はじめに
この記事では、データマネジメント知識体系ガイド 第二版(DAMA-DMBOK SECOND EDITION)の内容を参考にデータモデルの構築(データモデリング)と運用の手順・方法について記述しています。
DMBOK は非常に内容が多く、いきなり読み進めるのが大変なため、ゆずたそさんのデータマネジメントが30分でわかる本を最初に読ませていただきました。とてもわかりやすくて良書でした!
データモデリングの概要
データモデリングとは、データの要件を分析・整理し、データの関係性を図で表現することです。このモデリング作業を行うことで、データの関係性がドキュメント化され、その後のシステム開発やデータのマネジメントが行いやすくなります。
例えば、システムの改修作業に着手する際には、データモデルを参照することで、データ範囲の影響がわかりやすくなります。また、データがドキュメント化されているので、組織内でのコミュニケーションツールとして活用することもできます。
注意点として、データモデリングはデータを理解することが根本的な目的になるため、必ずしもデータベースを設計・作成するとは限らないです。
データモデリングの目標
データモデリングを行い、次のような状態を目指します。この状態を維持していくことで、データの関係性をドキュメント化することによるメリットを享受することができます。
- データモデルを 3 つのレベル(概念、詳細、物理)でそれぞれ構築する
- 構築したデータモデルをドキュメントとして管理する
- 開発環境との差異が出ないようにデータモデルを維持する
特に、データの活用を積極的に行う組織であれば、このような状態を保ち、データの現状を把握することは、データマネジメントを行う上での土台となるため重要です。
データモデリングの手順と詳細
データモデリングを行う手順には 2 通りあります。フォワードエンジニアリングとリバースエンジニアリングです。フォワードエンジニアリングは、要件定義から徐々に詳細な設計をしていきますが、リバースエンジニアリングは、既存のデータベースなどからデータを理解しようとします。
本記事ではおそらくより一般的なフォワードエンジニアリングでのデータモデリング手順について記述します。
1. 概念データモデリング
概念データモデリングでは、データ体系の表現方法(スキーム、表記法)を決め、表記法のルールをもとに概念レベルでのデータモデルを構築します。
1.1 スキーマの選択
ここでは、代表的なスキーマ(データの構造)としてリレーションスキーマとスタースキーマを紹介します。これらのスキームの中から、データの特徴やメンバーが使い慣れているかどうか等を考慮してスキームを決定します。
リレーションスキーマ
リレーションスキーマは、データの冗長性を排除することを目標としており、エンティティ間のリレーションシップを表現することができます。代表的な表記法として、IE記法、IDEF1X記法などのいわゆるER図があります。次の図は、概念データモデルのIE記法の例です。

スタースキーマ
スタースキーマは、ビッグデータへの問い合わせと分析が最適化されるようにデータを表現することができます。ファクトテーブル、ディメンショテーブルを組み合わせて構築します。
ファクトテーブルは、金額、量、件数などの数値が格納されるトランザクションデータです。データの大部分を占めるため、行数が多くなる傾向があります。ディメンションテーブルは、業務上で重要な概念を表すマスタデータのことです。
次の図は、概念データモデルの分析軸表記法の例です。売上記録を店舗、商品、シーズン、キャンペーンごとに分類しています。ファクトテーブルが「売上記録」、それ以外の「店舗」「商品」「シーズン」「キャンペーン」がディメンションテーブルです。
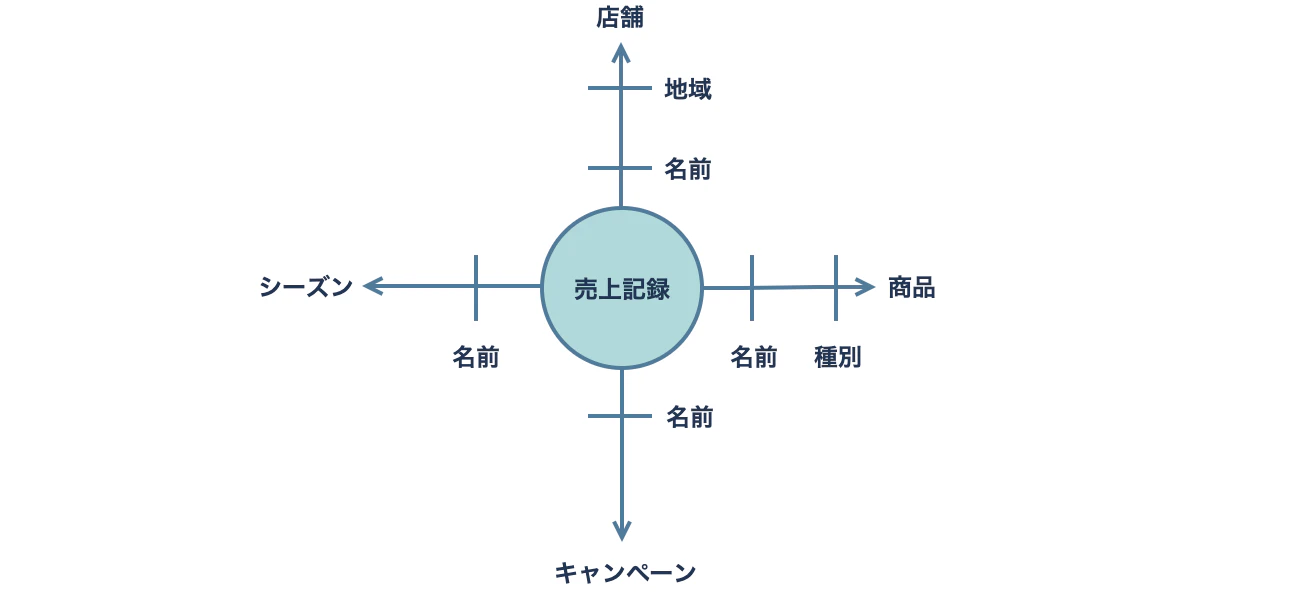
1.2 表記法の選択
スキーマを決定したら、表記法を選択します。例として、リレーションスキーマであれば、IE記法のように代表的な記法で比較的メンバーが使いやすいものを選択します。
1.3 業務要件の計画
業務要件の計画を行い、概念データモデルを作成します。上記のリレーションスキーマの例で言うと、このような業務要件をデータモデルに反映します。
- 顧客は注文を0回以上行うことができ、注文は必ず1人の顧客によるものである
- 1つの注文で出荷が複数にわかれることがある
ここでは、業務要件は複雑になりすぎないようにし、概要レベルに留めます。また、ここで使われる「顧客」などの概念は組織内で統一するか、統一されたものを使用し、共通の語彙として利用できるようにします。
2. 論理データモデリング
論理データモデリングでは、**概念データモデルに属性を追加し、拡張する作業を行います。**ただし、技術的な制約や実装のことについてはここではまだ考えません。
2.1 業務要件の分析
ここで、詳細な業務要件を分析します。データ要件を決定するために、ヒアリング等による業務プロセスの調査を行い、業務上のニーズを把握します。
2.2 関連エンティティの追加
関連エンティティは、論理レベル以上で多対多のリレーションシップを記述するために使用されます。次の図は、本と著者の関係を概念データモデルで表したものです。

本と著者の関係は多対多(本には複数の著者がいる可能性がある、著者は複数の本を書くことができる)ですが、論理データモデルで多対多のリレーションシップを表現するには、次のように関連エンティティを新たに追加する必要があります。

2.3 属性の追加
概念データモデルに属性を追加します。次の図は、上記で紹介したリレーションスキーマの概念データモデルに属性を追加したものです。

属性を追加すると同じタイミングで、**ドメイン(値の定義域)**を決めます。これにはデータタイプ(文字列、数値など)やデータ範囲(0以上、特定の文字やカテゴリなど)などが含まれます。
同様に、次の図は、スタースキーマの概念データモデルに属性を追加したものです。
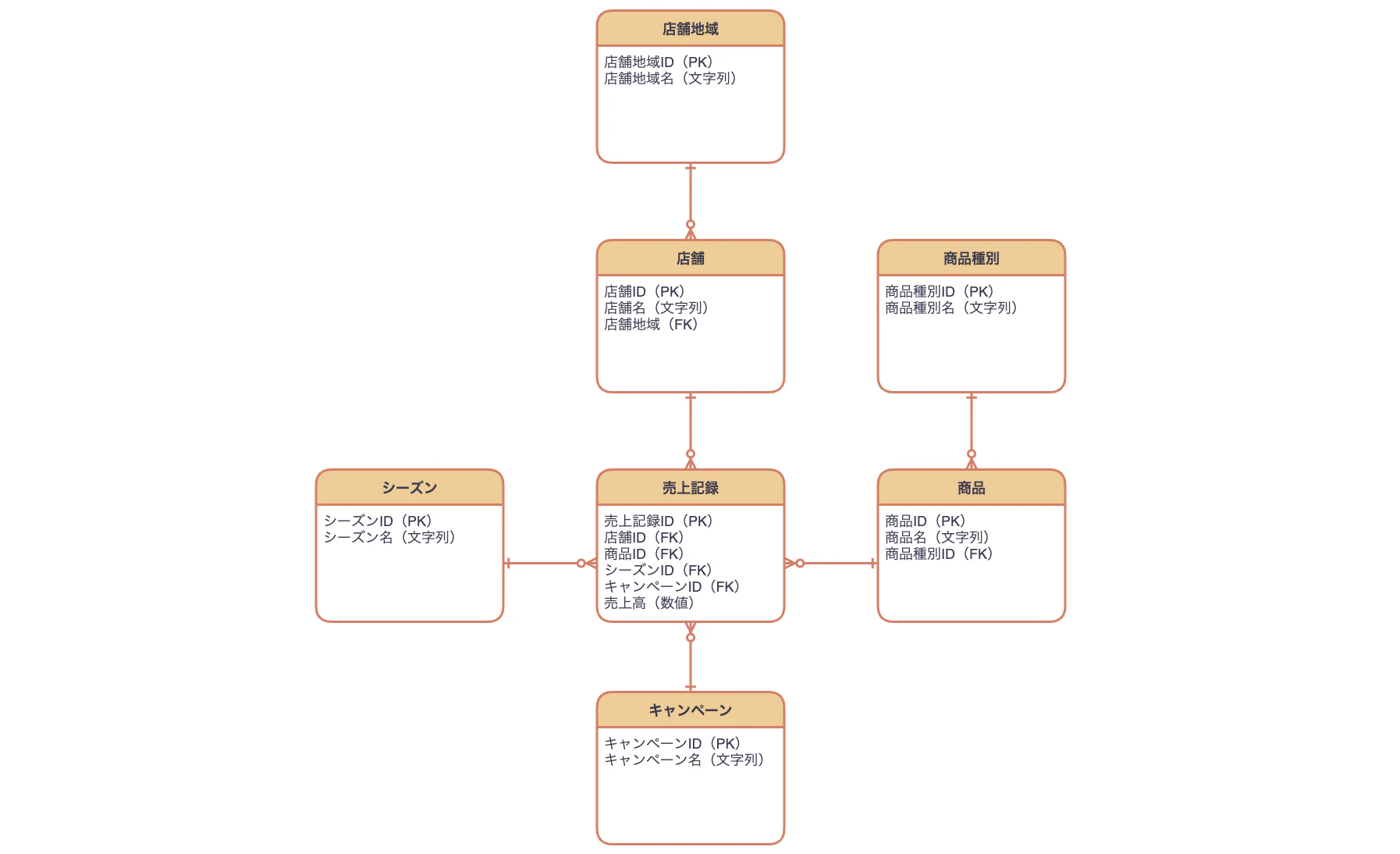
また、キーをどの属性から作成するかを決めます。キーには主に次の種類が存在します。
- **単一キー:**ひとつでデータを一意に識別できる属性。業務上のIDやサロゲートキー(自動生成される連番、数値に意味を持たない)などが当てはまります。
- **合成キー:**データを一意に識別できる複数の属性の組み合わせ。クレジットカード番号(発行者ID + アカウントID + チェックディジット)などが当てはまります。
- **複合キー:**データを一意に識別できる、キーともうひとつ以上の単一キー、合成キー、非キー属性のいづれかの組み合わせ。関連エンティティの識別子などが当てはまります。
これらのように、データを一意に識別する属性の組み合わせのことを候補キーと呼び、候補キーの中から選択された唯一の識別子を主キーと呼びます。また、それ以外の候補キーのことを代替キーと呼びます。
3. 物理データモデリング
物理データモデリングでは、特定のデータベースの用語を使って制約を追加します。また、データベースへの問い合わせ等が高速に動作するように調整します。
3.1 制約の追加
利用するデータベースに合わせた制約を追加します。また、フィールド名はそのデータベースの命名規則に従います。次の図は、リレーションスキーマの物理データモデルの例です。
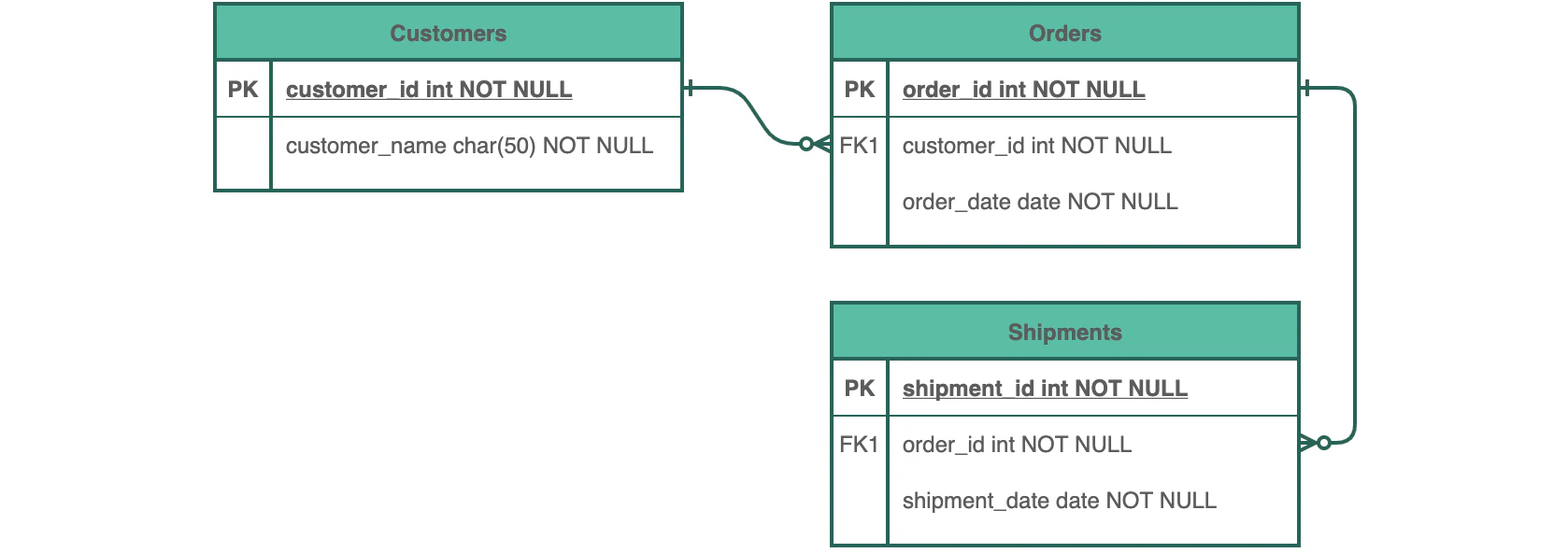
3.2 チューニング
**パフォーマンスの問題で非正規化を行う場合もあります。**非正規化することによって、特定のデータベースの下、高速に動作するように調整します。次の図は、スタースキーマの物理データモデルの例です。
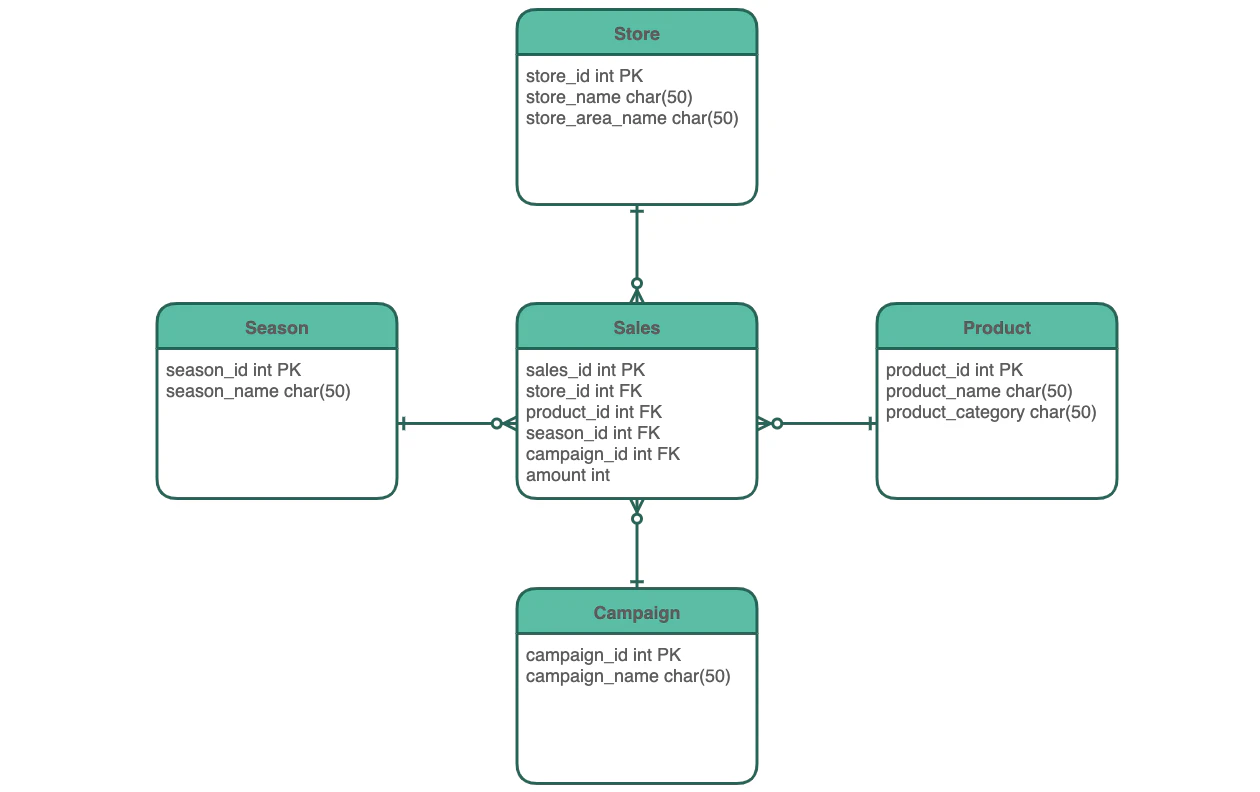
また、このタイミングで、インデックスの追加、パーティション分割、ビューテーブルやサロゲートキーの利用等もパフォーマンス次第で検討します。
データモデルの運用
概念、論理、物理レベルでそれぞれ構築されたデータモデルは、**本番環境と差異が出ないように維持していかなければいけません。**そのためには、開発フェーズの終わりに都度リバースエンジニアリングをして差異がないかを確認します。
また、データ要件の変更がある場合などでデータモデルを変更する際には、レビューと承認が必要です。データモデリングでは、データモデルの変更、レビュー、承認のサイクルを回していかなければなりません。
まとめ
本記事では、データモデルの構築と運用について DMBOK v2 の内容を参考に記述しました。データモデルの構築についてはある程度納得できたのですが、実運用でデータモデルの維持と更新管理を行うのはなかなか大変そうです。本番環境と日に日にずれていってしまう懸念があるので、実運用で上手くいった例などがあれば教えてください。
ER図のテンプレートは Entity Relationship Diagrams with draw.io を利用しました。