この記事について
現在、AWS Certified Database Specialtyの勉強中です。その中で、Amazon Neptuneの話が出てきました。Graph Databaseであるとの事です。RDBでもKey-ValueでもないDatabaseの様で、どのような特性を持つDatabaseかを把握したいと思いました。その検証記録になります。
環境
この記事の内容は以下環境で実行しています。
WSL2
Ubuntu 22.04.1 LTS
Neo4j Community Edition 4.4.11
記事から勉強
まずは、発端となったAWSの記事を見てみます。
リレーションシップの格納とナビゲートを目的として構築されたデータベースです。
との事。不正検出や推奨エンジンがユースケースとして紹介されており、データとデータの関係性を抽出するユースケースで威力を発揮する様です。これだけだと、RDBでも(その名の通りRelational Databaseですし)、出来そうな気がします。
こちらの記事にその答えがありました。友達との関係性を調べるユースケースにて、「友達の友達」を調べるケース(深さ2)ではRDBとの差はあまり感じないのに対して、「友達の友達の友達」を調べるケース(深さ3)では差が顕著になり、それ以上だとRDBでは使用に耐えない時間になっています。
このように、関係性がネットワーク型になっているデータに対して、深さ3以上の関連性を調べる時、というのが適した使い方の様です。
また、先ほどの記事の続きの記事で、ユースケースを紹介しています。こちらによると
新しいデータの追加・修正がより柔軟にできる
という点も強みの様です。RDBですとどうしてもテーブル構造を決めておく必要があります。データの関連性が一様でない場合にもRDBでは対応が難しそうです。
実際に使ってみる
表題の通り、実際に使って理解する事にします。
データを考える
使う為には、Databaseに投入するデータが必要です。自分で作るのは大変なので、既存のオープンデータを使いたい所です。
こちらの記事が色々参考になります。サンプルデータとして、映画と俳優の関係性のデータが準備されている様です。
Neo4jサーバーを準備する
Amazon Neptuneを使うとお金がかかってしまうので、Neo4jをローカルにインストールして試す事にします。基本先ほどの記事を参考にしながら、公式ページをトレースする事にします。
ページ中央程にあるStart Free For Developersを選択すると、Neo4j AuraDBというクラウドサービスを使う事になりそうです。ローカルで起動したくてページ内をさまよっていたら、公式dockerイメージがある様です。
WSL2で、Ubuntu 22.04.1 LTSのイメージを起動して、以下のコマンドを実行します。
# データ保持ディレクトリ作成
mkdir -p $HOME/neo4j/data
# 起動
docker run \
--publish=7474:7474 --publish=7687:7687 \
--volume=$HOME/neo4j/data:/data \
neo4j
Windows側で、http://localhost:7474へアクセスすると、ログイン画面が表示されました。もうサーバー準備出来た事になります。docker最高です。初期ID/パスワード「neo4j/neo4j」でログイン後、新しいパスワードが求められるので、任意のパスワードを決めるか自動生成して入力します。その後、初期画面が表示されました。
後程実行するチュートリアルの実行した後の画面です。こんな感じでGraph形式で実行結果が表示される(内容によってはTable形式)UIとなっています。
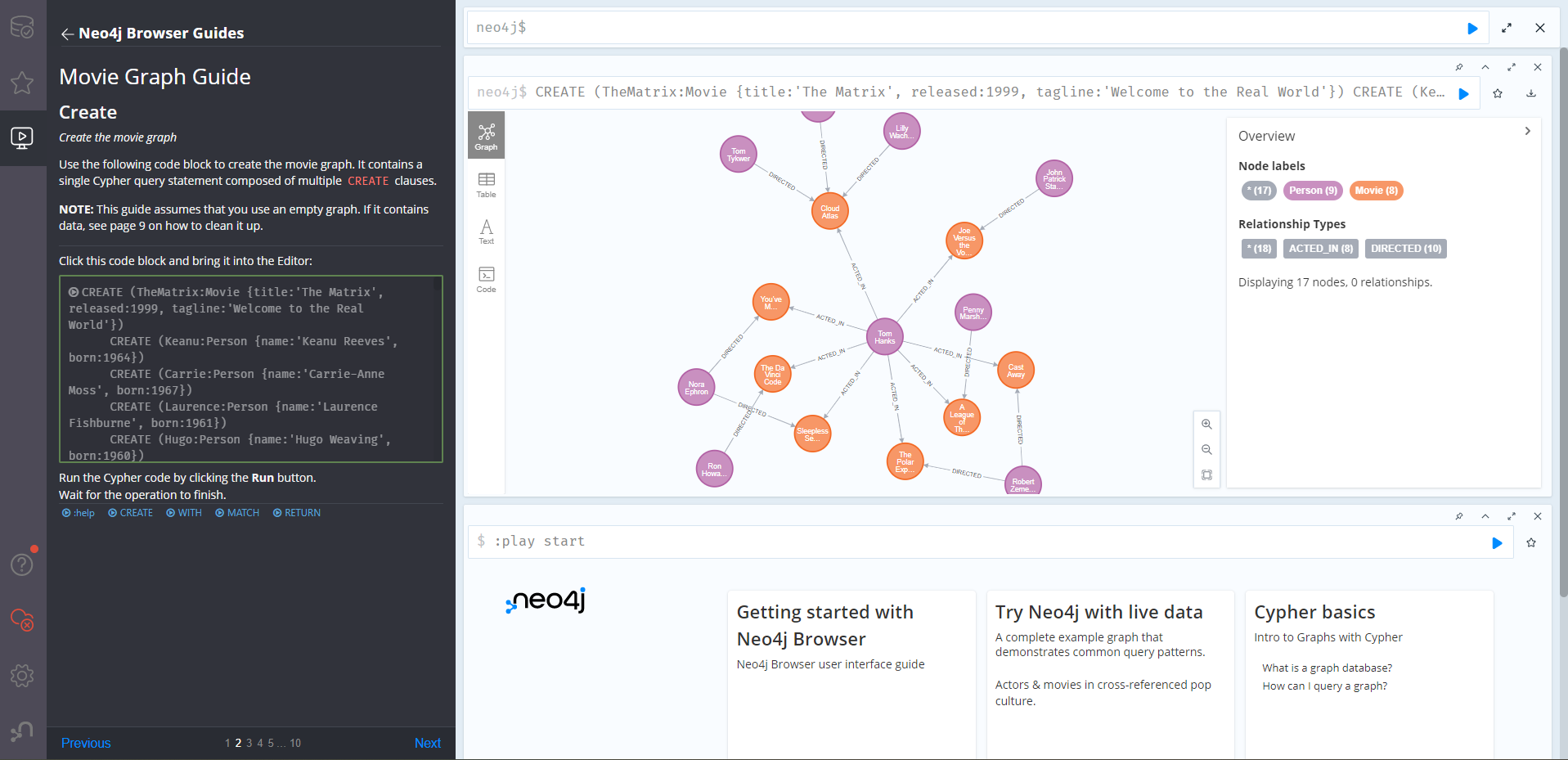
チュートリアルを実行する
:play start
と入力部に表示されているエリアがあります。それぞれ、目的別のチュートリアルの様です。
- Getting started with Neo4j Browser
今表示されている画面コンソールの使い方を紹介しています - Try Neo4j with live data
俳優と監督と映画の関係のデータを使用して、一通りの操作をする様です - Cypher basics
CypherというNeo4jの操作言語の説明です。
Getting started with Neo4j Browser
画面の使い方をレクチャーしています。最後にConcepts Guideへ移動するリンクがあります。
Concepts Guide
Graph Databaseの基本思想を記載しています。自分なりに理解した内容を記載します。
Nodes - 各分類の実体のデータ
Labels - Nodesの分類を表します(例:Person、Car)
Relationships - ノード間の関係の定義(例:出演してる、知っている、友達)
Properties - NodesとRelationshipsに対して、名前と値の情報を付与できます(例:人の名前、映画のタイトル)
Cypher Guide
Cypher basicsのチュートリアル通りにコマンドを打ってみます。
CREATE (ee:Person {name: 'Emil', from: 'Sweden', kloutScore: 99})
MATCH (ee:Person) WHERE ee.name = 'Emil' RETURN ee;
MATCH (ee:Person) WHERE ee.name = 'Emil'
CREATE (js:Person { name: 'Johan', from: 'Sweden', learn: 'surfing' }),
(ir:Person { name: 'Ian', from: 'England', title: 'author' }),
(rvb:Person { name: 'Rik', from: 'Belgium', pet: 'Orval' }),
(ally:Person { name: 'Allison', from: 'California', hobby: 'surfing' }),
(ee)-[:KNOWS {since: 2001}]->(js),(ee)-[:KNOWS {rating: 5}]->(ir),
(js)-[:KNOWS]->(ir),(js)-[:KNOWS]->(rvb),
(ir)-[:KNOWS]->(js),(ir)-[:KNOWS]->(ally),
(rvb)-[:KNOWS]->(ally)
MATCH (ee:Person)-[:KNOWS]-(friends)
WHERE ee.name = 'Emil' RETURN ee, friends
The Movie Graph
基本操作で、ある程度解った気になります。次はTry Neo4j with live dataのチュートリアル通りにコマンドを打ってみます。これが映画と俳優の関係のデータを使った操作になります。
MATCH (n) DETACH DELETE n
CREATE (TheMatrix:Movie {title:'The Matrix', released:1999, tagline:'Welcome to the Real World'})
// 以後省略
CREATE CONSTRAINT ON (n:Movie) ASSERT (n.title) IS UNIQUE
CREATE CONSTRAINT ON (n:Person) ASSERT (n.name) IS UNIQUE
CREATE INDEX FOR (m:Movie) ON (m.released)
// nameが"Tom Hanks"のPersonノードを取得:
MATCH (tom:Person {name: "Tom Hanks"}) RETURN tom
// titleが"Cloud Atlas"のMovieノードを取得
MATCH (cloudAtlas:Movie {title: "Cloud Atlas"}) RETURN cloudAtlas
// Personノードを10件取得
MATCH (people:Person) RETURN people.name LIMIT 10
// 1990年から2000年より前にリリースされた映画を取得
MATCH (nineties:Movie) WHERE nineties.released >= 1990 AND nineties.released < 2000 RETURN nineties.title
// Kevin Baconから4ステップ以内にいるノードを取得
MATCH (bacon:Person {name:"Kevin Bacon"})-[*1..4]-(hollywood)
RETURN DISTINCT hollywood
// 組み込み関数shortestPathを使用して、Kevin BaconとMeg Ryanの最短ルートを取得
MATCH p=shortestPath(
(bacon:Person {name:"Kevin Bacon"})-[*]-(meg:Person {name:"Meg Ryan"})
) RETURN p
こんな結果が出ました。

// Tom Hanksの共演者の共演者でTom Hanksと共演した事の無いPersonを取得してルートの件数で逆ソート
MATCH (tom:Person {name:"Tom Hanks"})-[:ACTED_IN]->(m)<-[:ACTED_IN]-(coActors),
(coActors)-[:ACTED_IN]->(m2)<-[:ACTED_IN]-(cocoActors)
WHERE NOT (tom)-[:ACTED_IN]->()<-[:ACTED_IN]-(cocoActors) AND tom <> cocoActors
RETURN cocoActors.name AS Recommended, count(*) AS Strength ORDER BY Strength DESC
こんな結果が出ました。
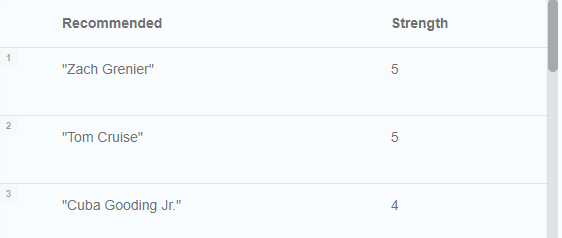
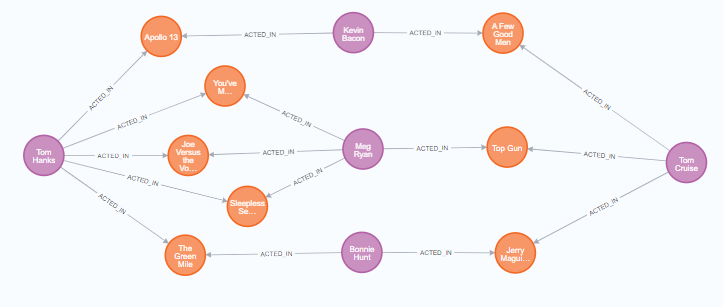
// Tom HanksにTom Cruiseを紹介できる(共演者の共演者)Personを取得
MATCH (tom:Person {name:"Tom Hanks"})-[:ACTED_IN]->(m)<-[:ACTED_IN]-(coActors),
(coActors)-[:ACTED_IN]->(m2)<-[:ACTED_IN]-(cruise:Person {name:"Tom Cruise"})
RETURN tom, m, coActors, m2, cruise
こんな結果が出ました。
MATCH (n) DETACH DELETE n
MATCH (n) RETURN n
チュートリアルの感想
チュートリアルを一通りこなしてみたました。RDBでは複雑なSQLを組むか、それなりのボリュームのプログラムを作ったりしないと出来ない事を一つの問い合わせ文で実行できる事が判りました。
チュートリアルで使ったのは一例で、操作言語であるcypherのマニュアルを見ると多彩な関数が用意されている事が解ります。冒頭でも述べた通り、関係性がネットワーク型になっているデータに対して、何かの条件下におけるデータを取得するケースで威力を発揮すると思います。
プログラムから使用してみる
実際のシステムではコマンドラインでなく、プログラムから使用すると思います。ドライバを探してプログラムから使用してみます。
Java、Javascript、Python、.NET、Goのドライバは正式に準備されていて、かつ各言語のコミュニティによってドライバが提供されている様です。
自分の環境ではPythonがお手軽に実行出来るので、Pythonを使います。
pip install neo4j
from neo4j import GraphDatabase
driver = GraphDatabase.driver("neo4j://localhost:7687",
auth=("neo4j", "password"))
def add_friend(tx, name, friend_name):
tx.run("MERGE (a:Person {name: $name}) "
"MERGE (a)-[:KNOWS]->(friend:Person {name: $friend_name})",
name=name, friend_name=friend_name)
def print_friends(tx, name):
query = ("MATCH (a:Person)-[:KNOWS]->(friend) WHERE a.name = $name "
"RETURN friend.name ORDER BY friend.name")
for record in tx.run(query, name=name):
print(record["friend.name"])
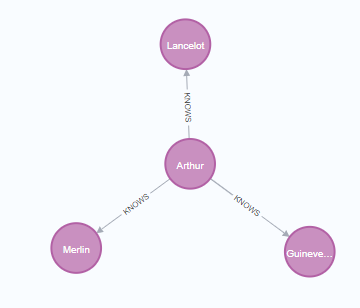
with driver.session() as session:
session.execute_write(add_friend, "Arthur", "Guinevere")
session.execute_write(add_friend, "Arthur", "Lancelot")
session.execute_write(add_friend, "Arthur", "Merlin")
session.execute_read(print_friends, "Arthur")
driver.close()
Neo4jのセッションをまず取得し、そこから書き込み、読み込みそれぞれのメソッドが用意されている様です。
コールバック関数(?)とそれに使用するパラメーターを前述2種のメソッドに渡す様です。また、cypherコマンドは、そのままコマンド文を実行出来る形の様です。RDBのドライバでSQL文がそのまま実行できるのに似ています。
$ python neo4j_test.py
Guinevere
Lancelot
Merlin
Neo4jのコンソールで確認した所、4つのノードがちゃんと登録されていました。
まとめ
今回の目的である、Graph Databaseとはどのようなものか理解できたかと思います。もちろん実際に何らかのアプリで使用されている状況ではもっと深い処理がされているかとは思いますが、少なくとも基本特徴は把握できたと思います。チュートリアル優秀ですね。
今後身の回りで、何らかの関係性を深く調べたいようなケースが出てきたら、Neo4jサーバー起動してデータ投入して調べてみたくなると思います。Neo4jのUIでのGraph表示では、ノードの位置など自由に動かせてその操作自体も楽しかったですw