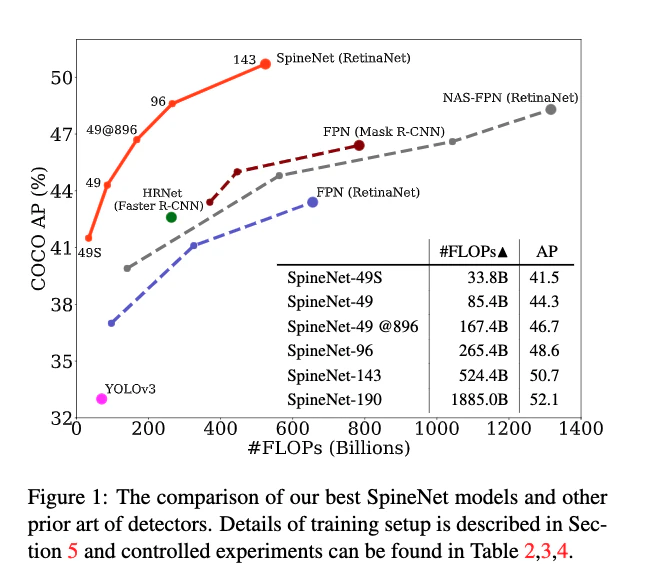
- SpineNetはYOLO, ResNet-FPN, NAS-FPNのような検出器を精度・効率ともに大きく上回る
- SpineNet-190はtest-time augmentationなしで52.1%AP
- (test-time augmentationは推論時にテストデータにaugmentationをかけて何度も推論し,結果の平均や多数決で最終結果を決定する手法)
- SpineNet-190はtest-time augmentationなしで52.1%AP
- SpineNetはYOLO, ResNet-FPN, NAS-FPNのような検出器を精度・効率ともに大きく上回る
Mask R-CNN
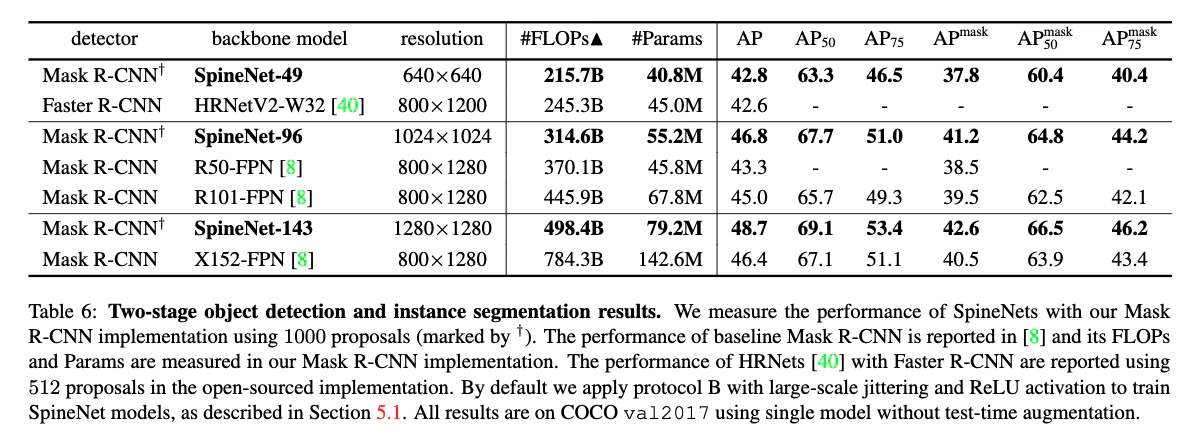
- SpineNetをMask R-CNNと組み合わせてbox detectionとinstance segmentationで高い性能が得られる(表6)
- SpineNetは少ないFLOPsとパラメタ数でより良いAPとmask APを達成
- SpineNetはRetinaNetを使ってbox detectionで学習しているが,Mask R-CNNと組み合わせても性能が良い
- SpineNetは少ないFLOPsとパラメタ数でより良いAPとmask APを達成
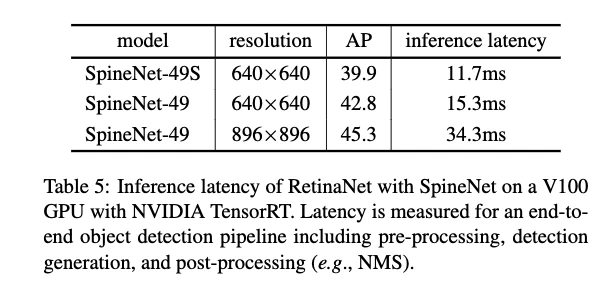
リアルタイム物体検出
- SpineNet-49SとSpineNet-49をRetinaNetで実行すると30+ fpsだった
- NVIDIA TensorRTを使用して,V100 GPUの環境
5.5. アブレーションスタディー
scale permutationの重要性
- 順序固定のfeature scaleと比較することでscale permutationの重要性を示す
- encoder-decoderネットワークのポピュラーなアーキテクチャを2つ選んだ
- [27, 21]に見られるようなHourglass(砂時計)形状
- [33]のようなFish(魚)形状
- 3.1節と同じ探索空間でcross-scale connectionを学習した
- 結果,scale permutationをcross-scale connectionと一緒に学習したほうが,固定アーキテクチャ形状を(cross-scale)connectionと学習するより良い結果となった
- Hourglass, Fish形状でもっと良いアーキテクチャがあるかもしれないが,シンプルなものだけを実験した
- encoder-decoderネットワークのポピュラーなアーキテクチャを2つ選んだ
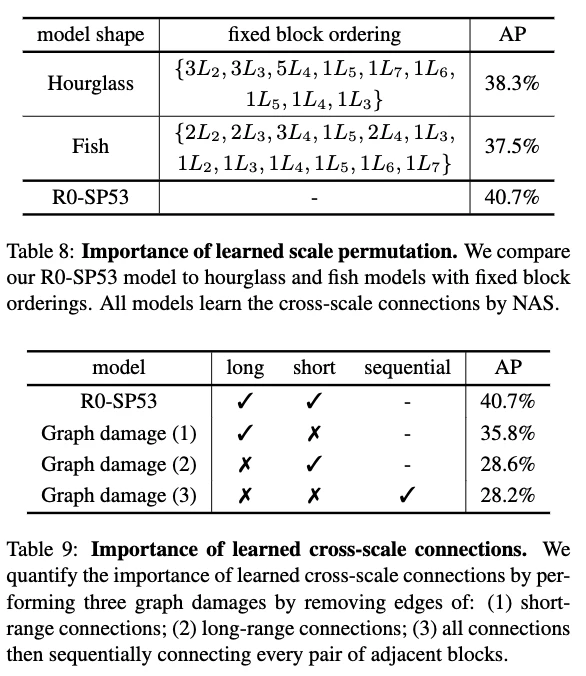
cross-scale connectionの重要性
- scale-permuted networkにおいて,cross-scale connectionは異なる解像度の特徴を融合するのに重要
- ダメージグラフによりその重要性を調べた
- R0-SP53の各ブロックで,corss-scale connectionに次のようにダメージを与える
- 短い接続を取り除く
- 長い接続を取り除く
- 両方取り除き,一つのブロックを前のブロックとsequentialにつなげる
- すべてのケースで一つのブロックは他の一つだけに接続する
- R0-SP53の各ブロックで,corss-scale connectionに次のようにダメージを与える
- 結果はすべてのケースで影響を受けたが,1.よりも2.と3.の影響が大きかった
- 短い接続やsequentialな接続は頻繁な解像度の変更に対処できないためと考えられる
- ダメージグラフによりその重要性を調べた
5.6. SpineNetを使った画像分類
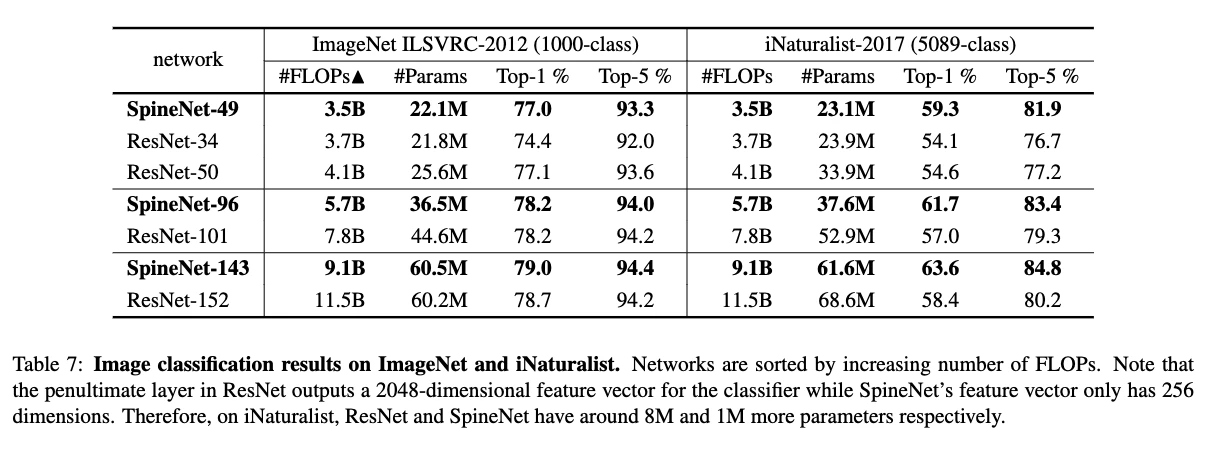
- ImageNetでは,SpineNetはより少ないFLOPsで,ResNetと同等の性能を示した
- iNaturalistでは,5%程度の大差でResNetを上回った
- iNaturalist-2017はチャレンジングな高解像度分類データセット.
- 579,184の訓練画像,95,986のvalidation画像,5,089のクラスがある
- iNaturalist-2017はチャレンジングな高解像度分類データセット.
- iNaturalistでの改善を理解するため,[39]で集められた正解bboxを使って物体を切り抜き,iNaturalist-bboxを作った
- すべてのバウンディングボックスは1.5xに拡大され,対象物体だけでなく周辺コンテキストも含めてcropしている
- 496,164の訓練画像,48,736のvalidation, 2,854のクラスとなった
- このデータセットでは,Top-1/Top-5 accuracyはSpineNet-49で63.9%/86.9%,ResNetは59.6%/83.3%
- SpineNetはTop-1で4.7%上昇したことになる
- cropする前のデータセットでは,SpineNetは4.7%だった
- 以上のことから,iNaturalistデータセットでの改善は,大きさの変わる物体を捕らえたからではなく,次の2点によると考えられる
- SpineNetのmulti-scale featureのおかげでかすかな局所的な差異を捕らえられたこと
- 過学習しにくい256次元のコンパクトな特徴表現を使っていること