Window関数がMySQL8で使えるようになりました!
ワーイ♪☆彡(ノ゚▽゚)ノ☆彡ヘ(゚▽゚ヘ)☆彡(ノ゚▽゚)ノ☆彡ワーイ♪
Window関数って?
他のDBMSではおなじみ(でも、意外とWindow関数って名前は知らないで使ってるかも)の関数です。
PostgreSQLのドキュメントから引用すると、
ウィンドウ関数は現在の行に何らかとも関係するテーブル行の集合に渡って計算を行います。
これは集約関数により行われる計算の形式と似たようなものです。
とは言っても、通常の集約関数とは異なり、ウィンドウ関数の使用は単一出力行に行をグループ化しません。
行はそれぞれ個別の身元を維持します。
裏側では、ウィンドウ関数は問い合わせ結果による現在行だけでなく、それ以上の行にアクセスすることができます。
SQL において、窓関数もしくはウィンドウ関数 (英: window function) は結果セットを部分的に切り出した領域に集約関数を適用できる、拡張された SELECT ステートメントである。
とあります。
具体的には以下のようなものがウインドウ関数にあたります(関数を見てあーそれね、ってなるかも)
| 関数名 | 説明 |
|---|---|
| row_number() | 1からNまでの現在行の数を返す |
| rank() | 現在行の順位を返す(同率の番号を飛ばす) |
| dense_rank() | 現在行の順位を返す(同率の番号を飛ばさない) |
| percent_rank() | 現在行の相対順位比率。計算方法は(ランキング-1)/(全行数-1) |
| cume_dist() | 現在行の相対順位比率。計算方法は(ランキング/全行数) |
| ntile() | 行をバケット(1からN)に分割する |
| lag() | 前の行(または前の行の1つ)を返す |
| lead() | 後の行(または後の行の1つ)を返す |
| first_value() | 最初の行の値を返す |
| last_value() | 最後の行の値を返す |
| nth_value() | 1から数えたN番目の行の値を返す |
使い方を見てみましょう。
ROW_NUMBER()
1からNまでの現在行の数を返します。
並び順で1から最大行までの番号を採番するイメージです。
SELECT
row_number() over (order by hogehoge_id) as 'row_number',
hogehoge_id as 'PK_id',
...
FROM
hoge_table
;
というようにウインドウ関数では
関数名 OVER句 (ソートするカラム)
というように書きます。AS以下はカラムヘッダとしての見栄えの問題なのでなくても良いです。
ちなみに、
SELECT
row_number() over w as 'row_number',
hogehoge_id as 'PK_id'
...
FROM
hoge_table
WINDOW w as (order by hogehoge_id)
;
というようにWINDOW句を使ってwという別名でソートカラムを書いておき、OVER句の後ろにその別名を使う記載方法でも構いません。
(こっちのやり方のほうが複数同じソートカラムを使う場合には見やすいと思います)
結果イメージ
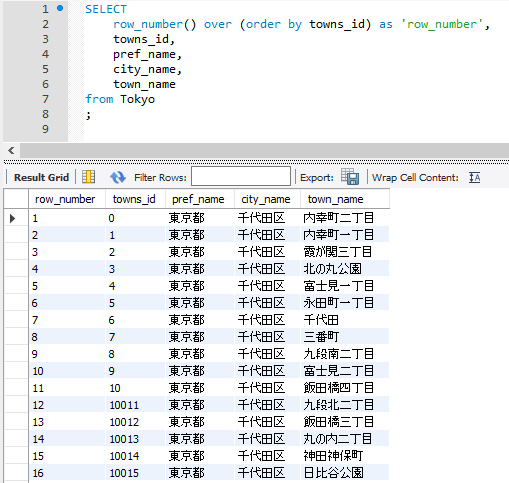
これは東京都の住所情報をTokyoテーブルとして作ってそれを元に表示した例ですが、towns_idが0から始まり10の次が10011となって値が飛んでいるのに対し、ROW_NUMBER()は1から順に並んでいるのが分かります。
採番し直しをしたい場合や、CSV形式のデータ出力をしたい場合などに良く使います。
※ちなみに元データは国土交通省の位置参照情報というものを使っています。
http://w3land.mlit.go.jp/cgi-bin/isj/dls/_choose_method.cgi
以下のようなテーブルを作って、東京都の大字・町丁目レベル位置参照情報のデータを入れてます。
CREATE TABLE `Tokyo` (
`towns_id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '大字・町丁目レベルID',
`pref_code` varchar(2) NOT NULL DEFAULT '' COMMENT 'JIS都道府県コード',
`pref_name` varchar(4) NOT NULL DEFAULT '' COMMENT '都道府県名',
`city_code` varchar(5) NOT NULL DEFAULT '' COMMENT 'JIS市区町村コード',
`city_name` varchar(20) NOT NULL DEFAULT '' COMMENT '市区町村名',
`town_code` varchar(12) NOT NULL DEFAULT '' COMMENT '大字・町丁目コード(JIS市区町村コード+独自7桁)',
`town_name` varchar(20) NOT NULL DEFAULT '' COMMENT '大字・町丁目名 (町丁目の数字は漢数字)',
`full_address` varchar(44) NOT NULL DEFAULT '' COMMENT '大字・町丁目レベル住所名(フル)',
`lat` double NOT NULL DEFAULT '0' COMMENT '十進経緯度(少数第6位まで、半角)',
`lon` double NOT NULL DEFAULT '0' COMMENT '十進経緯度(少数第6位まで、半角)',
`org_res_code` varchar(1) NOT NULL DEFAULT '0' COMMENT '原典資料コード 大字・町丁目位置参照情報作成における原典資料を表すコード 1:自治体資料 2:街区レベル位置参照 3:1/25000地形図 0:その他資料',
`aza_cho_code` varchar(1) NOT NULL DEFAULT '0' COMMENT '大字・字・丁目区分コード 1:大字 2:字 3:丁目 0:不明',
PRIMARY KEY (`towns_id`),
KEY `i_towns_1` (`city_code`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci ROW_FORMAT=DYNAMIC COMMENT='大字・町丁目レベル位置参照情報'
RANK()とDENSE_RANK()
両方とも現在行の順位を返します。
但し、RANKは同率順位が存在する場合、続く順位がその同率順位の数分ずれるのに対し、DENSE_RANKは1つずつ順位を付与していきます。
RANK()もDENSE_RANK()もROW_NUMBERと同じようにOVER句とソートカラム(ここでは順位に関係するカラム)を指定します。
実行例
事前にテーブルを用意してみます。
Tokyo_town_cntは上のデータを市区町村ごとに登録されていた大字町丁目の件数をtown_countとして登録したテーブルです。
CREATE TABLE `Tokyo_town_cnt` (
`towns_id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '大字・町丁目レベルID',
`pref_code` varchar(2) NOT NULL DEFAULT '' COMMENT 'JIS都道府県コード',
`pref_name` varchar(4) NOT NULL DEFAULT '' COMMENT '都道府県名',
`city_code` varchar(5) NOT NULL DEFAULT '' COMMENT 'JIS市区町村コード',
`city_name` varchar(20) NOT NULL DEFAULT '' COMMENT '市区町村名',
`town_count` int(11) NOT NULL DEFAULT 0 COMMENT '大字・町丁目件数',
PRIMARY KEY (`towns_id`),
KEY `i_towns_1` (`pref_code`,`city_code`)
) ENGINE=InnoDB AUTO_INCREMENT=15358 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci ROW_FORMAT=DYNAMIC COMMENT='大字・町丁目単位件数';
こんな感じで作って、以下のような感じでデータ入れてます。
insert into Tokyo_town_cnt(pref_code,pref_name,city_code,city_name,town_count) select pref_code,pref_name,city_code,city_name,count(1) from towns group by pref_code,pref_name,city_code,city_name;
そしてこんなクエリを流してみます
SELECT
ROW_NUMBER() over w as 'row_number',
city_name,
RANK() over w as 'town_count_rank',
DENSE_RANK() over w as 'town_count_d_rank',
town_count
FROM
Tokyo_town_cnt
WINDOW w as (order by town_count desc)
;
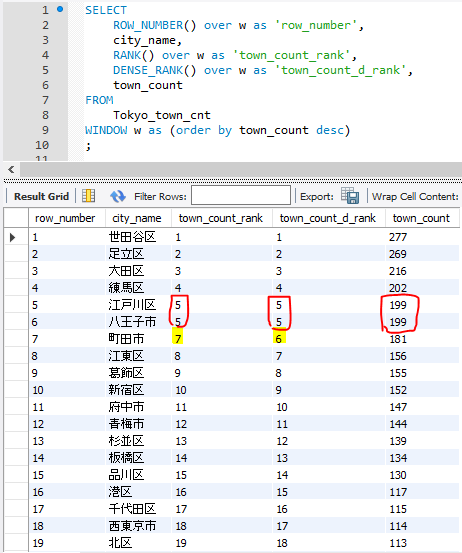
順位がRANKは5の次7と数字が飛んでいるのに対し、DENSE_RANKでは6になって飛んでいないことがわかります。
PERCENT_RANK() とCUME_DIST()
現在の行の値より小さいパーティション値の割合を返します。戻り値は0から1の範囲で、この式の結果として計算された行相対ランクを表します。
公式のを訳すとこんな感じですが、要するに順位をパーセンテージ化したものです。
違いはPERCENT_RANKが1位は対象外にするのに対し、CUME_DISTは1位から対象とするだけです。
書き方は同上(OVER句とソートカラム指定)です。
実行例
こんなクエリを流してみます(上で作ったテーブルをそのまま使用します)
SELECT
ROW_NUMBER() over w as 'row_number',
city_name,
PERCENT_RANK() over w as 'town_count_rank_p',
CUME_DIST() over w as 'town_count_count_rank_cd',
town_count
FROM
Tokyo_town_cnt
WINDOW w as (order by town_count desc)
;
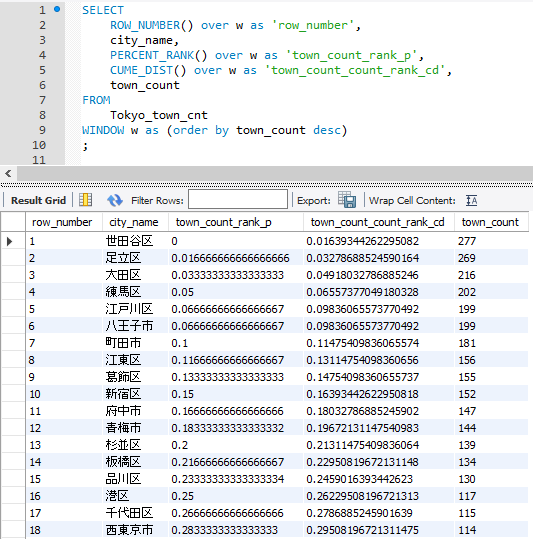
パーセンテージ化と言ってもMAXを1としての数値なので実際に%表示したい場合は×100したり、カラム表示を切り捨てたりすると良いと思います。
NTILE()
ntile()は行を指定した数字で等分割します。
もし10000行を1000に分ける場合、10行ずつ採番されます。
NTILE()関数については引数として分割したい数字をカッコ内に指定します。
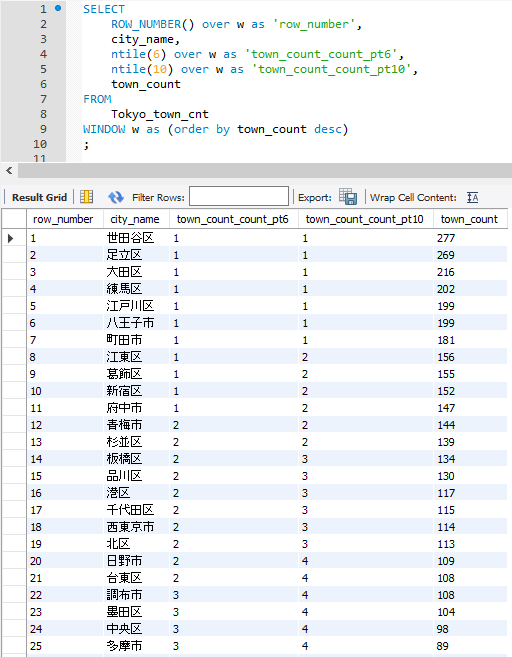
実行例
SELECT
ROW_NUMBER() over w as 'row_number',
city_name,
ntile(6) over w as 'town_count_count_pt6',
ntile(10) over w as 'town_count_count_pt10',
town_count
FROM
Tokyo_town_cnt
WINDOW w as (order by town_count desc)
;
Tokyo_town_cntに61件のデータが存在するのですが、上記のクエリを実行した場合、
6を指定したほうが約10行ずつ、10を指定したほうが約6行ずつに分割します。
ここで「約」と言ったのはあまりについては先頭グループに足されるので、先頭グループは若干多いので。
LAG()とLEAD()
LAGは1行前のレコードの値を、LEADは1行後のレコード値を出します。
使い道としては前行もしくは次の行とそのレコードの値の差分を出すのが良いと思います。
実行例
SELECT
ROW_NUMBER() over w as 'row_number',
city_name,
town_count,
LAG(town_count) over w as 'town_count_lag',
LEAD(town_count) over w as 'town_count_lead',
town_count - LAG(town_count) over w as 'sabun_lag',
town_count - LEAD(town_count) over w as 'sabun_lead'
FROM
Tokyo_town_cnt
WINDOW w as (order by town_count desc)
;
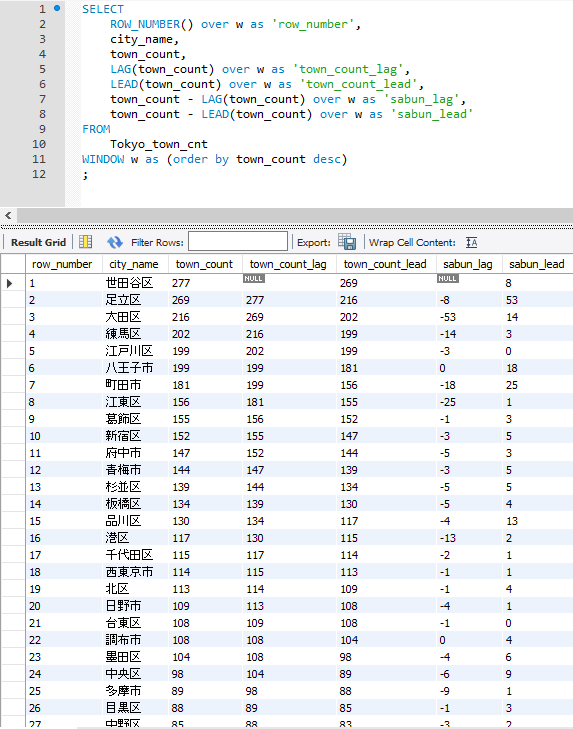
town_countに対し、LAGは前のレコードのtown_countを、LEADは後のレコードのtown_countを出しているのが分かるでしょうか。
そして、sabun_xxでは現在の値とLAG、LEADとの差分値を出しています。
FIRST_VALUE()、LAST_VALUE()とNTH_VALUE()
これは上のLAG・LEADとは違い、レコードの最初の値、最後の値、N番目の値を出すものです。
但し間違えてはいけないのが、最初とか最後とかN番目といっているのはそのレコードまでの間での話なので、
1行目だと対象カラムの値も、最初の値も、最後の値も同じものになり、N番目が1よりも大きな数字であればそこはNULLになります。
(イメージしにくいかもしれないので実行例に行ってみましょう)
実行例
SELECT
ROW_NUMBER() over w as 'row_number',
city_name,
town_count,
FIRST_VALUE(town_count) over w as 'town_count_1st',
LAST_VALUE(town_count) over w as 'town_count_last',
NTH_VALUE(town_count,3) over w as 'town_count_3rd'
FROM
Tokyo_town_cnt
WINDOW w as (order by town_count desc)
;
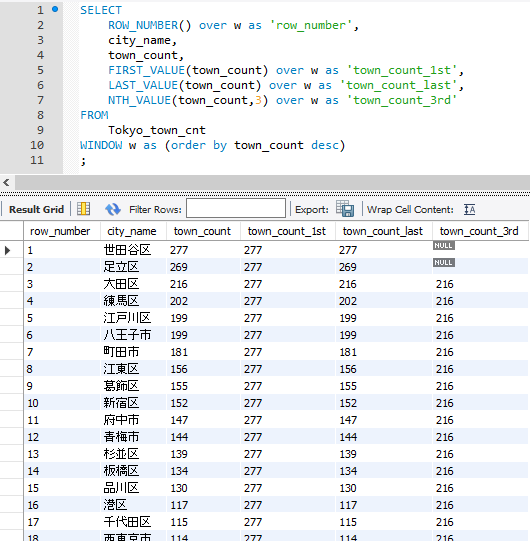
town_count_1stに入った値は先頭行の277が常に入っています。
town_count_lastには常にtown_countと同じ値になっています。(降順でtown_countをソートしているので最小値がtown_countだからです)
town_count_3rdの1行目と2行目はNULLです。3番目の値ということで3行目からが対象になっています。
最後に
ランクとか分析系は勿論のこと、データパッチやファイル出力など、地味なところでありがたみを感じるウインドウ関数。
MySQL8の環境ができたら、試してみてください。
(他のDBMSでは大抵入ってるので使ってなかったら試してみるのもアリかと)
あと、他のDBMSではPostgreSQLのEXCLUDE句(除外)のように更にオプションがあったりもするので、いずれMySQLでもウインドウ関数が更に改良されるかもしれません。
参照
https://dev.mysql.com/doc/refman/8.0/en/window-function-descriptions.html
https://www.postgresql.jp/document/9.4/html/tutorial-window.html
https://lets.postgresql.jp/documents/technical/window_functions/1
https://postd.cc/window_functions_postgresql/