前回に続き、今回は重回帰分析を用いてアンケートデータを分析してみたいと思います。
重回帰分析とは、1つの目的変数を複数の説明変数で説明または予測する手法です。今回は以下のサイトより、大学の授業に関するアンケートデータを使用します。
①今回もRを使って分析します。まずはデータを読み込みます。
data <- read.csv("data6-4.csv")
head(data)

今回の分析では、「Evaluation(評価)」を目的変数、「Difficulty.level(難易度の高さ)」「Private.language(私語の多さ)」「Understanding(理解度の高さ)」を説明変数とします。それぞれの説明変数が、その授業の評価にどれだけ影響しているか、目的変数に対する説明変数の貢献度を分析します。
②変数間の相関を確認してみましょう。
cor(data)

難易度と評価には負の相関があることなどが分かります。
③続いて、lm関数を用いて重回帰分析を行い、結果を表示します。
output <- lm(data$Evaluation~data$Difficulty.level + data$Private.language + data$Understanding)
summary(output)
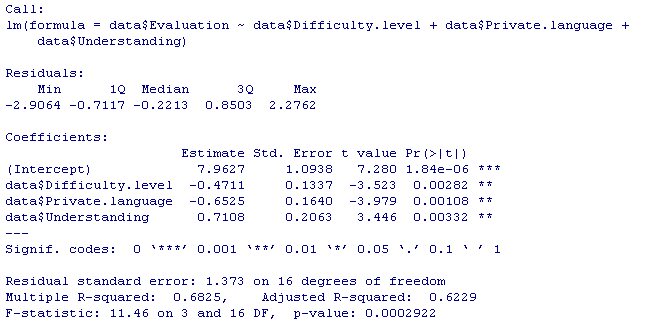
目的変数に対する、各説明変数の貢献度については、まずt値を示す「t value」に着目します。これはそれぞれの説明変数が目的変数に与える影響の大きさを表しており、絶対値が大きいほど影響が強いことになります。ここでは、難易度と私語がマイナス、理解度がプラスになっており、それぞれ目的変数に対して負の影響、正の影響があることが分かります。
次にp値を示す「Pr(>|t|)」を見てみましょう。これはそれぞれの説明変数が、統計的に有意であるかを示したもので、一般的には0.05未満かどうかで、その変数が統計的に意味を持つかを判断します。今回はいずれも0.05を下回っており、それぞれの説明変数は目的変数に対して有意な影響があると解釈できます。
このほか「Multiple R-squared」は決定係数を指し、モデルの説明力の高さ(当てはまりの良さ)を0~1で示しています。一般的に、この数値が0.5以上なら、ある程度の説明力があるとされており、今回は0.6825とまずまずの結果ということが分かります。
今回のデータから言えることは、内容が難しくて生徒の私語が多い授業は評価が低くなりやすく、分かりやすいと高くなりやすい、ということが伺えます。(当たり前と言えば当たり前ですが。。)
重回帰分析により、説明変数を元に目的変数を予測することも可能です。こちらについては、また別の機会に取り組んでみたいと思います。