今回は、アンケートの回答データを使って感情分析にチャレンジしてみたいと思います。感情分析を行うことで、自由回答中の語句から、回答者の態度がポジティブかネガティブかを判定します。
今回も以下URLより、「電子版お薬手帳を使いたい理由」に関する自由回答データを使用します。
「電子版お薬手帳に関する意識調査」を行いました
https://www.nicho.co.jp/corporate/newsrelease/11633/
①まずはライブラリをインポートします。今回はjanomeを使います。
import csv
from janome.tokenizer import Tokenizer
②次に「日本語評価極性辞書」をダウンロードし、読み込みます。これは、語句の判定に使う単語辞書のことで、例えば「誠実」はポジティブ、「弱気」はネガティブといったように、約8,500の表現に対してポジティブかネガティブかの紐付けがされています(下記URL参照)。
! curl http://www.cl.ecei.tohoku.ac.jp/resources/sent_lex/pn.csv.m3.120408.trim > pn.csv
np_dic = {}
fp = open("pn.csv", "rt", encoding="utf-8")
reader = csv.reader(fp, delimiter='\t')
for i, row in enumerate(reader):
name = row[0]
result = row[1]
np_dic[name] = result
if i % 500 == 0: print(i)
③対象データについて形態素解析を実施、各語句と上記の辞書を照らし合わせます。以下のコード中、「p」はポジティブ、「n」はネガティブ、「e」はどちらでもないニュートラルな語句を指しており、それぞれをカウントして、ポジティブ度とネガティブ度を判定します。
df = open("survey3.txt", "rt", encoding="utf-8")
text = df.read()
tok = Tokenizer()
res = {"p":0, "n":0, "e":0}
for t in tok.tokenize(text):
bf = t.base_form
if bf in np_dic:
r = np_dic[bf]
if r in res:
res[r] += 1
print(res)
cnt = res["p"] + res["n"] + res["e"]
print("Positive", res["p"] / cnt)
print("Negative", res["n"] / cnt)
結果は以下のようになりました。「電子版お薬手帳を使いたい理由」に関する回答なだけあって、やはりポジティブ度が高い結果になっています。
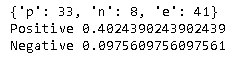
因みにこの調査では、「電子版お薬手帳を使いたくない理由」についても調べています。このデータで同様の分析をするとどうなるでしょうか。
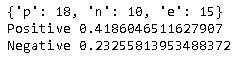
結果はこのようになりました。「使いたくない理由」にも関わらずポジティブ度がネガティブ度を上回っています。元の回答データを見ると、「紙の手帳のほうが良い」といった回答も散見され、上記のような結果になってしまったようです。このあたりはアンケート設計にも関わってくる部分になり、テキストマイニングの実施を前提にしている場合は留意が必要になりそうです。
参考サイト
読み放題のネット小説をネガポジ判定で評価してみよう
https://news.mynavi.jp/article/zeropython-58/