ただの集団 Advent Calender PtW.2019の3日目の記事です。
昨日は、信頼してやまないkazuneeの[DjangoをTerraformでFargateにデプロイする話] (https://qiita.com/kazunee/items/329d8a99151383706ad8)でした ![]()
きっかけ
1時間ごとのログの集計にGlueを採用しました。
安心して使えるようになった今だからこそ書ける事を残しておきます ![]() (詳細は割愛
(詳細は割愛 ![]() )
)
この記事のターゲット 

- AWS Glueをこれから導入しようとしている人
- AWS Glueを既に使用していて、処理速度を改善したい人
図で見るAWS Glue 
よく見るアーキテクチャ図の中の、Glueはこんな感じ ![]()
ただ、Glueはこんなシンプルな図じゃ表しきれないぞ!!
実際はこんな感じ ![]()
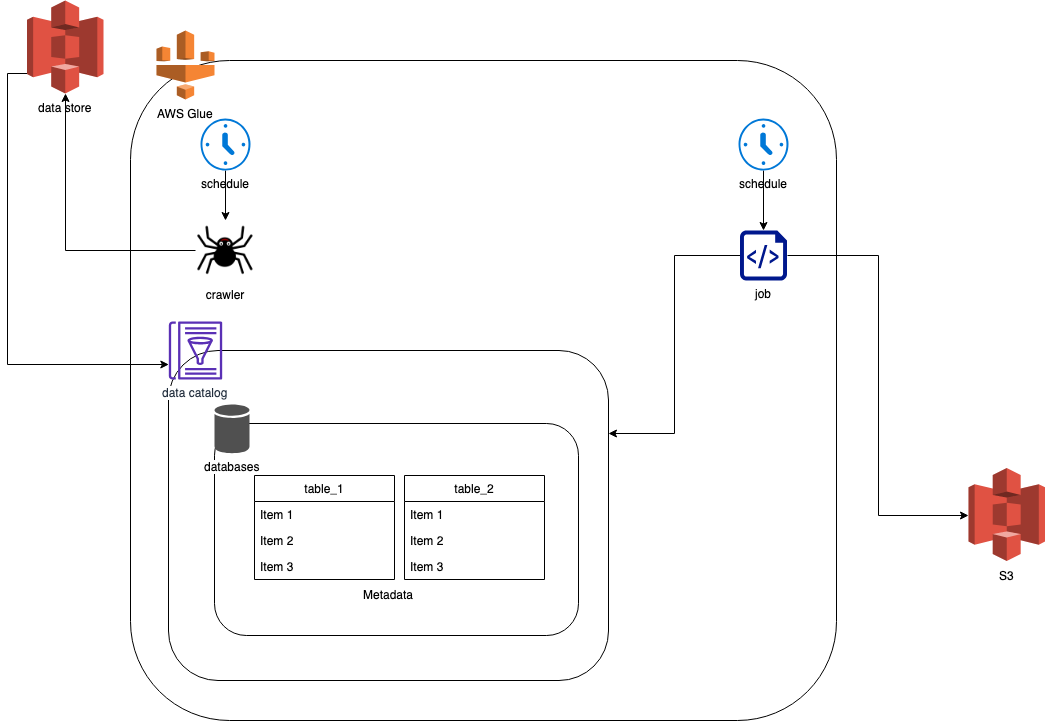
data store
- 今回Glueで処理したい生ログ
- 今回はS3
Glue
schedule
- crawlerとjobの2つ
- それそれ別で設定できる
- 生ログは、処理対象が多くなるのでこまめにクローリングするのがオススメ。
- いくつか試して、crawlerのscheduleは20分おきに収まりました。
- jobのschedulingは処理ETLしたい頻度によります。
crawler
- data storeからGlue内で処理するためのdata catalogを作る。
data catalog
- crawlerがdata storeから取り込んだデータ。
job
- ETLする場所。
- 言語はScalaとPython。
- 今回は、Scalaを使用。ただ、2018/1に使えるようになったばかりなので、Pythonに比べるとドキュメントは少め

- 今回は、Scalaを使用。ただ、2018/1に使えるようになったばかりなので、Pythonに比べるとドキュメントは少め
処理速度改善にオススメな事
ここまでは、Glueの基本的な事を書いてきました。ここからは、運用の話です。
背景
サービズが拡大するのは嬉しい ![]() サービスが拡大するって事は、ログも自然と増えますね!
サービスが拡大するって事は、ログも自然と増えますね!![]()
サービス拡大に当たって、Glueの処理速度の改善 ![]() が必要でした。ここで取り組んだ施策を2つ
が必要でした。ここで取り組んだ施策を2つ ![]() 紹介します。
紹介します。
施策1: クローリング対象のログを最小限に!
課題
jobが実行されるまでに、data catalogが揃っていない(可能性があった)
原因
生ログは指数関数的に増加していきます。crawlerがいくら差分でdata catalogに取り込んでいるが、job実行までにクローリングが終わっていない可能性があったため。
※あくまで可能性ですが、施策を実行した事で処理時間は短くなりました。
やった事
crawlerのためだけのS3を作成。かつ、lifecycle ruleを使って定期的にログの削除。今回は1週間ログを保存するようにしています。
resource "aws_s3_bucket" "for_crawler" {
count = 1
bucket = "for-crawler"
acl = "private"
lifecycle_rule {
enabled = true
expiration {
days = 7
}
}
}
AthenaでS3の生ログを分析する必要もあったので既存のシステムにプラスする形で、以下を実行しました。
- クローラー用のS3を追加
- ログを1のS3にも流すようにする
- クローリング先のS3バケットを変更
おまけ
クローリング対象を減らすだけだったら、exclusion patternという機能もあります。詳しくは、 ![]() 包含パターンと除外パターンを使用する
包含パターンと除外パターンを使用する
ただ、定期的に追加しないといけないなど管理コストがかかります。(lambdaとかで自動追加ならありです!)
施策2: パーティションを使って、ETL対象を最小限に!
課題
jobの実行時間が次第に伸びていく。(可能性があった)
1時間分のログの集計だったので、1時間以内に終わらないとどんどん遅延が発生する。
原因
data catalog内のデータは、クローリングすればするほど増えていたため。
やった事
- table定義にpartition追加。
- job内で処理対象のみdata catalogから読み込むようにする。
※S3のログのパスもpartitionに合わせる必要があります。
詳しくは ![]() Work with partitioned data in AWS Glue
Work with partitioned data in AWS Glue
table
resource "aws_glue_catalog_table" "summary_log" {
database_name = "database"
name = "summary_log"
table_type = "EXTERNAL_TABLE"
partition_keys {
name = "year"
type = "string"
}
partition_keys {
name = "month"
type = "string"
}
partition_keys {
name = "day"
type = "string"
}
partition_keys {
name = "hour"
type = "string"
}
}
job
import com.amazonaws.services.glue.GlueContext
import com.amazonaws.services.glue.DynamicFrame
import java.time.format.DateTimeFormatter
import java.time.ZonedDateTime
import java.time.ZoneId
object GlueApp {
def main(sysArgs: Array[String]) {
//...色々省略...
val targetHourJst = DateTimeFormatter.ofPattern("yyyy/MM/dd/HH").format(ZonedDateTime.now(ZoneId.of("Asia/Tokyo")))
val partitionPredicate = s"concat(year, '/', month, '/', day, '/', hour) = '$targetHourJst'"
val datasource0 = glueContext.getCatalogSource(
database = "database_name",
tableName = "table_name",
pushDownPredicate = partitionPredicate,
transformationContext = "datasource0"
).getDynamicFrame()
// ...Extractができたので、後はパーティショニングされたdatasource0を使ってtransform -> load処理していく...
}
}
まとめ
一部曖昧な表現がありますが、お許しください ![]()
![]()
快適なGlue lifeを送りましょう〜 ![]()