この記事の目的
機械学習モデルなど統計モデルの性能の良さを表すROC曲線とAUCについて、思い切り単純化した数値例を用いて理解します。
作成に当たっては下記サイトの設例を参考にさせて頂きました。
途中過程を飛ばさず、より詳しく(しつこく)書き出しながら理解していきます。
具体例で学ぶ数学 AUCとROC曲線の意味と性質を分かりやすく解説
また精度が良い予測、ランダムな予測の時にROC曲線とAUCがどのようになるか、上記の数値例と比べてみます。
最後にPythonのScikit-learnを使ってROC曲線とAUCを簡単に算出できることを確認します。
用語
-
ROC曲線
ある検査において閾値ごとの真陽性率、偽陽性率をプロットした曲線。
当記事では実際の値が陽性(以下P)であるか陰性(以下N)であるかを確率で表す統計モデルを考えます。 -
AUC
ROC曲線下部の面積。AUCが大きいほど良いモデルとされる。 -
閾値(p)
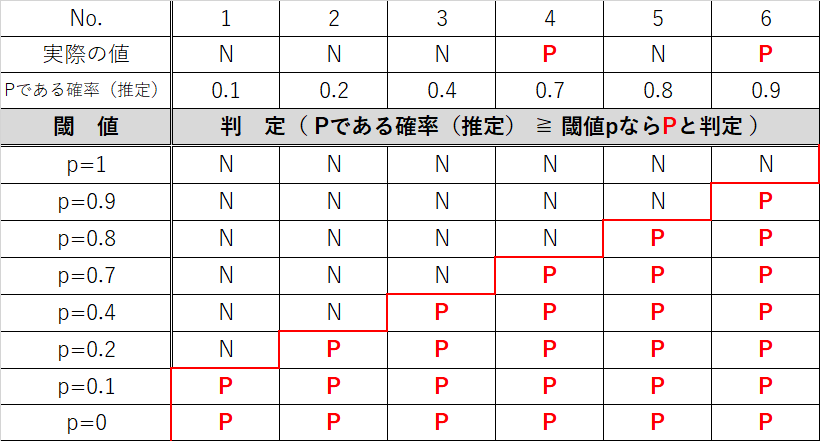
モデルで予測された確率がpより大きければ陽性(P)、**pより小さければ陰性(N)**と判定される。
(例)閾値p=0.8のとき
データ1がPの確率 0.9 → 閾値p=0.8より大きいので判定はP
データ2がPの確率 0.7 → 閾値p=0.8より小さいので判定はN
-
真陽性率(TPR : True Positive Rate)
実際に**陽性(P)**であるデータのうち、**陽性(P)**と判定されたデータの割合
(Pと判定されたデータの数 ÷ 実際にPであるデータの数) -
偽陽性率(FPR : False Positive Rate)
実際は**陰性(N)**であるデータのうち、**陽性(P)**と判定されたデータの割合
(Pと判定されたデータの数 ÷ 実際はNであるデータの数)
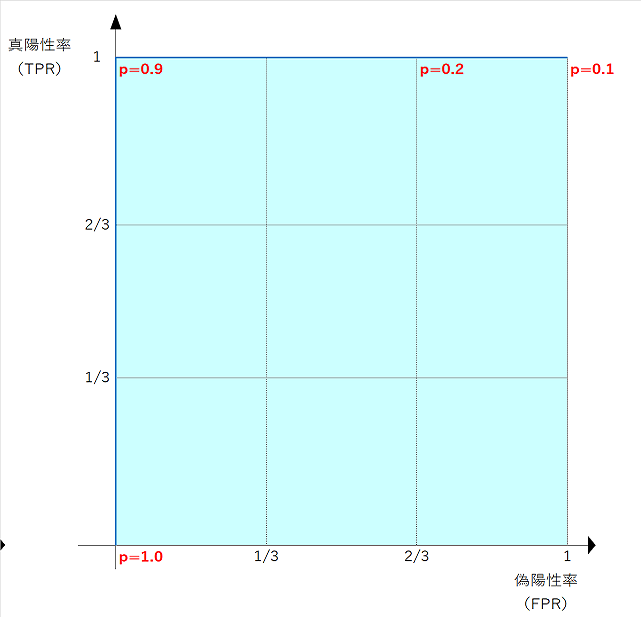
・・・教科書などではここまでの説明で、「閾値pごとの偽陽性率をx軸、真陽性率をy軸にプロットするとROC曲線になる」と唐突に以下のような図が現れます。
皆様は理解できたでしょうか? 私は全く理解できませんでした。。

なので、具体的に閾値pごとの真陽性率、偽陽性率を計算し、グラフにプロットして理解することにしました。
具体例(モデル1)
具体例で学ぶ数学に記載された以下の推定結果を、表形式に加工して使います。
(Pである確率が小さい順に左から並べます)

例えば閾値をp=0.5に設定、つまりPである確率(推定)が0.5以上であればPと判定することにします。
データ4、6では正しくPと判定できますが(真陽性)、データ5では実際はNであるデータをPと判定してしまいます(偽陽性)。
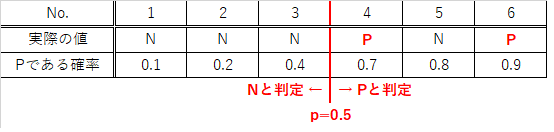 閾値がp=0.5の場合、真陽性率、偽陽性率は以下の通りです。
閾値がp=0.5の場合、真陽性率、偽陽性率は以下の通りです。
真陽性率 = Pと判定されたデータ(実際はP)の数 ÷ 実際にPであるデータの数 = 2 ÷ 2 = 1
偽陽性率 = Pと判定されたデータ(実際はN)の数 ÷ 実際はNであるデータの数 = 1 ÷ 4 = 1/4
閾値pごとに真陽性率(TPR)、偽陽性率(FPR)を計算します。
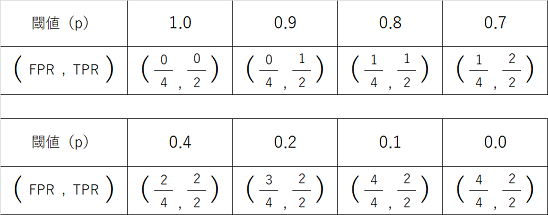
( FPR , TPR )=( 偽陽性率 , 真陽性率 )はあえて約分せずに記載しています。
閾値pごとの偽陽性率をx軸、真陽性率をy軸にプロットしてROC曲線を描きます。
(この例では離散値のため折れ線になります)
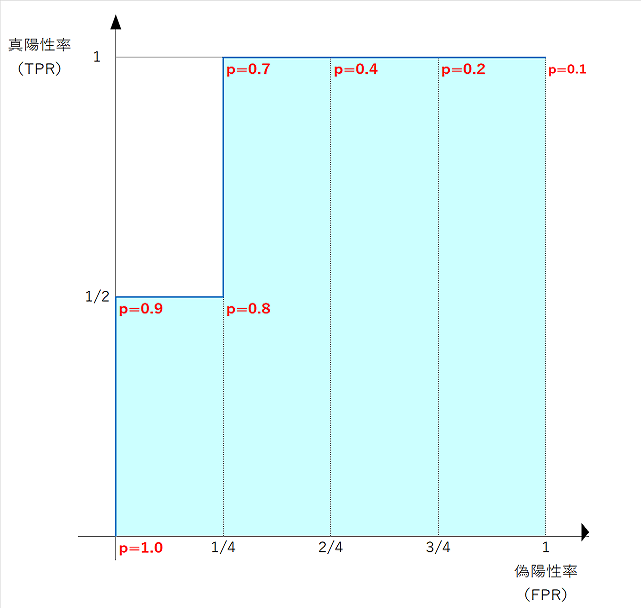
青色の太線がROC曲線、薄青色の領域の面積がAUCです。
面積を計算すると
AUC = 1 - 1/4 * 1/2 = 7/8 = 0.875
であることがわかります。
再び判定表を見ると、閾値p=1のときは、全てのデータがNと判定されるため、真陽性率、偽陽性率ともに0となります。
また閾値p=0のときは、全てのデータがPと判定されるため、真陽性率、偽陽性率ともに1となります。
p=1からp=0まで動かすと真陽性率, 偽陽性率ともに上昇する
→ (真陽性率, 偽陽性率)の組み合わせは(0, 0)から(1, 1)まで動く
→ ROC曲線は0と1を結ぶ曲線となる
ことが分かります。
具体例(モデル2~良いモデル)
モデル1より判定精度の高いモデルを考え、ROC曲線をプロットしてみます。
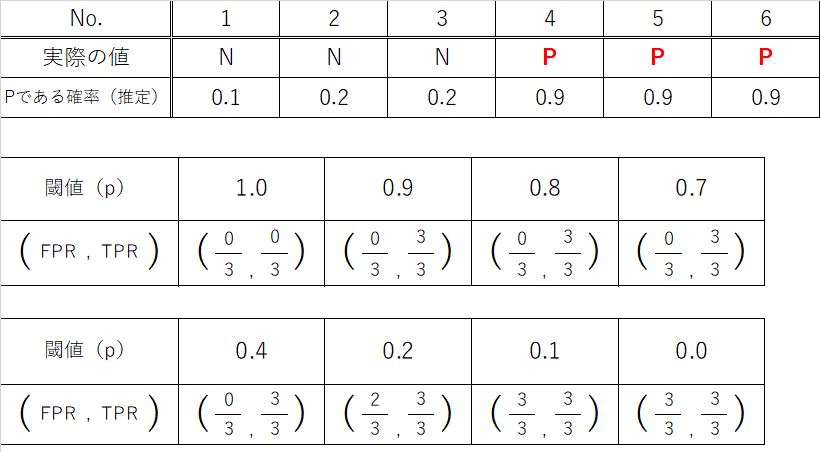
実際の値がPである場合、Pである確率を0.9と推定するモデルです。
ROC曲線を描くと、閾値p=0.9の時点で真陽性率(TPR)が1と急激に上昇し、p=0.2になるまで偽陽性率は0より上昇しないことが分かります。
またAUC(薄青色の領域の面積)も1と、モデル1より大きいです。
このように当てはまりのよいモデルでは真陽性率が速く上昇する一方、偽陽性率はなかなか上昇せず、結果としてAUCが大きくなることが分かります。
具体例(モデル3~ランダムなモデル)
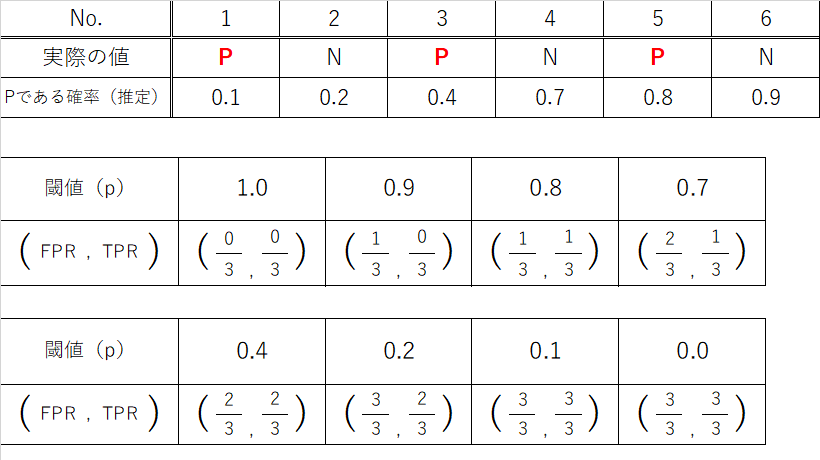
 実際の値がPであるかNであるかに関わらずランダムな確率を推定するモデルです。
閾値pを小さくしていくと、真陽性率、偽陽性率が同じように上昇していきます。
AUC(薄青色の領域の面積)を計算すると
**AUC = 1/3 * 1/3 * 3 = 1/3 = 0.333**
であることがわかります。
実際の値がPであるかNであるかに関わらずランダムな確率を推定するモデルです。
閾値pを小さくしていくと、真陽性率、偽陽性率が同じように上昇していきます。
AUC(薄青色の領域の面積)を計算すると
**AUC = 1/3 * 1/3 * 3 = 1/3 = 0.333**
であることがわかります。
なお連続値のモデルではROC曲線は0と1を結ぶ直線に近づいていきます。
Python(Scikit-learn、matplotlib)を使用
これまで閾値pごとの真陽性率、偽陽性率を一つずつ書き出しましたが、
PythonのScikit-learnライブラリのroc-curveで真陽性率、偽陽性率、閾値を算出し、
matplotlibを使ってグラフを簡単に描画できます。
from sklearn.metrics import roc_curve
import matplotlib.pyplot as plt
# モデル1
y_true1 = [0, 0, 0, 1, 0, 1] #N(陰性)は0、P(陽性)は1
y_score1 = [0.1, 0.2, 0.4, 0.7, 0.8, 0.9] #ラベルがPである確率
fpr1, tpr1, thresholds1 = roc_curve(y_true1, y_score1) #真陽性率、偽陽性率、閾値
# モデル2(良いモデル)
y_true2 = [0, 0, 0, 1, 1, 1]
y_score2 = [0.1, 0.2, 0.2, 0.9, 0.9, 0.9]
fpr2, tpr2, thresholds2 = roc_curve(y_true2, y_score2)
# モデル3(ランダムなモデル)
y_true3 = [1, 0, 1, 0, 1, 0]
y_score3 = [0.1, 0.2, 0.4, 0.7, 0.8, 0.9]
fpr3, tpr3, thresholds3 = roc_curve(y_true3, y_score3)
fig = plt.figure(figsize=(12, 3))
fig.subplots_adjust(wspace=0.4)
ax1 = fig.add_subplot(1, 3, 1)
ax1.plot(fpr1, tpr1, marker='o')
ax1.set_title('Model1')
ax1.set_xlabel('FPR: False positive rate')
ax1.set_ylabel('TPR: True positive rate')
ax1.grid()
ax2 = fig.add_subplot(1, 3, 2)
ax2.plot(fpr2, tpr2, marker='o')
ax2.set_title('Model2(Good)')
ax2.set_xlabel('FPR: False positive rate')
ax2.set_ylabel('TPR: True positive rate')
ax2.grid()
ax3 = fig.add_subplot(1, 3, 3)
ax3.plot(fpr3, tpr3, marker='o')
ax3.set_title('Model3(Random)')
ax3.set_xlabel('FPR: False positive rate')
ax3.set_ylabel('TPR: True positive rate')
ax3.grid()

またScikit-learnライブラリのroc_auc_scoreでAUC(ROC曲線下部の面積)を算出できます。
from sklearn.metrics import roc_auc_score
print('AUC(Model1) : {0:.3f}'.format(roc_auc_score(y_true1, y_score1))) #小数点第3位まで表示
print('AUC(Model2) : {0:.3f}'.format(roc_auc_score(y_true2, y_score2)))
print('AUC(Model3) : {0:.3f}'.format(roc_auc_score(y_true3, y_score3)))
出力結果
AUC(Model1) : 0.875
AUC(Model2) : 1.000
AUC(Model3) : 0.333
上の例で見た計算結果と一致することが分かります。