はじめに
YOLO(You Only Look Once)とは、その名の通り人間のように一度見ただけで物体の認識・検出をしてしまうという画期的なアルゴリズムです。
従来の手法に比べて、処理が高速であり物体と背景の認識の区別に強く、汎用化しやすいという特徴を持っています。
今回は、教材内でTiny YOLOとRを使って物体検出を行っている個所を、YOLOとpythonを使用して写真上の物体の検出を行っていきます。
教材
高等学校情報科「情報Ⅱ」教員研修用教材(本編):文部科学省
第3章 情報とデータサイエンス 後半 (PDF:7.6MB)
環境
- ipython
- Colaboratory - Google Colab
教材内で取り上げる箇所
学習18 テキストマイニングと画像認識:「3.TinyYOLOを利用した物体検出」
pythonでの実装例と結果
今回は、darknetをgithubのリポジトリからclone(コピー)し、YOLOv3の学習済み重みデータyolov3.weightsを使用して、画像認識を行います。
今回はpythonでの実装例と書いてありますが、darknetでYOLOv3を動かすためコマンドの実行を中心に行い、なるべく自前でコーディングしないような形で物体検出できるようにしていきたいと思います。
!git clone https://github.com/pjreddie/darknet
実行結果は以下のようになりました
Cloning into 'darknet'...
remote: Enumerating objects: 5913, done.
remote: Total 5913 (delta 0), reused 0 (delta 0), pack-reused 5913
Receiving objects: 100% (5913/5913), 6.34 MiB | 9.93 MiB/s, done.
Resolving deltas: 100% (3918/3918), done.
git cloneできたので、darknetディレクトリ配下に移動し、makeを実行します。
import os
os.chdir('darknet')
!make
makeが完了したら、YOLOv3の学習済み重みデータyolov3.weightsを同じディレクトリにダウンロードしておきます。今回はwgetコマンドを使用しました。
!wget https://pjreddie.com/media/files/yolov3.weights
本題の、YOLOで物体検出をさせたいと思いますが、今回はdataディレクトリ内のgiraffe.jpgを使用して、物体検出をしてみたいと思います。
!./darknet detect cfg/yolov3.cfg yolov3.weights data/giraffe.jpg
layer filters size input output
0 conv 32 3 x 3 / 1 608 x 608 x 3 -> 608 x 608 x 32 0.639 BFLOPs
1 conv 64 3 x 3 / 2 608 x 608 x 32 -> 304 x 304 x 64 3.407 BFLOPs
2 conv 32 1 x 1 / 1 304 x 304 x 64 -> 304 x 304 x 32 0.379 BFLOPs
3 conv 64 3 x 3 / 1 304 x 304 x 32 -> 304 x 304 x 64 3.407 BFLOPs
:
103 conv 128 1 x 1 / 1 76 x 76 x 256 -> 76 x 76 x 128 0.379 BFLOPs
104 conv 256 3 x 3 / 1 76 x 76 x 128 -> 76 x 76 x 256 3.407 BFLOPs
105 conv 255 1 x 1 / 1 76 x 76 x 256 -> 76 x 76 x 255 0.754 BFLOPs
106 yolo
Loading weights from yolov3.weights...Done!
data/giraffe.jpg: Predicted in 19.677707 seconds.
giraffe: 98%
zebra: 98%
キリン(giraffe)とシマウマ(zebra)が検出できました。
実際の検出された画像を見てみましょう。
from IPython.display import Image
Image("predictions.jpg")
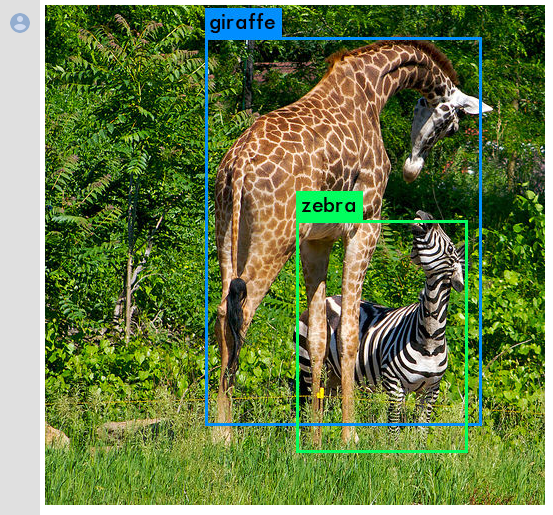
うまく検出できました。
ソースコード