はじめに
protobufことProtocol Buffersは、軽量で高速であることがよく利点として挙げられています。公式のドキュメントにも、「XMLのようで、しかし軽量で速くシンプルである」と述べられています。
think XML, but smaller, faster, and simpler
しかし、これは本当でしょうか?
そこまでいうならとバイナリを覗いてみようではないですか(?)
バイナリの眺め方
まずは、protobufの実際のバイナリを眺める方法を確認していきたいと思います。
今回は、比較的簡単に書けるPythonの例です。
まず、protobufは次のように書いたとします。簡単なUserを定義した例です。
message User {
int32 id = 1;
}
そこで、このUserのバイナリは次のように出力することができます。
import user_pb2
user = user_pb2.User()
user.id = 12
print(" ".join([f'{x:08b}' for x in user.SerializeToString()]))
# 00001000 00001100
実際のバイナリは00001000 00001100になるということになりますね!
バイナリを読んでみる
それでは早速、先ほどの00001000 00001100の例を読んでみることにしましょう。
ここでは、左から順番に1bit目、2bit目…と呼ぶことにします。
それぞれのbitの意味は次の通りになります。
00001000 00001100
- 1bit目(0) ... フィールド番号の後続があるかどうかのflag
- 2-5bit目(0001) ... フィールド番号 → 1
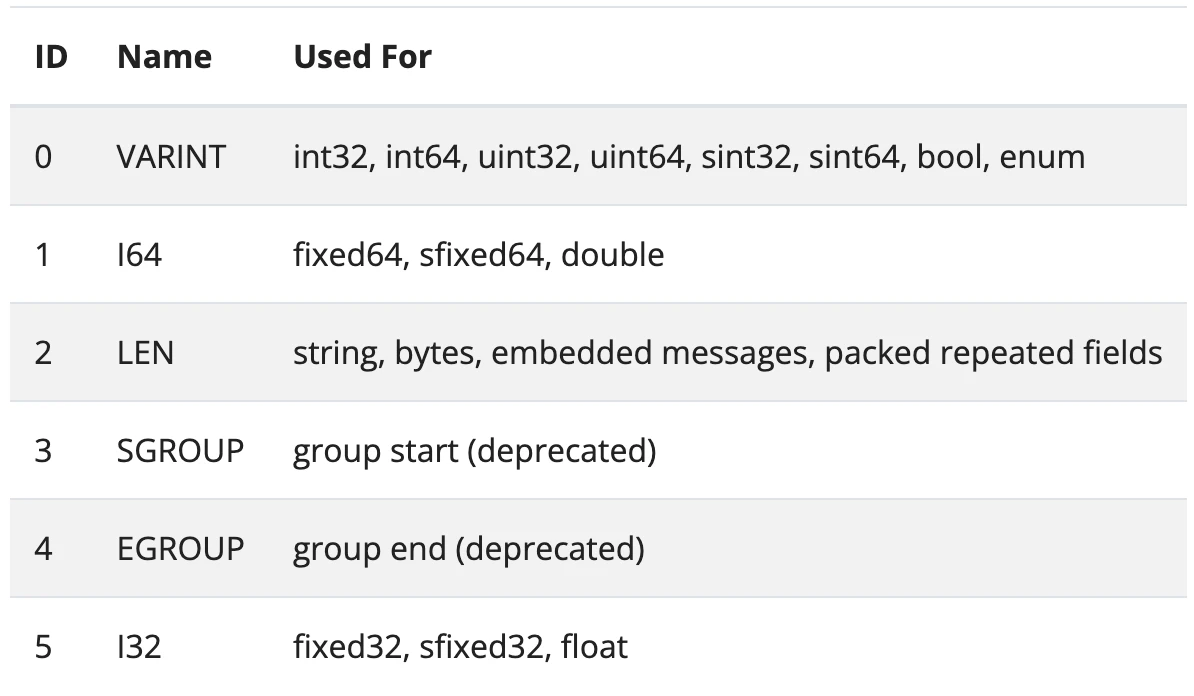
- 6-8bit目(000) ... Wire type → 0 (VARINT)
- 9bit目(0) ... フィールドの値に後続があるかどうかのflag
- 10-16bit目(0001100) ... フィールドの値→12であることがわかる
1bit目は一旦ここでは無視してください。
まず重要なのは、2-5bit目です。これはフィールド番号と呼ばれるもので、protobufで定義したint32 id = 1;の1の部分に相当します。protobufで送信するデータのバイナリ自体には、フィールド名などが含まれずフィールド番号で区別しているのが特徴ですね!
また、6-8bit目はWire typeであり、これはどんなデータの種類がくるかを表しています。公式ドキュメントでは、このように説明されています。今回定義したidはint32なので、VARINTの0になっていました。
また最後の10-16bit目は、実際のフィールドの値、12を表しています。
このように、今回のような簡単なmessageであれば、2バイトで表せることがわかります。
もっと難しいのを読んでみる
せっかくなので、もう少し複雑な例を見てみましょう。例えば次のようなprotobufを定義して、
message User {
int32 id = 1;
string name = 2;
repeated int64 num = 99;
}
次のようにデータを用意します。
import user_pb2
user = user_pb2.User()
user.name = "A"
user.num.extend([1, 10])
binary = user.SerializeToString()
print(" ".join([f'{x:08b}' for x in binary]))
# 00010010 00000101 01100101 01110101 01100011 01111001 01110100 10011010 00000110 00000010 00000001 00001010
先ほどとは違って長いですね、12バイトもあります。
でも安心してください。意外と簡単に読めます。一つずつ見ていきましょう!
前半部分
まず、前半に絞って見ていきます。
00010010 00000101 01100101 01110101 01100011 01111001 01110100
- 1bit目(0) ... フィールド番号の後続があるかどうかのflag
- 2-5bit目(0010) ... フィールド番号 → 2
- 6-8bit目(010) ... Wire type → 2(LEN)
- 9bit目(0) ... フィールドの値の長さの表現に後続があるかどうかのflag
- 10-16bit目(0000101) ... フィールドの値の長さ → 5bytes
- 残り ... 0x65 0x75 0x63 0x79 0x74 → eucyt
先ほど同様、2-5bit目はフィールド番号です。今回は2、つまりnameのフィールドであることがわかります。
また、Wire typeは2のLENです。これはstringなど長さが不定のものに使われます。この場合、10-16bit目にフィールドの値に使われるバイト数が表現されています。今回は5なので、後続の5バイトが実際の値であることがわかります。
残りの5バイトをそれぞれASCIIコードに変換すると、eucytとなります。これがnameのフィールド値です。
後半部分
次に後半も見ていきましょう。
10011010 00000110 00000010 00000001 00001010
- 1bit目(1) ... 後続byteあり
- 2-5, 9-16bit目(0000110 0011) ... フィールド番号 → 99
- 6-8bit目(010) ... Wire type → 2(LEN)
- 10-16bit目(0000010) ... フィールドの値の長さ → 2bytes
- 18-24bit目(0000001) ... フィールドの値 → 1
- 26-32bit目(0001010) ... フィールドの値 → 10
今まで無視していた1bit目が、1であることがわかります。これは後続のbyteがあることを示しています。
つまり、この最初の1bit目でフラグによって、フィールド番号が2-5bitの4bitで表せない数であった場合に、後続のbyteも使用するよ、ということを表しているのです。注意点としては、リトルエンディアンなので、後ろのバイトから読む形になります。なので今回は、0000110 0011、すなわち99となるということです。これは、numのフィールド番号ですね。
次に、6-8bit目を読むとWire typeはLENであることがわかります。9-16bit目から後続の2bytesが実際の値になっていることがわかりますね。
実際のフィールド値も見てみましょう。最初のbyteは1、その次のbyteは10となっています。これは配列のそれぞれの要素の値になっています。ここで、もしも2bytes以上にまたがるような大きい値をセットしたい場合はどうすればいいでしょう?この場合、byteの先頭のbitを1にすることで、後続のbyteも同じ要素の値を表していることがわかるのです。逆に、今回のようにbyteの先頭のbitが0であれば、別要素であることがわかるということですね。こうすることで要素数の情報を入れなくて済みます。
このような複雑なものでも、いざ読んでみると意外と読みやすく、また少ないデータ量で表されていることが理解できます。
まとめ
今回は、protobufのバイナリを覗いてみました。その結果、さまざまな工夫が確認できました。
例えば、フィールド名、値をセットしていないフィールド、配列の要素数はバイナリには含まれていません。
また、今回は触れませんでしたが、zigzag encodingによって、小さな負の数をデータ量少なく表現するsint32などのtypeも用意されています。
実際のバイナリを覗いてみることで、どのようにしてデータ量の削減を実現しているか、より理解を深めることができたのではないかなと思います。