Structure Inference Net: Object Detection Using Scene-Level Context and Instance-Level Relationships
-
Yong Liu, Ruiping Wang, Shiguang Shan, Xilin Chen
-
CVPR 2018
-
本文
-
https://arxiv.org/abs/1807.00119
- 本記事で読んでいるのはv1
-
https://arxiv.org/abs/1807.00119
-
コード:
-
http://vipl.ict.ac.cn/view_database.php?id=6
- 2018年のStructure Inference Netのところにzipファイルへのリンクがある
-
http://vipl.ict.ac.cn/view_database.php?id=6
ひとことまとめ
どんなもの?
- 物体検出の精度向上のために,グラフ推定ネットワーク(RNN)を物体検出の後段に組み合わせた
先行研究と比べてどこがすごい?
- シーンと物体間関係という2種類のコンテキストを明示的にモデリングして,従来手法より高いmAP達成
技術や手法のキモはどこ?
- 物体をノード,物体間の関係をエッジとしてグラフをモデル内に構築.
- GRUの内部状態をノードの状態として,シーンおよび物体間関係(エッジ)情報の入力により内部状態を更新する.最後に内部状態からカテゴリと位置を推定.
- 訓練は通常の物体検出と同じ枠組みで行い,追加の正解データ等は不要
- どんな物体検出フレームワークにも適用できる
どうやって有効だと検証した?
- ベースラインにFaster R-CNN,本手法のベースにも同ネットワークを用い,Pascal VOC, MS COCOのmAPで比較.
議論はある?
- なし
次に読むべき論文は?
- 画像から構造化シーングラフを生成する(42)および,ION(3)が本手法と近いコンセプト
abst
- 視覚認知にはコンテキスト(物体の周りにあるものの情報)が重要
- 物体の見た目と,{シーンコンテキスト情報,物体間の関係}の2つのコンテキスト情報を利用する物体検出アルゴリズムを提案する
- 物体検出を,グラフ構造推定の問題として扱う
- 画像中の物体がノード,物体間の関係がエッジとしてモデリングされる
- Faster-RCNNのような物体検出器と,グラフィカルモデルを組み合わせる
- 画像中の物体がノード,物体間の関係がエッジとしてモデリングされる
- 物体検出を,グラフ構造推定の問題として扱う
- 物体の見た目と,{シーンコンテキスト情報,物体間の関係}の2つのコンテキスト情報を利用する物体検出アルゴリズムを提案する
- PASCAL VOC, MS COCOによる実験で,シーンコンテキストと物体関係により検出が改善することを示す
6. conclusion
- シーンコンテキストと物体関係情報を使う検出手法を提案した
- 実験により,シーンレベルコンテキストが検出に有効であると示された
- インスタンスレベルの関係が,localization精度も改善する
- VOCとCOCOの実験で,本手法が,もっとカテゴリの多い大規模リアルデータセットにも適用できる可能性があるとわかった
1. intro
-
既存の物体検出手法は画像中のROI周辺の局所的な情報しかみてこなかった
-
通常,画像はシーンコンテキストや物体間の関係といった情報をたくさん持っている
- これらを無視すれば物体検出精度は制限を受ける
- Faster R-CNNを使った例
- 海の写真でボートを車と誤検出した
- ノートPCを操作する写真で,マウスが検出されていない(図中では検出されている)

- ノートPCを操作する写真で,マウスが検出されていない(図中では検出されている)
- 海の写真でボートを車と誤検出した
- Faster R-CNNを使った例
- これらを無視すれば物体検出精度は制限を受ける
-
認識アルゴリズムは,コンテキストのモデリングを適切に行うことで改善することが報告されている(10, 14, 19, 41, 30, 29, 36)
- 2種類のコンテキスト情報の使用が研究された
- 物体周辺またはシーンレベルのコンテキスト(3, 43, 37)
- インスタンスレベルの物体間の関係(18, 4, 30)
- これらは同時に組み合わせられる
- 2種類のコンテキスト情報の使用が研究された
-
自然な画像中の物体はシーンや物体の関係の鍵となる要素で構造を形成していると仮説を立てた
- 例:ボートは川の上にあるとか,マウスはノートPCの近くにある
- これにより,物体検出は認識問題だけでなく,コンテキスト情報に基づいた推定問題となる
- 図2がこのアイデアを示すグラフ
- これにより,物体検出は認識問題だけでなく,コンテキスト情報に基づいた推定問題となる
- 例:ボートは川の上にあるとか,マウスはノートPCの近くにある
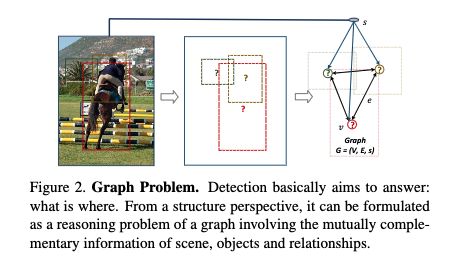
-
物体はグラフのノード,
-
物体間の関係はグラフのエッジ
- シーンコンテキストのもとで,これらの物体は互いに相互作用する
- あるオブジェクトがシーンや強く関連する他の物体からメッセージを受け取る
- これにより,外見だけでなくシーンコンテキストと物体関係により「物体の状態」が,定まる
- 「物体の状態」を使ってその物体のカテゴリや位置を決める
- これにより,外見だけでなくシーンコンテキストと物体関係により「物体の状態」が,定まる
- あるオブジェクトがシーンや強く関連する他の物体からメッセージを受け取る
- シーンコンテキストのもとで,これらの物体は互いに相互作用する
-
仮説を実現するためにstructure inference network(SIN)を提案する
- グラフ中の物体の状態を推定するネットワークである
- シーンや他の物体からのある物体へのメッセージをエンコードするのに,メモリセルを使う
- 本論文ではGRU(5)を使う
- 物体の表現をGRUの初期状態として,各種のメッセージを使って「物体の状態」を更新する
- シーンや他の物体からのある物体へのメッセージをエンコードするのに,メモリセルを使う
- 入力が物体とシーンレベルコンテキスト,インスタンスレベル関係の表現をカバーしている限り,SINは推定できる
- SINは特定の検出フレームワーク専用ではない
- グラフ中の物体の状態を推定するネットワークである
2. Related Work
物体検出
- CNNベースの物体検出は2タイプに分けられる
- region proposalベースの2ステージ手法
- R-CNN, Fast R-CNN, Faster R-CNN
- proposalなしの1ステージ手法
- SSD, YOLO
- region proposalベースの2ステージ手法
- 特に2ステージの手法では,画像中の異なる物体の検出がそれぞれ独立したタスクだと考えられていた
- その物体だけに関連する曖昧な特徴を使わなければならないことで,小さい物体の検出が難しい
コンテクスト情報
- Mottaghi et al.(29)はdeformable part baseのモデルを提案
- 各検出候補領域周辺の局所コンテキストと,シーンのグローバルコンテキストを利用する (3, 43, 37)が物体検出にDeep Convベースの手法を導入
- Shrivastave et al(37)はトップダウンコンテキストを提供するのにセグメンテーションを使用
- このコンテキストは領域提案と物体検出をガイドする
- (4)はオブジェクト同士の関係を利用したsequential reasoning アーキテクチャを提案
- シーンレベルコンテキストの考慮が弱い
- 本提案ではシーンレベルも物体間関係も両方モデリングでき,グローバルで構造的な視点から物体を推定できる
構造推定
- (28, 34, 23, 39, 21, 9, 2, 22, 42)がdeep手法と構造推定タスク用のグラフィカルモデルの組み合わせを提案している
- (21)は画像分類改善のためにシーンやオブジェクトや属性の関係を利用する汎用モデル
- (9)はグループactivity 認識において関係を解析する手法
- (42)は画像から構造化シーングラフを生成する推定モデル
- 本提案はこれと似ているが,技術的に異なる
- タスクドメイン固有である,グラフのインスタンス化,推定方法,メッセージパッシング,などが異なる
- 本提案はこれと似ているが,技術的に異なる
3. 提案手法
- コンテキスト情報により検出モデルを改善することを目指す
- 本モデルは物体間の関係とシーン情報を明示的に考慮する
- シーン全体および物体間の情報を繰り返して伝播するために構造推定ネットワークを考案した
- 本モデルは物体間の関係とシーン情報を明示的に考慮する
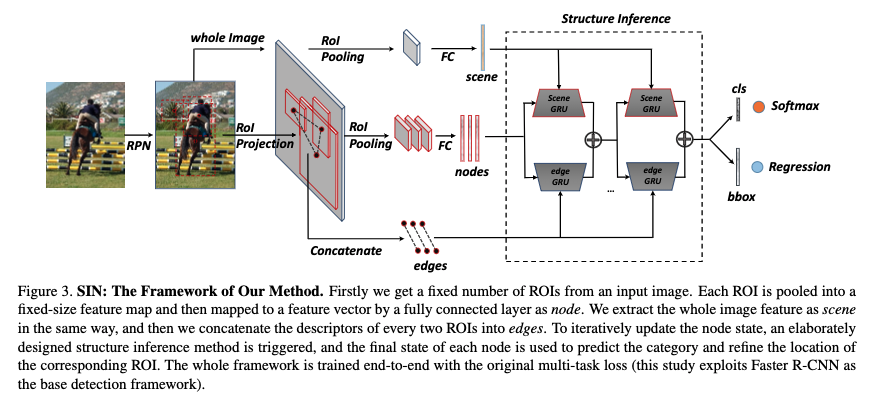
-
固定数のROIを入力画像から取る
- 各ROIは固定サイズのfeature mapにpoolされ,全結合レイヤによりfeature vectorにマップされる.これがノードになる
-
画像全体の特徴をシーンとして取る
-
すべての2つのROIの記述子をつなげたものをエッジとする
-
ノードの状態を更新するために,専用の推定手法を使う
- 最終状態が,対応するROIのカテゴリと位置の予測に使われる
- このフレームワークはend-to-endで,元と同じlossで訓練(ここではFaster R-CNNを使っているので,multi-task loss)
3.1. グラフィカルモデリング
- 本手法SINはベースとなる物体検出フレームワークを選ばないが,ここではFaster R-CNNを使う
- グラフ問題をモデリングするグラフ$ G = (V, E, s)$を図2に示す
- ノード$ v \in V$は領域提案
- $ s$は画像のシーン
- $ e \in E$は物体ノードの関係(エッジ)
- 各ROI$ v_i$について,全結合レイヤとROI poolinレイヤで視覚特徴$ f_i^v$を抽出する
- 画像に関するシーン$ s$については正解シーンラベルというものはないので,画像全体の視覚特徴$ f^s$がノード同様の操作で,シーン表現として抽出される
- ノード$ v_j$から$ v_i$への 有向エッジ$ e_{j \rightarrow i}$については,$ v_j$と$ v_i$の空間特徴(ROIの位置),視覚特徴(ROIの内容)両方を使って,スカラーを計算する
- これは$ v_j$から$ v_i$への影響力を表す
3.2. メッセージパッシング
-
各ノード(=オブジェクト)について,インタラクションの鍵はシーンと自身以外のノードからのメッセージパッシングをエンコードすることである
- ノードは複数のメッセージを受け取るので,自分自身を忘れず,入力されるメッセージを意味のある表現に融合する関数が必要
- これは記憶装置のように振る舞うので,RNNを使う
- GRU(5)は軽量で効率的なRNNなので,これを用いる
- (GRUの復習が書かれているが,省略する)
- GRUのメモリセルは,入力レイヤと無関係な情報はリセットゲートで消去できる
- また,前の状態からどれくらいの情報を持ってくるかをアップデートゲートで調節できる
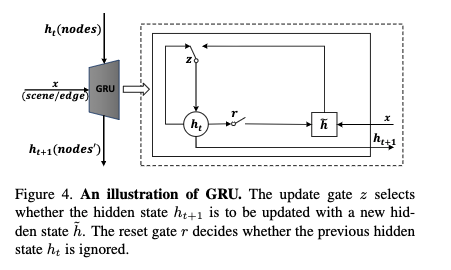
- (GRUの復習が書かれているが,省略する)
- GRU(5)は軽量で効率的なRNNなので,これを用いる
- これは記憶装置のように振る舞うので,RNNを使う
- ノードは複数のメッセージを受け取るので,自分自身を忘れず,入力されるメッセージを意味のある表現に融合する関数が必要
-
一般に,GRUの初期状態は,empty(ゼロ/単位ベクトル?)か,ランダムベクトルで,入力がシンボル系列
- 本手法では,物体状態に対して色々なメッセージ(単に情報と読み替えて差し支えないと思う)をエンコードするために使う
-
シーンからのメッセージのエンコード:
- 物体の詳細をGRUの初期状態とし,シーンからのメッセージを入力する
-
他の物体からのメッセージのエンコード:
- 物体の詳細をGRUの初期状態,他のノードからのメッセージを統合したものを入力とする
-
シーンからのメッセージのエンコード:
- 物体の状態が更新された時,物体間の関係も変化し,タイムステップが経過するほどモデルは安定する
- (物体の状態とよんでいるものについて:GRUの集まりであるモジュールを使って,画像内の物体1つに関して1つの状態を計算,その状態からクラスと位置を予測する.したがって画像内の各物体について状態を計算することになる)
- 本手法では,物体状態に対して色々なメッセージ(単に情報と読み替えて差し支えないと思う)をエンコードするために使う
3.3 構造推定
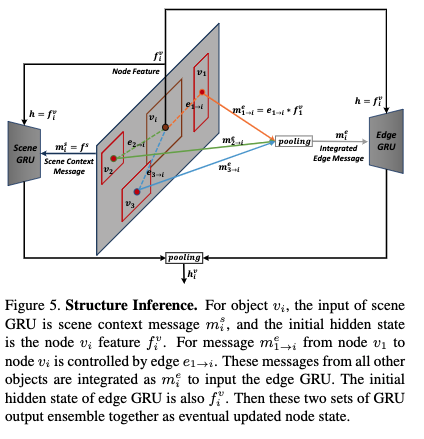
- シーンと物体からのメッセージをエンコードしてnodeに渡すため,scene GRUとedge GRUを設計する
- scene GRUは視覚特徴$ f^v$を初期隠れ状態とし,シーンメッセージ$ m^s$を入力する
- このメッセージはシーンコンテキスト$ f^s$そのものである(図5)
- edge GRUは他の物体からのメッセージをエンコードするが, 統合メッセージ$ m_e$を計算する必要がある
- 他の物体たちから逐一メッセージを入力したとすると,計算コストが高くなるから
- 他の物体たちはそれぞれ異なるcontributionをしているので,すべての物体間の関係$ e_{j \rightarrow i}$をスカラーの重みとしてモデリングする
- $ v_j$から$ v_i$への影響を表す
- 物体間の関係$ e_{j \rightarrow i}$は共通に,相対的物体位置と視覚特徴から決定される
- (これによりマウスとキーボードの関係はカップとキーボードより重要,近い位置にあるマウスは遠い場合より重要,などが成り立つはずなので妥当である)
- 他の物体たちから逐一メッセージを入力したとすると,計算コストが高くなるから
- 図5右側のように,統合メッセージは次式
- scene GRUは視覚特徴$ f^v$を初期隠れ状態とし,シーンメッセージ$ m^s$を入力する
\begin{align}
m_i^e &= \underset{j\in V}{maxpooling} (e_{j\rightarrow i} * f_j^v) \tag{5} \\
e_{j\rightarrow i} &= relu(W_p R_{j\rightarrow i}^p) * tanh(W_v \left[ f_i^v, f_j^v \right]) \tag{6}
\end{align}
- .
- .
-
$ W_p$と$ W_v$は学習可能重み
-
maxpoolingを使っているので,最も重要なメッセージのみを抽出する
-
視覚表現ベクトルは視覚特徴$ f_i^v$と$ f_j^v$をconcatenationして作る
-
$ R_{j \rightarrow i}^p$は空間位置関係を表す
- $ R_{j \rightarrow i}^p = \left[ w_i, h_i, s_i, w_j, h_j, s_j, \frac{(x_i -x_j)}{w_j}, \frac{(y_i - y_j)}{h_j}, \frac{(x_i -x_j)^2}{w_j^2}, \frac{(y_i - y_j)^2}{h_j^2},log(\frac{w_i}{w_j}),log(\frac{h_i}{h_j}) \right] \tag{7} $
-
$ (x_i, y_i)$はROI$ b_i$の中心
-
$ w_i, h_i$は$ b_i$の幅と高さ
- $ s_i$は$ b_i$の面積
-
- ノード$ v_i$は,他のノードとシーンコンテキスト両方からメッセージを受け取る
- 最終的にノード状態を表す包括的表現$ h_{t+1}$を得る
- 経験的に,ここではmean-poolingが効率的である
- $ h_{t + 1} = \frac{h_{t+1}^s + h_{t+1}^e}{2} \tag{8}$
- $ h_{t+1}^s$はscene GRUの出力,$ h_{t+1}^e$はedge GRUの出力
- 続くiterationで,scene GRUは新しいノード状態($ h_{t+1}$)を隠れ状態とし,固定のシーン特徴を入力し(シーン特徴$ f_s$の計算に全結合レイヤを使うので,固定にならないのでは?),次のノード状態を計算
- edge GRUは新しい物体間メッセージを入力し(統合メッセージの計算がある),次の隠れ状態を計算
- 最後に,統合されたノード表現がオブジェクトのカテゴリとbounding boxのオフセットを推定するために使用される
- 経験的に,ここではmean-poolingが効率的である
- 最終的にノード状態を表す包括的表現$ h_{t+1}$を得る
- .
4. Results
- PASCAL VOC(12)とMS COCO(26)でSINを評価する
4.1. 実装の詳細
- ImageNet(8)で事前訓練したVGG-16を使う
- 128個のboxを物体提案として選ぶためにNMS(13)を使う
- ベースラインとしてFaster R-CNNを訓練する
- SINおよびFaster R-CNNはtensorflowで実装した
- (パラメタの詳細が書かれているが省略)
4.2. 全体の性能
PASCAL VOC
- カテゴリが20個ある
- VOC 2007は,trainvalが5000件,testが5000件の画像からなる
- VOC 2012は,trainval 11000件,test 11000件
- 本手法により,ベースラインより良い,2007で76.0%のmAP,2012では73.1%のmAPを達成した
- 特に,2007 testで,RNNで明示的にコンテキストをモデリングするマルチスケールネットワーク(本手法と近い)であるION(3)よりも良い結果を出した
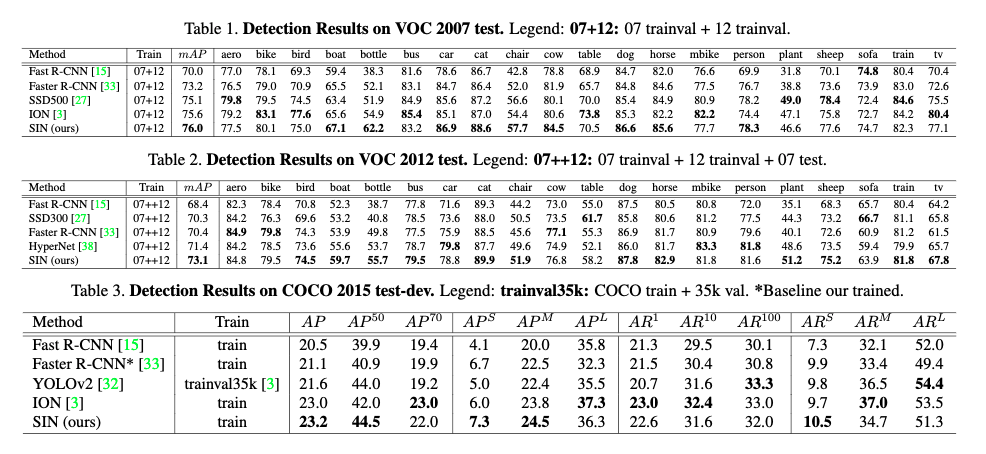
MS COCO
- test-dev 2015 evaluation serverを使った評価結果を表3に示す
- COCOは VOCとmAPの計算方法が異なり,位置の正確さに対して非常に重きを置いている
- SINはtest-devで23.2%を達成し,本手法の有効性を示した
- COCOは VOCとmAPの計算方法が異なり,位置の正確さに対して非常に重きを置いている
5. 設計の評価
- 本手法の設計の効果を検証する
- ここでは,本モデル内のシーンコンテキストを利用するモジュールをScene, 物体間関係を利用するモジュールをEdgeと呼ぶ
5.1. Scene モジュール
- scene GRUだけを使って構造推定することで,シーンコンテキスト情報だけをノード特徴の更新に使う
性能
- 表4.すべての結果はVOC 2007 train-valで訓練し,testでテストしたもの
- Scene モジュールは70.23% mAPで,ベースラインよりよい
- 飛行機,鳥,ボート,テーブル,tvなど特定のカテゴリで目立った成果を得ている
- 鳥や飛行機は空にあり,ボートは川にある,というシーンコンテキストを利用した結果である
- 飛行機,鳥,ボート,テーブル,tvなど特定のカテゴリで目立った成果を得ている
- Scene モジュールは70.23% mAPで,ベースラインよりよい

小さい,曖昧または隠された物体
-
(20)による検出解析ツールを使ってベースラインとの差をさらに調べる
- 図6は検出対象の条件により結果が受ける影響を示しており,ベースラインより提案手法がロバストであることがわかる
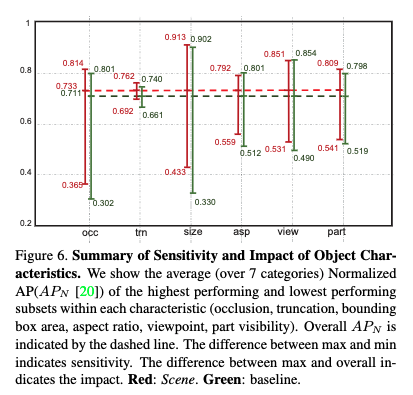
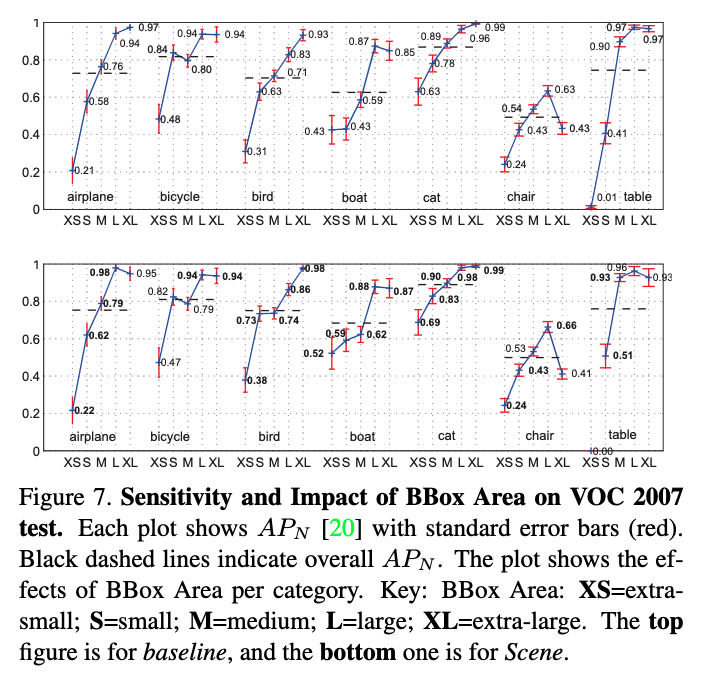
-
図7は更に特定の解析を行い,本手法は非常に小さい鳥,ボート,猫カテゴリで他のサイズよりよい性能を示していることがわかった
Sceneの質的結果
- Sceneモジュールが検出を改善する例を図8に示す
- ベースラインはいくつかのボートを車と判定したが,本手法は正しくラベルづけできた
- ベースラインは何も検出していない場所で,本手法は椅子を検出できた
- 川の中に飛行機があるという珍しい状況で,ベースラインは正しく分類できたが,本手法は失敗してボートとした

5.2. Edge モジュール
- Edgeモジュールの効果を評価する
- Sceneのとき同様,edge GRUだけを使ってノードをアップデートする
位置検出
- Scene同様,(20)の解析ツールを用いる
- ほとんどのカテゴリでベースラインより正確な位置検出ができている
- 図9は誤検出の種類と性能に与える影響を示したものであり,Edgeにより位置検出エラーが大きく減少していることがわかる
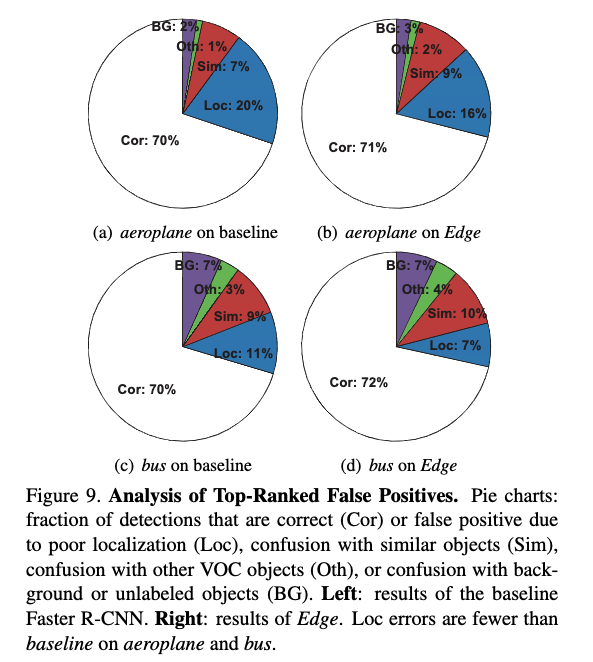
Edgeの質的結果
- ベースラインは似たカテゴリの2つ以上のボックスに1つの物体が囲まれるというエラーがよく起こる
- Faster R-CNnは候補領域に対して,可能なカテゴリそれぞれにつき,regression boxを予測する手法を取っているため
- 図10に示すように,Edgeではこのようなエラーが大きく減少.
- 重複するノード間の関係はそれら自体が同一だと判断できるため.

- 図10に示すように,Edgeではこのようなエラーが大きく減少.
- Faster R-CNnは候補領域に対して,可能なカテゴリそれぞれにつき,regression boxを予測する手法を取っているため
関係する物体の視覚化
- edge GRUの入力は関連する物体たちからの情報を統合していると述べた.
- 相対的な物体間関係が学習されていることを確認する
- エッジ$ e_{j\rightarrow i}$を使って物体の関係を可視化する
- 各ノード(=物体)[$ v_i$について,最大の$ e_{j\rightarrow i}$を探す
- ノードiとノードjが正しく物体を検出していれば,box iとjを接続する破線を描く
- これはbox iとjが強い関係を持つことを示す
- ノードiとノードjが正しく物体を検出していれば,box iとjを接続する破線を描く
- 各ノード(=物体)[$ v_i$について,最大の$ e_{j\rightarrow i}$を探す
- エッジ$ e_{j\rightarrow i}$を使って物体の関係を可視化する

- 相対的な物体間関係が学習されていることを確認する
5.3. アンサンブル
- SceneとEdgeの隠れ状態[$ h^s]と[$ h^e]を組み合わせる方法は何がいいか
アンサンブルの方法
- mean-poolingが良い.
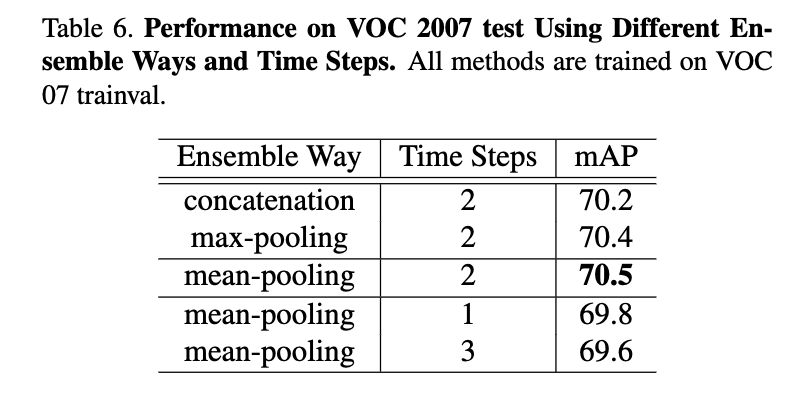
更新のタイムステップ
- タイムステップ2で最も高い性能を出した.
- それ以上になると次第に悪化する
- それ以上は,グラフが閉じたループになるから
- それ以上になると次第に悪化する
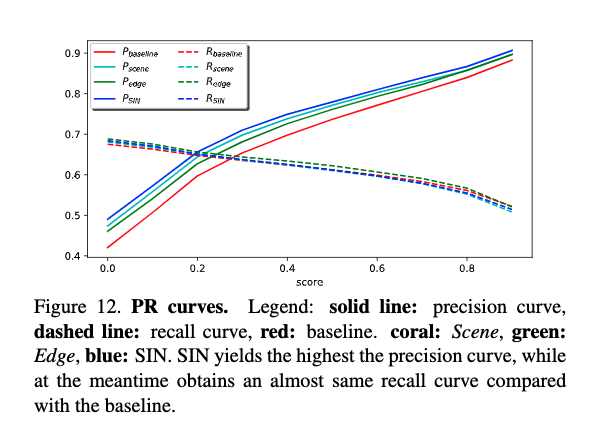
PRカーブの性能
- 本手法の性能指標について
- 検出スコア(0: 0.1: 0.9)について,global precisionとrecallを計算した
- 図12にPRカーブを描く
- SIN(Scene & Edge)がprecisionが高く,recallはベースラインと同じくらい
- この理由として,コンテキストの制約が加わったことで,「道路上のボート」のような珍しいサンプルでの正解を難しくしていることが挙げられている(ここで間違うのでrecallが増えない)
- (precisionとrecallはもともとトレードオフの関係にあるので,これがなかったとしても自然な気はする)
- この理由として,コンテキストの制約が加わったことで,「道路上のボート」のような珍しいサンプルでの正解を難しくしていることが挙げられている(ここで間違うのでrecallが増えない)
- SIN(Scene & Edge)がprecisionが高く,recallはベースラインと同じくらい
- 図12にPRカーブを描く
- 検出スコア(0: 0.1: 0.9)について,global precisionとrecallを計算した