- 物体検出モデルYou Only Look Onceの論文の要約.
- 図表にも省略あり.
- "You Only Look Once: Unified, Real-Time Object Detection"
- Joseph Redmon, Santosh Divvala, Ross Girshick, Ali Farhadi
- CVPR 2016, OpenCV People's Choice Award
- arxiv
- 著者のプロジェクトページ
- darknetのgithub
abst
- 従来の分類ベースの手法に検出させるものと違い,yoloはbounding boxに対する回帰として設計している
- 単一のNNが一回の評価でbboxとクラス確率を予測する
- end2endで直接最適化できる
- 単一のNNが一回の評価でbboxとクラス確率を予測する
- YOLOは45fps, Fast YOLOは155 fpsの速度がある
- 他のsota手法よりもYOLOは位置エラーが大きいが,背景に対するfalse positive(誤検知)が少ない
- 自然画像やartworkのようなドメインでDPMやR-CNNを凌ぐ
6. conclusion
- classifier baseの手法と違い,検出性能と直接対応する誤差関数で訓練される
1. intro
- 既存の手法はclassifierにdetectionさせようとしている.
- deformable part model(DPM)はスライディングウィンドウ方式(10)
- R-CNNは領域提案とclassifier, bounding boxのrefinementの組み合わせ
- これらの手法は個別の構成要素を訓練するので最適化が難しい
- そこでyoloはdetection問題を,pixelからbox座標とクラス確率への回帰問題にした.この利点は次の通り
- 極めて高速.TitanXで45fps.高速版は150fps以上
- 推定が画像全体をglobalに捉えて行われる.context情報等を利用できている
- これにより,背景を誤検知する数がFast R-CNNの半分以下に
- ドメインを超えた物体の一般的表現を学習できる.自然画像を学習し,art workに適用したところ,他の手法を引き離す性能.
- デメリットは,特に小さい物体では位置特定の精度が悪いこと
2. unified detection
-
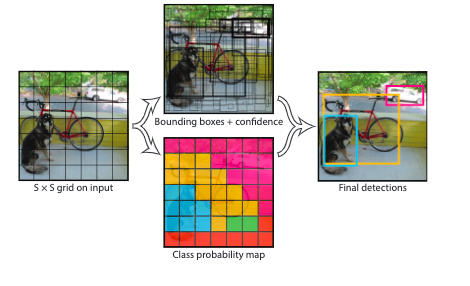
yoloは画像をS x Sのグリッドに分割する.グリッドはそれぞれがB個のbboxとそのconfidenceを予測.
- confidence スコアは$ Pr(Object) * IOU$ .
- objがなければ0, あるならIOUそのものがconfidenceスコアになるように訓練.
-
bboxはx,y, w, h とconfidenceの5つからなる.x,yは各グリッドセルの境界からbbox中心への相対座標.(画像全体の相対座標ではない.v3では変更されている?)
- confidenceはpredictionと正解bboxとのIOU.
-
各グリッドセルがC個の条件付きクラス確率$ Pr(Class_i | Object)$を予測する.各グリッドにつきBox数はB個あるが,その数に関わらずclass probability各グリッドにつき1セットしか推定しない.
- ? これだと1グリッドに1物体しか出せないことになるのでは?
-
テスト時にはクラス確率とIOU予測confidenceスコアをかけることで,クラスごとのconfidenceスコアが出せる
-
$ Pr(Class_i | Object) * Pr(Object) * IOU_{pred}^{truth} = Pr(Class_i) * IOU_{pred}^{truth} \tag{1}$
- クラスの確率と,どれくらいその物体にboxがフィットしているかという情報をencodeしていることになる
- クラスの確率と,どれくらいその物体にboxがフィットしているかという情報をencodeしていることになる
-
出力はS x S x (B * 5 + C)テンソルになる
- Sは画像のSxSグリッド分割数
- Bは1グリッドあたりのbounding box数
- Cはクラス確率.
- 1 bounding boxはx, y, w, h, confidenceの5次元ベクトル
-
PASCAL VOCで評価したとき,S=7, B= 2, C=20を使ったので,このときのpredictionは7x7x30 tensor.
2.1. Network Design

- アーキテクチャはGoogLeNetにインスパイアされている(34).
- convolutionが24レイヤ,その後2つの全結合.
- Fast YOLOではconvが9レイヤ
2.2. Training
- convレイヤは最初の20レイヤをImageNet でpretrainした.
- 約1weekかかり,top5 accが88% (ImageNet 2012 validation set)
- 訓練は224x224で,推定は448x448でやったぽい
- 最後のlayerだけrelu, あとはrealy relu.
\phi(x) = \begin{cases} x, \quad if \quad x>0 \\ 0.1x, \quad otherwise \end{cases}
- 誤差関数はsum-squaredだが,これはclassificationとlocalizationを等しく扱ってしまうので良くない.
- 多くの場合,グリッドセルの多くは物体を含まない.このことはconfidenceをzeroに向かわせ,物体があるセルからの勾配を圧倒することがある.これにより訓練は不安定になり,早期に発散する
- これを解決するため,座標予測のlossは増加させ,confidence予測のlossは減少させるように$ \lambda_{coord}=5, \lambda_{noobj}=0.5$を導入した.
- boxが大きいときのズレは,小さい時のズレに比べれば問題ない.これを訓練に反映させるために,bboxの高さと幅はそれらの値のsqrtを予測することにした.
- 多くの場合,グリッドセルの多くは物体を含まない.このことはconfidenceをzeroに向かわせ,物体があるセルからの勾配を圧倒することがある.これにより訓練は不安定になり,早期に発散する
- yoloではグリッドセル当たりに複数のbounding boxを予測するが,いくつものbounding boxが1つの物体を囲まないようにしたい.
- 訓練時には,iouが最も高くなるbounding box1つだけががその物体を担当するように訓練する.これにより,bounding boxの専門化が起きる.特定の物体,比率,サイズに対して特定のbox predictorが対応するようになる
- 訓練の誤差は次の通り
\lambda_{coord} \sum_{i=0}^{S^2}\sum_{j=0}^{B}\mathbb{1}_{ij}^{obj}((x_i - \hat{x_i})^2 + (y_i - \hat{y_i})^2) \\
+ \lambda_{coord} \sum_{i=0}^{S^2}\sum_{j=0}^{B}\mathbb{1}_{ij}^{obj}((\sqrt{w_i} - \sqrt{\hat{w_i}})^2 + (\sqrt{h_i} - \sqrt{\hat{h_i}})^2) \\
+ \sum_{i=0}^{S^2}\sum_{j=0}^{B}\mathbb{1}_{ij}^{obj}(C_i - \hat{C_i})^2 \\ + \lambda_{noobj}\sum_{i=0}^{S^2}\sum_{j=0}^{B}\mathbb{1}_{ij}^{noobj}(C_i - \hat{C_i})^2 \\
+ \sum_{i=0}^{S^2}\mathbb{1}_{i}^{obj} \sum_{c \in classes}(p_i(c) - \hat{p_i}(c))^2 \tag{3}
-
$ \mathbb{1}_i^{obj}$ は物体がcell iにあるかどうかを示す
-
$ \mathbb{1}_{ij}^{obj}$ はcell i のj番目のpredictorが予測を担当することを示す
-
物体がそのグリッドセルに存在するなら,誤差関数はclassification誤差のみを罰する.
-
訓練は135epoch, データはPascal VOC 2007 と2012のtrainingとvalidation.
- batch_size =64, momentum = 0.9, decay = 0.0005
- 学習率が最初に高いと発散するので次第に上げる(省略)
-
最初の全結合に0.5のdropoutと,random scalingとtranslationを元画像の20%まで行うaugmentation
- HSVで1.5倍までのrandom明度・彩度調整
2.3. Inference
2.4. Limitations of YOLO
- 鳥の群れのような小さい物体のグループには弱い.
- 今回の実験ではB=2なのでSxSx2しかbboxが出ないから
- 見たことのないアスペクト比,configurationには弱い
- modelの設計上,レイヤのdownsampleによって,推定には荒い特徴を使っている
- 小さいbboxと大きいbboxでエラーは等しく扱ってしまう
- 大きいboxでの小さい間違いは良性だが,小さいboxで起きるとIOUに大きく響く.yoloのerrorの原因は位置に関するものである
3. Comparison to Other Detection Systems
deformable parts models(DPM)(10)
- スライディングウィンドウを用いる
- 一方yoloは特徴抽出,box予測,non maximal suppression, 文脈推定,を同時に1つのネットワークで行い,DPMよりも正確である
R-CNN
- selective searchによる領域提案, CNN特徴抽出, SVMによるboxスコアリング,線形モデルによるbox調整,non max suppressionによる重複除去というパイプラインを行う.
- 推定時間が40秒以上かかる
- yoloは今回の実験では98個しかbboxを出さない.RCNNは2000以上出す.
Fast, Faster R-CNN
- どちらもselective searchをNNに置き換えている.RCNNより速いがリアルタイムは無理
Deep MultiBox
- Selective searchではなくCNNを使う.一つの物体の検出ができるが汎用ではない
OverFeat
- sliding window検出を使う.パイプラインシステムである.
- detectionではなくlocalizationを最適化する(?)
- 局所しか見ないのでグローバルコンテキストが見れない
MultiGrasp
- 物体を含む一握りの領域だけ予測する.サイズ,位置,境界,およびクラスは予測しない.
- yoloと共通点が多い(著者が同じなので多分MultiGraspを元に設計されている)
4. Experiments
- VOC2007のエラー解析をYOLOとFast R-CNNで行う
- YOLOでFast R-CNNの予測を改善する実験を行う
- VOC2012でsotaモデルと比較する
- artworkデータセットでyoloのgeneralization能力を見る
4.1. Comparison to Other Real-Time Systems
- Fast YOLO
- 52.7% mAPでリアルタイム検出の従来手法の2倍の精度(PASCAL)
- YOLOはmAP 63.4% (PASCAL)
- YOLOはVGG-16を使って訓練すると精度が上がるが,普通のYOLOより遅くなる(リアルタイム不可)
- Faster R-CNNは7fps.軽量版は精度が劣るが18fps
- VGG-16版は10mAPだけ高いが,YOLOより6倍遅い
4.2. VOC 2007 Error Analysis
- yoloは物体の位置特定に難あり.
- Fast R-CNNはYOLOより位置特定エラーが少ないが,backgroundの取り違えがかなり多い.(13.6%がなにもない領域を検出している)
4.3. Combining Fast R-CNN and YOLO
- Fast R-CNNによるbackgroundの取り違えをYOLOで取り除くと性能が上がる
- (この実験はyoloにFast R-CNNの検出結果を渡しているだけで,YOLOが背景の取り違えが少ないことを示すためにやっている)
4.4. VOC 2012 Results
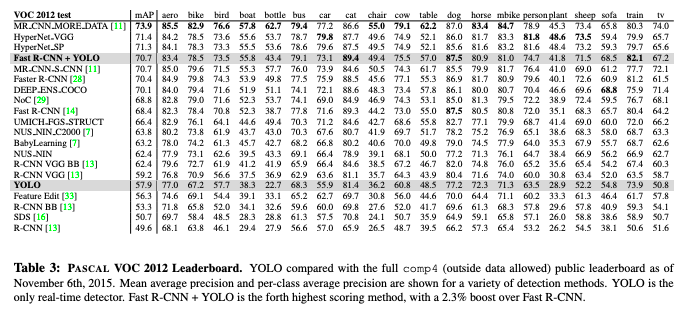
- YOLOはVOC2012 test setで57.9%のmAPであり,sota(MR_CNN_MORE_DATA(11), 73.9)より低いが,R-CNN using VGG-16 (59.2%)に近い.
- yoloは小さい物体で苦戦している.
4.5. Generalizability: Person Detection in Artwork
- 実験のデータはtrainとtestでドメインが変わらないが,現実にはドメインが変わることがある.
- RCNNはVOC2007でAPが高いが,artworkデータに適用すると性能が出ない
- selective searchがnatural imageでtuneされているから
- DPMはRCNNほど落ちない
- YOLOはVOC2007でも良いし,artworkでもそれほど落ちない.
- yoloはglobalに見ることができるので,artwork(pixelレベルでは自然画像と違うが,物体形状やサイズが似たような)にも良い性能が出る.
5. Real-Time Detection In The Wild
- webcamに接続してリアルタイム処理できる
References
- [11] Object detection via a multi-region & semantic segmentation-aware CNN model
- Spyros Gidaris, Nikos Komodakis, 2015.
- https://arxiv.org/pdf/1505.01749.pdf
- 本論文時点でのVOC2012 test 物体検出sota