以下の論文の内容をまとめた。
Vision GNN: An Image is Worth Graph of Nodes 2022/06
https://arxiv.org/abs/2206.00272
Kai Han, Yunhe Wang, Jianyuan Guo, Yehui Tang, Enhua Wu
パッチ化した画像でグラフを構築し、グラフニューラルネットワークで特徴抽出、画像分類や物体検出タスクに利用する。TransformerやMLPを使った画像処理の研究とコンセプトは似ている。
まとめ
前提/課題
- CNN, transformer, MLP, 等を利用してコンピュータビジョンモデルが改善されている
- 画像中の物体は通常、形状が不規則で四角形ではないため、ResNetやViTなどの従来のネットワークで一般的に使われているグリッドやシーケンス構造は、冗長で柔軟性がなく、処理しにくい
提案
- 画像をグラフ構造として表現することを提案し、視覚タスクのためのグラフレベルの特徴を抽出する新しいVision GNN(ViG)アーキテクチャを導入
- 画像を、ノードと見なせるいくつかのパッチに分割し、近傍のパッチを連結してグラフを構成
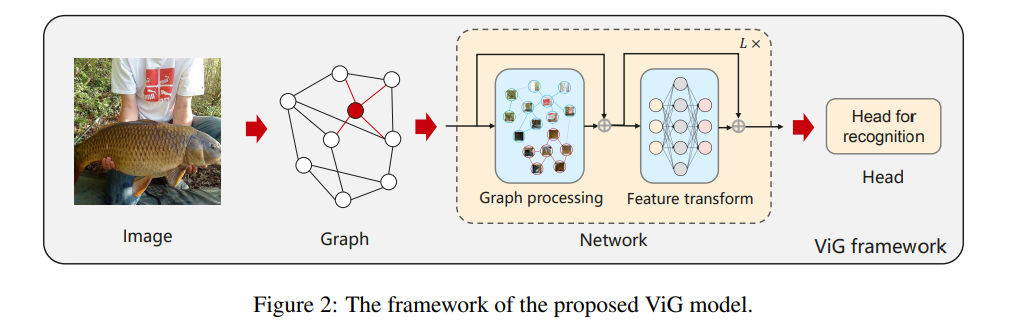
- 画像のグラフ表現に基づき、全てのノード間で情報の変換と交換を行うViGモデルを構築。ViGは2つの基本モジュールから構成
- グラフ情報の集約と更新を行うグラフ畳み込みモジュール
- ノードの特徴変換を行う2つの線形層からなるFFNモジュール
- 画像認識と物体検出タスクに関する広範な実験により、提案手法のViGアーキテクチャの優位性を実証
画像パッチを(a)グリッド構造, (b)シーケンス構造, (c)グラフ構造, として表現した概念図。グリッド構造ではパッチは元の画像での空間的位置関係が保持され、シーケンス構造では2Dの画像がパッチの系列になる。グラフ構造ではパッチの内容によってノードの接続が変わるため、空間的な位置に制約されない。
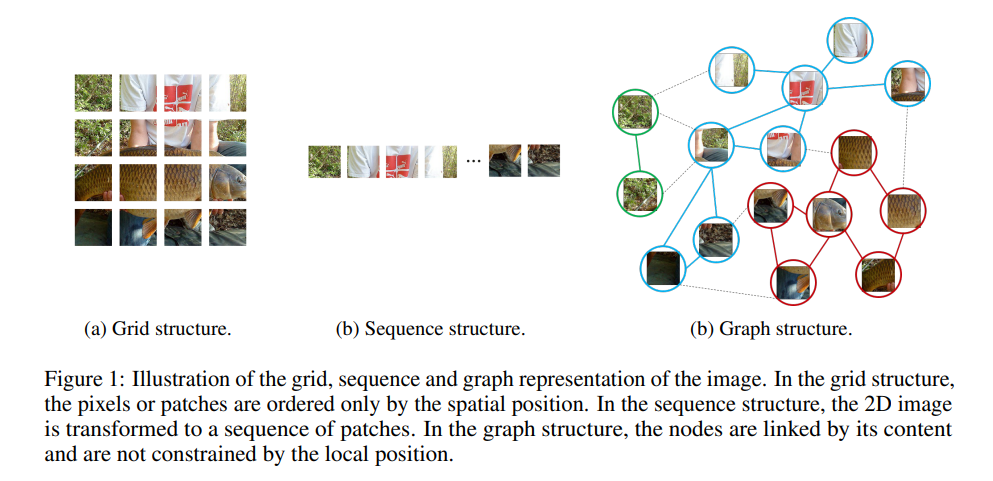
詳細
モデル
- グラフ畳み込み
- 画像をN個のパッチに分割して特徴ベクトルに変換し、それらを無順序ノード集合とみなす
- 各ノードviについて、そのK個の最近傍N (vi) を求め、全てのvj∈N (vi)についてvjからviに向けられたエッジejiを追加する
- グラフ畳み込みを適用。隣接ノードの特徴を集約することで、ノード間の情報交換を行う
- マルチヘッド更新操作を導入する(集約された特徴量をh個のheadに分割し、それぞれ異なる重みで更新したあとで結合する)
- 画像をN個のパッチに分割して特徴ベクトルに変換し、それらを無順序ノード集合とみなす
gは以下に示すグラフ畳み込み(max-relative graph convolution)。W_aggとW_updateはそれぞれ集約操作と更新操作の学習可能な重み。N(xi)はノードxiのK個の最近傍。
マルチヘッド更新操作。x''をh個のheadに分割し、異なるWで更新して結合
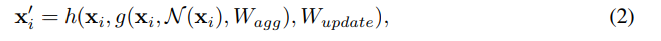
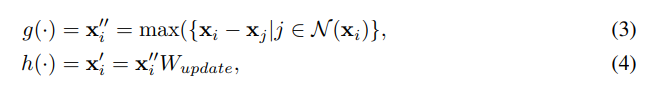
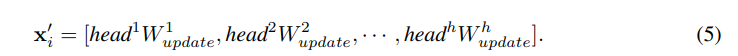
- GNNのover smoothing問題を緩和するため以下の処理を行う。ViGブロックと呼ぶ
- グラフの畳み込みの前後に線形レイヤーを適用し、ノード特徴を同一領域に投影し、特徴の多様性を向上させる。グラフ畳み込み後には非線形活性化関数を適用し、入力特徴のスキップ接続を加算。これをGrapherモジュールと呼ぶ
- Grapherモジュールの出力に対してFFNを適用する。こちらも入力のスキップ接続を加算する。こちらはFFNモジュールと呼ぶ。
Grapherモジュールの式。GraphConvは上記の(2)~(5)式の操作。σは活性化関数、W_in, W_outは完全連結層の重み。
FFNモジュールの式。W1とW2は完全連結層の重み。
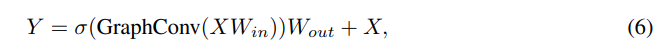

- モデル構造
- transformerで一般的な等方性アーキテクチャとCNNのようなピラミッドアーキテクチャの2種類を検証
- 2つのアーキテクチャともに、各ノードの特徴量に位置符号化ベクトルを加算する(absolute positional encoding)
提案手法ViGのフレームワーク。
実験/結果
- ImageNet ILSVRC 2012の画像分類
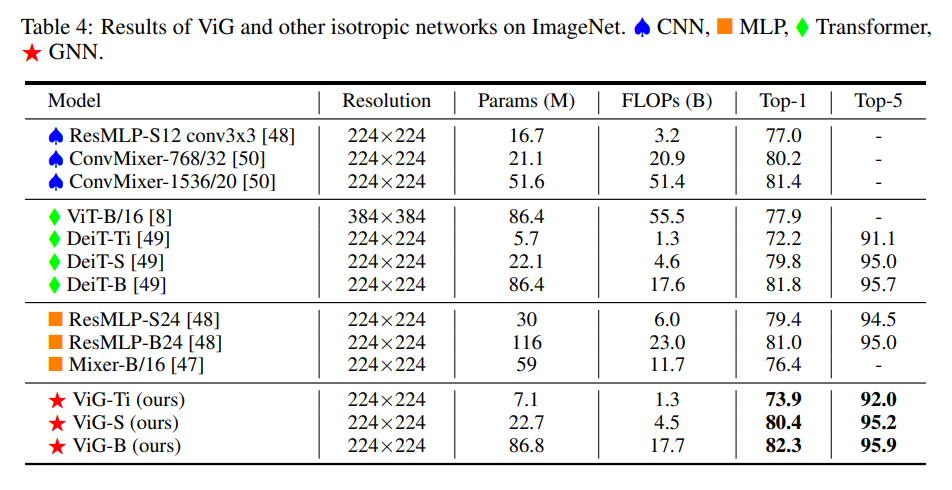
- ImageNet calssficationタスクにおいて82.1%のトップ1精度を達成し、代表的なCNN (ResNet), MLP (CycleMLP), transformer (Swin-T) と同等のFLOPs (About 4.5G) を上回る性能
ImageNet画像分類での提案手法ViGと他の等方性モデルの結果。同程度のサイズ(Ti, S, B)のモデルと比較し、提案手法が最も高いスコアを示している。
- COCO物体検出
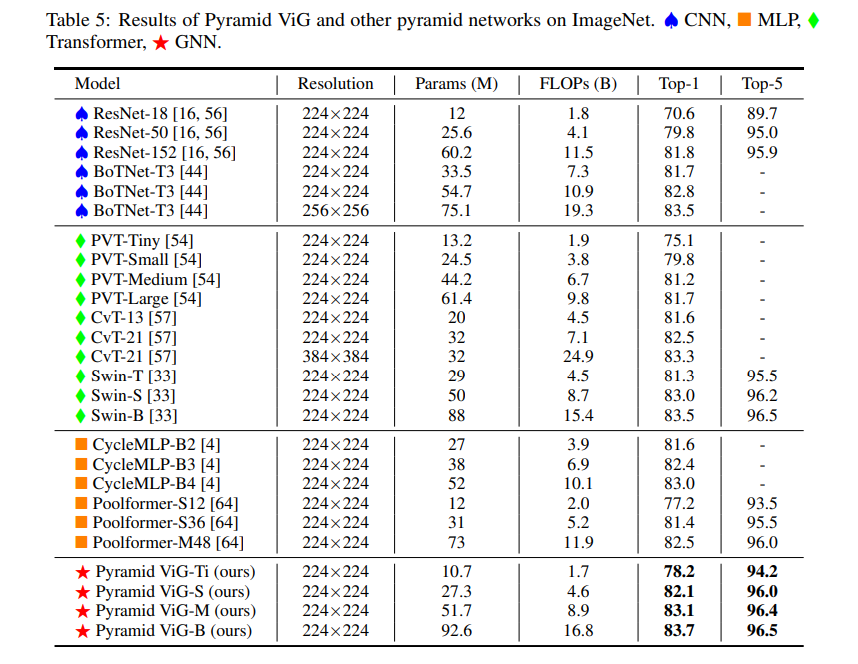
- RetinaNetとMask R-CNNの両方において、ResNet, CycleMLP, Swin Transformerなど異なるタイプの代表的なバックボーンより優れた性能
COCO物体検出でのPyramid ViGと他のピラミッド型モデルの結果。同程度のサイズ(Ti, S, M, B)のモデルと比較し、提案手法が最も高いスコアを示している。
- 提案手法で構築されたグラフ構造を可視化
- 浅い層では、色やテクスチャなどの低レベルで局所的な特徴に基づいて近傍ノードが選択される傾向
- 深層部では、中心ノードの近傍はより意味的で、同じカテゴリに属している傾向
構築されたグラフ構造の可視化。星型が中央ノードで、同じ色のノードはグラフにおいて近傍ノードとなっている。(a)が入力画像、(b)1番目のブロックで構築されたグラフ, (b)12番目のブロックで構築されたグラフ(より深い層にある)。

告知
この記事は「Qiita Engineer Festa 2022」に参加しています。