Show and Tell: A Neural Image Caption Generator
- Oriol Vinyals, Alexander Toshev, Samy Bengio, Dumitru Erhan
- 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
-
https://arxiv.org/abs/1411.4555
- 本記事で読んだのはv2

ひとことまとめ
どんなもの?
- 画像を入力して,画像の内容を説明した自然言語の文章を生成するネットワークNICの提案
先行研究と比べてどこがすごい?
- 画像のエンコードにCNN,デコードにRNNを使っていて,従来手法より性能が高い
技術や手法のキモはどこ?
- CNNとRNNを直接つなげることで,CNNからの視覚特徴と,RNNが扱う言語特徴を同じ埋め込み空間に位置させている
- CNNを事前訓練された重みで初期化する
-
正解文章の尤度を直接最大化する形で訓練(20200428訂正)
どうやって有効だと検証した?
- 4つのデータセット(PASCAL, Flickr30k, Flickr8k, SBU)で,主にBLEUスコアと人間による評価
議論はある?
- キャプション生成の評価でよく使われているランキングタスクは有効な検証方法ではないとしている
- 本手法自体はランキングタスクでも良好な結果を出している
- BLEUスコアを評価に使うことにはかなり議論がある(人間による評価とBLEUの数値が共起しない)
次に読むべき論文は?
- [21].Flickrデータセットでsotaだった手法.
- 従来retrievalベースが主流だったが,generationもやっている(本手法はgeneration)
- [31].メトリクスについて詳細な議論
abst
- 画像を説明する自然言語の文章を生成できるディープラーニングベースの生成モデルを提案する
- 訓練画像を入力し,ターゲット説明文の尤度を最大化するように訓練する
- 実験で,モデルの正確さと説明文だけから学習される言語の流暢さを確認した
- sotaのBLEU-1スコアは25だが,本手法は59程度で,人間は69である
- COCOデータセットでBLEU-4スコア27.7を達成し,sotaとなった
5. Conclusion
- 画像を入力し,妥当な英語説明文を生成するエンドツーエンドのニューラルネット, NICを提案した
- CNNが画像をencodeし,RNNが文を生成する
- データセットのサイズが増えると性能が向上することが実験で示された
- 将来的に,教師なしデータ(画像単体やテキスト単体のこと)の使用を試すのも面白いだろう
1. イントロ
- 画像の内容を説明するちゃんとした英語文章自動生成するのはチャレンジングなタスクである
- 説明は物体だけでなく,物体間の関係や属性,それらの行っている動作を捕らえなければならない
- 英語のような自然言語でそれをやるには,視覚の理解に加えて言語モデルも必要
- 本研究は画像$I$を入力して尤度$p(S|I)$を最大化するよう訓練される
- 尤度はターゲット単語系列$S = { S_1, S_2, ...}$が生成される尤度であり,各単語$S_t$は画像を適切に説明する所与の辞書から用いるものである
- 本研究はRNNによる機械翻訳の進展をもとにしている
- これらはencoder RNNが入力文を読み,固定長ベクトルに変換し,そのベクトルをdecoder RNNの初期状態としてターゲット文を生成する
- この方法に従い,encoderRNNをCNNに置き換える
- CNNは画像分類で事前訓練しておく
- この手法をNeural Image Caption, NICと呼ぶ
- CNNは画像分類で事前訓練しておく
- この方法に従い,encoderRNNをCNNに置き換える
- これらはencoder RNNが入力文を読み,固定長ベクトルに変換し,そのベクトルをdecoder RNNの初期状態としてターゲット文を生成する
- 本論文の貢献は以下
- エンドツーエンドシステムの提案
- 本モデルはsotaのサブネットワークを組み合わせており,それぞれ事前訓練できる
- sota手法と比べて非常に良い性能を示している.BLEUスコアで59達成など
2. 関連研究
- 視覚データからの説明生成は主に動画について行われていた[7][32]
- 静止画は最近だが,表現力が足りなかった
- Farhadi et al.[6]: シーン要素のトリプレット
- Julkani et al.[16]: 複雑な検出のグラフ
- [29]: co-embedにneural netを使用
- これらの手法は個別の物体を訓練中に見ていても,見たことのない組み合わせを説明できない
- 生成された説明文を評価できない
- 本研究はRNNをend-to-endで訓練している
- 機械翻訳[3, 2, 30]に影響を受けている
- 最も近いのはfeedforwardネットワークを使ったKiros et al.[15]
- 本手法はパワフルなRNNを使い,視覚入力をRNNモデルに直接入力.
- これにより,RNNはテキストで説明されている物体を追いかけ続けることができる
- 本手法はパワフルなRNNを使い,視覚入力をRNNモデルに直接入力.
- Kiros et al.[14]はjoint multimodal embedding spaceをLSTMで構築する提案をしている
- 彼らはjoint embeddingを定義するのに,画像とテキストで別々の道を使っている
- 文は生成できるが,彼らの手法はranking用にかなりチューンされたものである
- 彼らはjoint embeddingを定義するのに,画像とテキストで別々の道を使っている
3. モデル
- 画像から説明を生成するニューラル確率的フレームワークを提案する
- 統計的機械翻訳が,入力文から正しい翻訳の確率を直接最大化する手法をend-to-endで行いsotaを達成していることを手本にしている
- encoder RNNの代わりにvisual CNNを使って同じことをする
- 入力画像のもとで,正しい説明の確率を最大化するために次式を使う
- $\theta^* = \underset{\theta}{argmax}\sum_{I, S}{logp(S|I;\theta)} \tag{1}$
- $\theta$はモデルパラメタ
- $I$が画像,$S$が正しい説明文
- $\theta^* = \underset{\theta}{argmax}\sum_{I, S}{logp(S|I;\theta)} \tag{1}$
- 正解$S$はどんな文章でもよいので,長さは制限しない
- 故に$S_0,..., S_N$の結合確率をモデリングするのに次のようなチェインルールを用いるのが普通である
- $N$は特定のサンプル文の長さ
- $logp(S|I) = \sum_{t=0}^{N} logp(S_t|I, S_0, ..., S_{t-1}) \tag{2}$
- $\theta$は省略した
- $(S, I)$は訓練例のペアで,(2)式のlog 確率をデータセット全体に対して和を取り,確率的勾配降下法で最適化
- 故に$S_0,..., S_N$の結合確率をモデリングするのに次のようなチェインルールを用いるのが普通である
- $p(S_t|I, S_0, ..., S_{t-1})$をRNNでモデリングするのが自然である
- t-1まで条件づけた可変個数の単語が,固定長の隠れ状態,またはメモリと呼ばれる$h_t$で表現される
- メモリは新しい入力$x_t$を見た後,非線形関数$f$で更新される
- $h_{t+1} = f(h_t, x_t) \tag{3}$
- 本提案では$f$としてLSTMを使う
- メモリは新しい入力$x_t$を見た後,非線形関数$f$で更新される
- t-1まで条件づけた可変個数の単語が,固定長の隠れ状態,またはメモリと呼ばれる$h_t$で表現される
- 画像の表現にはCNNを使う
- batch normalizationも使う
- 単語は埋め込みモデルで表現する
- 統計的機械翻訳が,入力文から正しい翻訳の確率を直接最大化する手法をend-to-endで行いsotaを達成していることを手本にしている
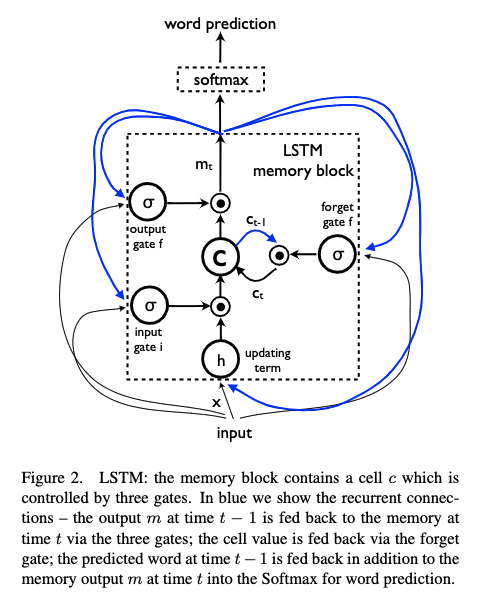
3.1. LSTMベースの文章生成器
-
(LSTM自体の説明は省略する)
-
図2
-
Training
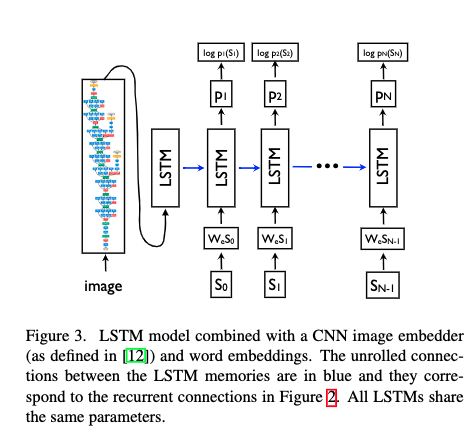
- 図3に,LSTMが展開した状態でCNNと一緒に描かれている
- $I$が画像,$S= (S_0, ..., S_N)$が正解文章として,次のような手順になる
- $x_{-1} = CNN(I) \tag{10}$
- $x_t = W_e S_t, t \in { 0 ... N - 1 } \tag{11}$
- $p_{t+1} = LSTM(x_t), t \in { 0 ... N-1} \tag{12}$
- 各単語は次元が辞書のサイズと等しいone-hotベクトル$S_t$
- $S_0$は開始ワード,$S_N$は停止ワード
- 画像は$CNN$で,単語は埋め込み$W_e$で同じ空間にマップされる
- 画像$I$は$t = -1$の一回きりしかLSTMにインプットされない
- 何回も入力すると性能が落ちることを確認している
- 画像$I$は$t = -1$の一回きりしかLSTMにインプットされない
- 誤差は,各ステップでの正しい単語の,負の対数尤度として次のように定義
- $L(I, S) = - \sum_{t=1}^N log p_t(S_t) \tag{13}$
- この誤差はLSTM,画像埋め込みCNNのtop layer, 単語埋め込み行列$W_e$のすべてのパラメタについて最小化する
-
(ここで定義されているのは正解sequenceと出力との誤差ではない.これは尤度であり,入力画像のもとで,正解sequenceが高い尤度(確率)を持つようにモデルを訓練している.こうすることで,その入力画像が来たときには正解sequenceのような系列を出力すれば良いということを学習する)- (20200428追記.実装上は単語単位のcross-entropyなどを使うはず)
- $L(I, S) = - \sum_{t=1}^N log p_t(S_t) \tag{13}$
Inference
- 画像を入力して,文を出力する方法はいくつかある
-
サンプリング
- 最初の単語を$p_1$にもとづいてサンプルし,その埋め込みを入力として$p_2$をサンプルする.
- end-of-sequenceトークンが出るまで,または規定数に達するまでサンプルを続ける
-
ビームサーチ
- (この記事の筆者の理解で書きます)
- (時間$t+1$の単語をサンプルするために,時間$t$までの「最も良い文章候補」を$k$組保持しておき,$t+1$の単語をサンプルする.一つではなく単語候補をn個サンプルする)
- (k個の候補それぞれの末尾にサンプルされたn個の単語が組み合わせられるので,k * n個の候補文章ができる.この中から最も良いものだけk個残し,後は捨てる)
- (最初の単語もn個サンプルして,k個残しているはずなので,おそらくn=kのはず)
- (k個の候補それぞれの末尾にサンプルされたn個の単語が組み合わせられるので,k * n個の候補文章ができる.この中から最も良いものだけk個残し,後は捨てる)
- (時間$t+1$の単語をサンプルするために,時間$t$までの「最も良い文章候補」を$k$組保持しておき,$t+1$の単語をサンプルする.一つではなく単語候補をn個サンプルする)
- この方法は$S = argmax_{s'}p(S'|I)$をよく近似できる
- 次の4.実験ではbeamサイズ20を使った
- beamサイズ1(=greedy search)ではBLEUポイントが2低下した
- (この記事の筆者の理解で書きます)
-
サンプリング
4. 実験
- いくつかのメトリクス,データ,モデル構造で,本モデルの効率性を評価する実験を行った
4.1. 評価指標
- 最も信頼できる評価指標は最もコストが高い,つまり人間に主観的なスコアを付けてもらうこと
- 本研究ではいくつかの評価指標がこの主観スコアと同じ傾向を持つようにするために,この主観スコアを用いた
- [11]のガイドラインに従い,1から4の間で評価者に尋ねた(4が最も良い)
- Amazon Mechanical Turkで,1枚の画像に対して2名の評価者が評価を行った
- 2名の意見は普通65%で一致するが,一致しない場合はスコアの平均を採用した
- 分散分析のためにbootstrappingを行った(結果を復元抽出して,平均・標準偏差を計算)
- [11]同様に,ある規定値以上のスコアを報告した
- 本研究ではいくつかの評価指標がこの主観スコアと同じ傾向を持つようにするために,この主観スコアを用いた
- その他のメトリクスは正解を使って自動的に計測できる
- BLEUスコア[25]は生成文と参照文の単語nグラムのprecision
- perplexityは各予測された単語の逆確率の幾何平均
- これはモデル選択とハイパラチューニングに使う
- 詳細なメトリクスの議論は[31]参照.
- その他にはMETEORとCiderを用いた
- image descriptionの文献では与えられた画像に関する可能な説明文をランク付けするという代理タスクを使う
- recall@k のような既知のランキングメトリクスを使える
- しかし生成タスクをランキングタスクにするのは不十分である
- 画像が複雑になると対応する辞書(の単語)が増加する.
- よって可能な文章の数が指数的に増加する.
- 文章が指数的に増加しない限り,新しい画像とfitするべき事前定義された文章の尤度が低下するが,文章が指数的に増加するのは現実的ではない
- (辞書が増えた分だけ正解データもバラエティに富んだ物を大量に用意できないと訓練例が可能な訓練例空間の中でスパースになるという意味かと思っている.ランキングタスクというのがどういうものかよくわからない)
- よって可能な文章の数が指数的に増加する.
- 画像が複雑になると対応する辞書(の単語)が増加する.
4.2. データセット
- SBUを除いて,ラベルは文が5つある
- SBUはFlickrにアップロードした画像の所有者がつけた説明なので,視覚特徴に基づいている保証やバイアスなしにラベル付けされている保証はない
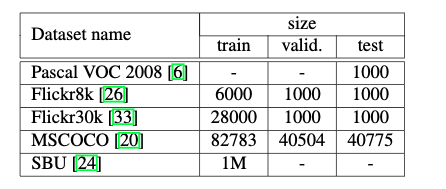
- SBUはFlickrにアップロードした画像の所有者がつけた説明なので,視覚特徴に基づいている保証やバイアスなしにラベル付けされている保証はない
4.3. 結果
- データセットサイズが汎化性能にどう影響するか,どんな転移学習が可能か,弱いラベル付けにどう対応するか,といった疑問に答えたい
4.3.1 訓練の詳細
- 過学習を防ぐためにCNNの重みをImageNetなどで初期化する
- 単語埋め込み$W_e$も同じようなことができるが,精度向上は得られなかったので,こちらは初期化を行わなかった
- DropoutとアンサンブルがBLEUを数ポイント上げた
- CNN以外の重みはランダムに初期化し,CNNの重みは固定した.固定しないと性能が悪化する
- 説明文は分かち書きを行い,5回以上出現した単語だけを使用した
4.3.2 生成結果
- PASCALデータセットは訓練セットがないので,MSCOCOで訓練
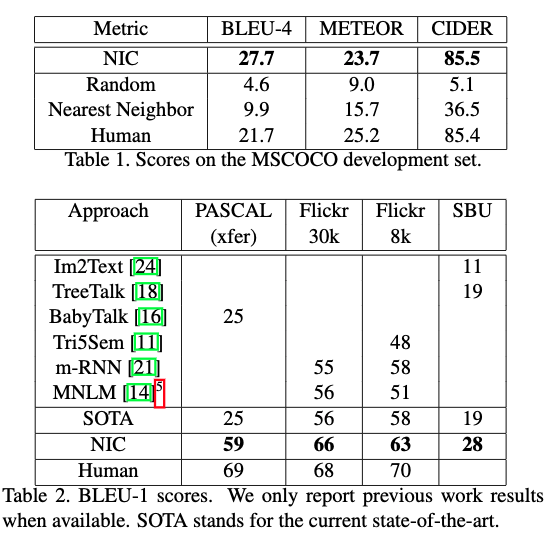
- 表2
- 人間によるスコアを示す.5人の評価者の平均である
- 機械翻訳でのスタンダードであるBLEU-4も示した
- 本手法は人間の評価者と近い値を出しているが,本手法の出力を人間の評価者に評価させると,本手法はもっと低い評価を得ており,もっと良い評価手法が必要であることがわかる
4.3.3 転移学習,データサイズとラベル品質
- (基本的に,ドメインが異なると転用できていないという結果が示されている.ドメインが同じならデータが多いほうが良い)
- モデルが学習時と異なるデータセットへ転用できるか調べる
- Flickr8kとFlickr30kがデータセットサイズについて最も明らかな例
- 30kは8kの4倍以上あり,BLEUが4ポイント上がった
- MSCOCOは30kの5倍のデータがある
- しかしデータ収集プロセスが異なり,語彙に差があるのでミスマッチが大きい
- BLEUは10ポイント落ちた
- しかし,生成された文章は妥当だった
- BLEUは10ポイント落ちた
- しかしデータ収集プロセスが異なり,語彙に差があるのでミスマッチが大きい
- PASCAL は訓練セットがないのでMSCOCOで訓練しており,Flickr30kで訓練した場合の結果はBLEU-1で53だった.(59から低下)
- MSCOCOのモデルでSBUをテストしたところ,28から16に落ちた
- Flickr8kとFlickr30kがデータセットサイズについて最も明らかな例
4.3.4 生成の多様性について議論
- 新しい文章を生成できるか,生成文は多様で,高品質かという問に答えたい
- 表3は,ビームサーチで得られたN個のbest listのサンプル.多様であることがわかる
- BLEUスコアは58で人間と同じくらい
- 文章が訓練例にあるものではないことに注意
- best candidateだけを採用すると,80%の確率で生成文は訓練例に存在するものになる
- 15(candidates)なら,(訓練例にある確率は)およそ50%になる
- 多様になったことでBLEUスコアが減少したりはしていない
- 表3は,ビームサーチで得られたN個のbest listのサンプル.多様であることがわかる

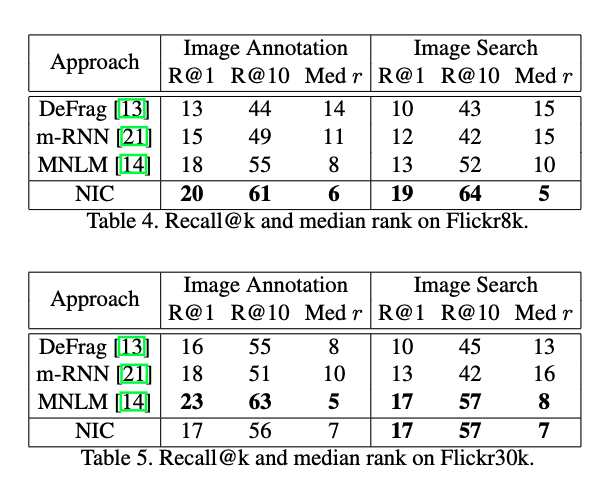
4.3.5 ランキング結果
- 本論文ではランキングが妥当な検証方法だと思っていない
- が,多くの研究で,テスト画像が与えられ,いくつかの候補キャプションをランキングする形で行われている
- MNLMというメトリクスを使う
- が,多くの研究で,テスト画像が与えられ,いくつかの候補キャプションをランキングする形で行われている
- ランキングは画像から説明をランキングするものと,説明から画像をランキングするものがあるが,どちらでも本手法は良い結果を示している
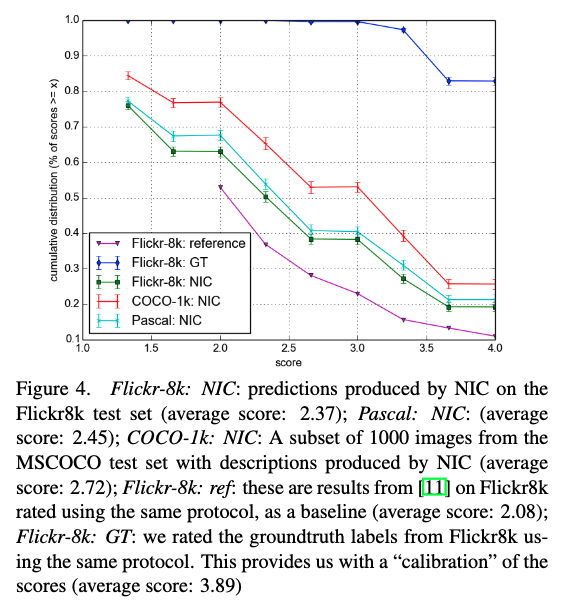
4.3.6 人間による評価
- 図4はNIC(提案手法)によって与えられた説明を人間が評価した結果
- 予想通り,NICは他のシステムより良く,正解より悪い.

4.3.7 埋め込みの解析
- 前の単語$S_{t-1}$をデコーダLSTMに入力して$S_t$を得るために,単語埋め込みベクトル[22]を使う
- 語彙のサイズが関係なくなるメリットが有る
- 埋め込みはモデル全体と同時に訓練できる
- いくつかの単語について,にた単語が学習された埋め込み空間中で近くに位置している(表)
- モデルが学習した関係が視覚パートを助けることに注意
- 馬,ポニー,ロバのような単語が近くに位置すれば,馬のような見た目の物体についてCNNが特徴抽出するのを助ける
- 例えばすごく珍しいクラス「ユニコーン」があったとして,埋め込み空間で馬という単語の近くに位置していれば,より多くの情報を利用できる
- bag-of-wordsベースでは失われてしまう情報を
- (CNNの特徴と単語特徴が同じ空間に配置されるので,たとえユニコーンのキャプションが訓練例にほとんどなくても,CNNが見たものが馬っぽければユニコーンという単語が生成されることもありうる,ということかと思う)
- 例えばすごく珍しいクラス「ユニコーン」があったとして,埋め込み空間で馬という単語の近くに位置していれば,より多くの情報を利用できる
- 馬,ポニー,ロバのような単語が近くに位置すれば,馬のような見た目の物体についてCNNが特徴抽出するのを助ける
