はじめに
SQLについて、実務でなんとなく使ってきたが、ちゃんと勉強したことがないので実行環境作って勉強したいと思ったので作成してみた。
やっていく中で環境構築に結構苦労したので、もう一度再現できるように調べたことやできたことは記録したいと思い記載。
この記事に書いてあること
- SQLクエリをかいてデータ抽出ができるようになるまでの環境構築について(SQL serverをdockerで立ち上げて使用)
- わからなかったコマンドの意味や、自分がつまづいたところなども中心に記載
著者のレベル感
- 実務では既に接続できるデータベースやデータは用意されていて、SQLでデータ抽出して集計、ということはやっておりSQLの言語は一通りわかる
- 仮装サーバの立ち上げもやったことはあり、bashもなんとなくわかるが調べないとわからない
環境
- MacbookAir(2017)めちゃ古いです・・
- Visual Studio codeで接続
- dockerはインストール済み
プロセス
概要
おおまかなプロセスとしては以下
- SQLServerをdockerをつかって立ち上げる(≒SQLが使えるサーバーの立ち上げ、正確にはサーバーではなくコンテナ・・)
- 立ち上げたdockerコンテナにて、データベースを作成する
- データベースに接続する
- データベースにデータの中身をいれる
SQLserverが使えるdockerコンテナを立ち上げる
データベースが使える機能を保つSQLserverが入ったサーバーを立ち上げる必要がある、
今回は実行環境としてdockerコンテナを作成
dockerでSQLserverのコンテナを作る
コマンドラインで、docker上にMS SQLserverのイメージをローカル環境にダウンロードする
docker pull mcr.microsoft.com/mssql/server:2017-latest-ubuntu
コマンド解説
-
docker pull- Dockerイメージをリモートリポジトリ(この場合はMicrosoft Container Registry)からローカルマシンにダウンロードするコマンド
-
mcr.microsoft.com/mssql/server:イメージのリポジトリ名- この場合、Microsoftの公式Container Registry(MCR)にホストされているSQL Serverのイメージを指定しています。
-
:2017-latest-ubuntu:イメージのタグ(バージョンまたはバリエーション)の指定- 2017 は SQL Server のバージョンを示します(SQL Server 2017)。
latest はそのバージョンにおける最新のイメージを取得することを意味します。
ubuntu は、このイメージがUbuntuベースのLinuxディストリビューションであることを示します。
- 2017 は SQL Server のバージョンを示します(SQL Server 2017)。
docker pullのその他の例
docker pull nginx:latest
最新バージョンのNginx(ウェブサーバー)イメージを取得
docker pull python:3.10-slim
Python 3.10 の軽量(slim)バージョンを取得
docker pull mysql:8.0
MySQLデータベースのバージョン8.0を取得します。
dockerコンテナの実行=起動
取得したイメージでdockerコンテナを起動。これはsql_server_demoというで立ち上がった例
docker run -d --name sql_server_demo -e 'ACCEPT_EULA=Y' -e 'SA_PASSWORD=superStrongPwd123' -p 1433:1433 mcr.microsoft.com/mssql/server:2017-latest-ubuntu
コマンド解説
ACCEPT_EULA=Y:Microsoftのライセンス条項に同意する。
SA_PASSWORD:SQL Server の管理者ユーザー(sa)のパスワードを設定。
-p 1433:1433:ローカルポートとコンテナ内のポートをマッピング。
--name sql_server_demo:コンテナ名を設定。
-d:バックグラウンドでコンテナを実行。
データベースを作成する
上記だけだと、データベースを入れられる環境ができただけで、データベースそのものはできていない。
データベースを作成しないと、入れる箱がないも同然なので、データベースを作成する
dockerのコンテナに入り、SQLコマンドが使える状態にする
docker exec -it sql_server_demo /opt/mssql-tools/bin/sqlcmd -S localhost -U SA -P superStrongPwd123
このコマンドを実行すると、sql_server_demo という名前のコンテナ内で sqlcmd ツールを使い、SQL Serverに接続
接続後、インタラクティブなSQLコマンドプロンプトが開き、SQLクエリを実行できるように。
コマンド解説
-
docker exec- 実行中のDockerコンテナ内でコマンドを実行するためのコマンドです。
-
-it-
-i: インタラクティブモード(標準入力を有効にする)。 -
-t: 仮想端末(TTY)を割り当てます。コマンドを手動で操作できるようにするオプションです。
-
-
sql_server_demo
コマンドを実行する対象のコンテナ名です。この場合、コンテナ名がsql_server_demo です。 -
/opt/mssql-tools/bin/sqlcmd
コンテナ内で実行されるコマンドのパスです。これはSQL Server用のCLIツール sqlcmd を指します。 -
-S localhost
接続するSQL Serverのホスト名またはIPアドレスです。
この場合、localhost を指定しているので、コンテナ内のSQL Serverインスタンスに接続します。 -
-U SA
接続に使用するユーザー名です。
sa はSQL Serverのデフォルトのシステム管理者(Super Administrator)ユーザーです。 -
-P superStrongPwd123
接続に使用するパスワードです。ここでは superStrongPwd123 が指定されています。
データベースの作成
データベースがあるか確認
SELECT name FROM sys.databases;
GO
上記コマンドはSQLserverにデフォルトで存在するデータベースの一覧を出力してくれるもの。
通常は以下がリストアップされる。
name
--------------------------------
master
tempdb
model
msdb
(4 rows affected)
※各DBについて
- master: SQL Serverのシステム全体に関する情報を保持。 - tempdb: 一時データを保存するために使用。 - model: 新しいデータベース作成時のテンプレート。 - msdb: SQL Serverエージェントに関連するジョブ情報などを保存。ここに該当のデータベースがなければ、作成する
CREATE DATABASE sql_practice;
GO
作成後、同じコマンドで結果を確認
SELECT name FROM sys.databases;
GO
name
--------------------------------
master
tempdb
model
msdb
sql_server_demo
(5 rows affected)
VScodeでSQLserverを扱えるようにする
拡張機能でSQL Serverをインストール

コネクションを設定してデータベースに接続する
サイドバーの四角いアイコンをクリックし、「Add Connection」をクリック
設定画面が出てくるので、各項目を入力する
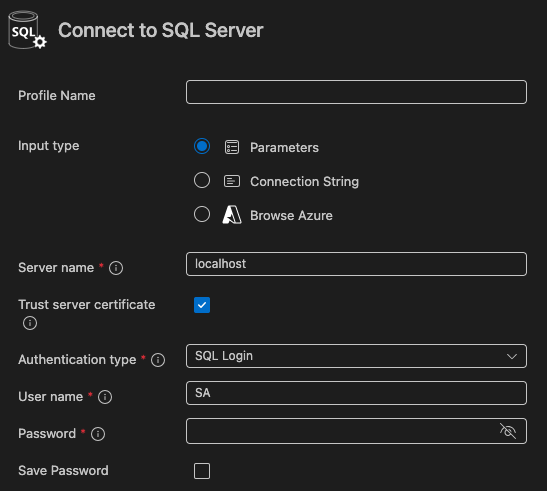
※場合によっては以下の画面が出てくる場合もあり、サーバー名から順番に聞かれる

- サーバー名
- localhost
- ユーザー
- dockerコンテナ作成するときに作成したユーザー名、今回は「SA」
- パスワード
- dockerコンテナ作成するときに作成したパスワード、今回は「superStrong~」で始まるもの
- データベース名
- 作成したデータベース名を指定、今回は「sql_practice」とした
ここまでで、実行環境の完成
データを入れる※更新中
データベースに接続できたので、実際にデータを入れていく。
まずは入れたいデータの用意と、
データを入れるようの箱=テーブルがないとデータが入れられないので、合わせてテーブル定義を作っていく
サンプルデータCSVの作成
chatgptでサンプルデータ作ってもらった(pythonコード付き・・!)
今回はアパレルのECストアのデータ分析を仮定して作成
- 購買データ
- 商品マスタ
- 購入ユーザーマスタ
テーブル定義を作る
create文を実行して、テーブルを作成
CREATE TABLE ProductMaster (
product_id INT PRIMARY KEY,
product_name NVARCHAR(255) NOT NULL,
category NVARCHAR(100) NOT NULL,
price INT NOT NULL
);
CREATE TABLE CustomerMaster (
customer_id INT PRIMARY KEY,
customer_name NVARCHAR(255) NOT NULL,
email NVARCHAR(255) NOT NULL,
signup_date DATETIME NOT NULL
);
CREATE TABLE PurchaseData (
customer_id INT,
product_id INT,
order_date DATETIME,
quantity INT,
price_per_item INT,
total_price INT,
FOREIGN KEY (customer_id) REFERENCES CustomerMaster(customer_id),
FOREIGN KEY (product_id) REFERENCES ProductMaster(product_id)
);
foreign keyの意味(chatgptに聞いた)
外部キー制約(Foreign Key Constraint)を定義しています。 外部キー制約は、テーブル間の関連性を確立し、データの整合性を保つために使用されます。FOREIGN KEY (customer_id) REFERENCES CustomerMaster(customer_id)
この部分は、PurchaseDataテーブルのcustomer_id列が、CustomerMasterテーブルのcustomer_id列を参照していることを示します。
つまり、PurchaseDataテーブルに記録されたすべてのcustomer_idは、CustomerMasterテーブルのcustomer_idと一致する必要があります。
これにより、PurchaseDataに登録されている顧客IDは、実際にCustomerMasterテーブルに存在する顧客IDであることが保証されます。もしCustomerMasterテーブルに存在しないcustomer_idをPurchaseDataテーブルに挿入しようとすると、エラーが発生します。
FOREIGN KEY (product_id) REFERENCES ProductMaster(product_id)
この部分は、PurchaseDataテーブルのproduct_id列が、ProductMasterテーブルのproduct_id列を参照していることを示します。
つまり、PurchaseDataテーブルに記録されたすべてのproduct_idは、ProductMasterテーブルのproduct_idと一致する必要があります。
これにより、PurchaseDataに登録されている製品IDは、実際にProductMasterテーブルに存在する製品IDであることが保証されます。もしProductMasterテーブルに存在しないproduct_idをPurchaseDataテーブルに挿入しようとすると、エラーが発生します。
- 外部キー制約の利点
- データの整合性を維持: 例えば、PurchaseDataに存在する顧客や製品が、実際には存在しない場合に挿入されないようにします。
- 親テーブルの変更に連動: 親テーブル(CustomerMasterやProductMaster)のデータが変更(削除や更新)されると、それに連動して子テーブル(PurchaseData)のデータも適切に変更されるように設定できます(ON DELETE CASCADEやON UPDATE CASCADEなどのオプションを使うことができます)。
簡単に言うと、この制約により、PurchaseDataテーブルに挿入されるデータは、必ずCustomerMasterおよびProductMasterテーブルに存在する有効なデータであることが保証されるわけです。
テーブルにデータを入れる
※ここはうまくいっていないところがあるので、うまくいき次第追記