Ubiregi Advent Calendar 2019 23日目の記事です。
はじめに
New Relic には Apdex という、簡易的なサービスレベル指標のようなスコアがあります。
https://newrelic.degica.com/docs/apm/new-relic-apm/apdex/apdex-measuring-user-satisfaction
SRE的な活動をはじめようとするとき、SLI/SLOを出すのに苦労すると思いますが、もし New Relic を使っている、または使えるなら、スモールスタートとしてこの Apdex を指標にすると良いと思います。
ユビレジでは改善系のチームでApdexスコアを参考にしていて、活動の結果0.94から0.97に改善できています。

Apdexスコアがこの数値になるまで改善を続ける、という見方であればこれで十分です。しかしApdexスコアが下がってきたとき、どこかで問題が起きているということは分かりますが、具体的にどこで問題が起きているかは頑張って探す必要があります。
サーバーサイドチームと共有したい
ユビレジには改善系のチームがいますが、すべての問題をシュッと対処できるわけではなく、サーバーサイドチームと協働したいと考えています。
New Relic でいろいろな情報を並べたダッシュボードを作れば、この辺で問題がありそう、というのは探し出せますが、たくさん並んでいる情報を見比べていくという状態だと、開発メンバーには受け入れてもらいにくいと感じています。
そこで、Apdexのようなものを機能ごとに算出できたら良いかも?と思いやってみました。
リクエストの成功率を算出する
どういった数値を出せばよいのかはサービス特性やシステムの現状によっても左右されると思います。
ユビレジは今年で10周年を迎えましたが、パフォーマンスが問題になることも増えてきています。
そのためレスポンスタイムの目標を決めて、目標を達成できていないリクエスト数も、エラーと同等に扱うことにしました。
成功率 = (リクエスト数 - (エラーの回数 + 目標のレスポンスタイムを超えてしまった回数)) / リクエスト数
機能ごとの 成功率 を算出して、1時間ごとに集計していきます。
(将来的に、1時間あたりの成功率が目標値を下回ったらアクションをとる、ということも見据えています。)
また、ユビレジは重い処理についてはWebのリクエストから非同期タスクを実行し、Pusherで同期するということをしています。
そのため非同期タスクの実行時間やエラーレートも重要で、同様に算出します。
Insights API からデータを抜き出す
New Relic には Insights という機能があります。これはAPMなどで取得されたデータを、NRQLというSQLライクな構文で検索できる機能で、APIも提供されています。
しかしこの機能、SQLの結合や副問合せのようなことが出来ず、そこは自分でやって外部に保存することにしました。
require 'time'
require 'optparse'
require 'faraday'
require 'google/cloud/bigquery'
params = ARGV.getopts("", "dry-run")
newrelic_account = ENV['NEWRELIC_ACCOUNT']
newrelic_query_key = ENV['NEWRELIC_QUERY_KEY']
conn = Faraday.new(url: "https://insights-api.newrelic.com/v1/accounts/#{newrelic_account}", headers: {"X-Query-Key": newrelic_query_key}) do |conn|
conn.request :retry, max: 2, interval: 300
conn.adapter Faraday.default_adapter
end
now = ARGV[0] ? Time.parse(ARGV[0]) : Time.now - 3600
since_time = now.strftime("%Y-%m-%d %H:00:00+0900")
until_time = (now + 3600).strftime("%Y-%m-%d %H:00:00+0900")
percentiles = [99.9, 99, 95, 50]
controller_duration_objective = ENV['CONTROLLER_DURATION_OBJECTIVE']
job_duration_objective = ENV['JOB_DURATION_OBJECTIVE']
response = {
transaction: conn.get("query", { nrql: "SELECT count(*), max(duration), percentile(duration, #{percentiles.join(',')}), uniqueCount(account) FROM Transaction FACET name SINCE '#{since_time}' UNTIL '#{until_time}' LIMIT 1000" }).body,
slow_transaction: conn.get("query", { nrql: "SELECT count(*), uniqueCount(account) FROM Transaction WHERE (transactionSubType = 'Controller' AND duration > #{controller_duration_objective}) OR (transactionSubType = 'ResqueJob' AND duration > #{job_duration_objective}) FACET name SINCE '#{since_time}' UNTIL '#{until_time}' LIMIT 1000" }).body,
error_transaction: conn.get("query", { nrql: "SELECT count(*), uniqueCount(account) FROM Transaction WHERE error IS true FACET name SINCE '#{since_time}' UNTIL '#{until_time}' LIMIT 1000" }).body,
dirty_exit: conn.get("query", { nrql: "SELECT count(*) FROM DirtyExit FACET class SINCE '#{since_time}' UNTIL '#{until_time}' LIMIT 1000" }).body,
unique_name: conn.get("query", { nrql: "SELECT uniques(name) FROM Transaction SINCE 7 days ago" }).body
}
response.transform_values! {|v| JSON.parse(v, {symbolize_names: true})}
timestamp = response[:transaction][:metadata][:beginTime]
data = response[:unique_name][:results].first[:members].map do |name|
{}.tap do |h|
h[:name] = name.gsub(/^Controller\/|^OtherTransaction\/ResqueJob\//, "")
h[:type] = case name
when /^Controller\// then "controller"
when /^OtherTransaction\/ResqueJob\// then "job"
else raise "Invalid name"
end
if trans = response[:transaction][:facets].find {|x| x[:name] == name}
result = trans.merge(*trans[:results])
h[:request_count] = result[:count]
h[:unique_account] = result[:uniqueCount]
if error = response[:error_transaction][:facets].find {|x| x[:name] == result[:name]}
h[:error_count] = error[:results][0][:count]
h[:error_unique_account] = error[:results][1][:uniqueCount]
else
h[:error_count] = 0
h[:error_unique_account] = 0
end
if slow = response[:slow_transaction][:facets].find {|x| x[:name] == result[:name]}
h[:slow_count] = slow[:results][0][:count]
h[:slow_unique_account] = slow[:results][1][:uniqueCount]
else
h[:slow_count] = 0
h[:slow_unique_account] = 0
end
if h[:type] == "job"
job_name = h[:name].gsub(/^(.*)\/.*$/, '\1')
if job = response[:dirty_exit][:facets].find {|x| x[:name] == job_name}
dirty_exit_count = job[:results].first[:count]
h[:request_count] += dirty_exit_count
h[:error_count] += dirty_exit_count
end
end
h[:response_time_max] = result[:max].round(3)
result[:percentiles].each do |percent, time|
h[:"response_time_percentile_#{percent.to_s.gsub(/\./, '_')}"] = time.round(3)
end
h[:success_rate] = ((h[:request_count] - (h[:error_count] + h[:slow_count])) / h[:request_count].to_f * 100).round(3)
end
h[:timestamp] = timestamp
end
end
if params["dry-run"]
pp data
else
bigquery = Google::Cloud::Bigquery.new(
project_id: ENV['BIGQUERY_PROJECT'],
keyfile: ENV['BIGQUERY_CREDENTIALS'],
retries: 10,
timeout: 5
)
bigquery.dataset("test").insert("sli_test", data)
end
これはひどい リクエスト数、エラー数、遅いリクエスト数、をそれぞれ別のリクエスト(NRQL)で取得して、スクリプト側でガッチャンコする、ということをしています。
ちなみに DirtyExit というのは、ユビレジは非同期タスクに Resque を使っており、メモリ枯渇などで Heroku から SIGKILL を受け取ったときに Resque::DirtyExit の例外が発生するのを別途モニタリングしています。
このスクリプトを実行すると、1時間あたりのリクエスト数やレスポンスタイムを、機能ごとに取得できます。
$ ruby app.rb --dry-run
...
{:name=>"hoge/fuga",
:type=>"controller",
:request_count=>259,
:unique_account=>0,
:error_count=>0,
:error_unique_account=>0,
:slow_count=>10,
:slow_unique_account=>1,
:response_time_max=>2.531,
:response_time_percentile_99_9=>1.938,
:response_time_percentile_99=>1.417,
:response_time_percentile_95=>0.863,
:response_time_percentile_50=>0.168,
:success_rate=>96.139,
:timestamp=>"2019-12-23T02:00:00Z"},
{:name=>"HogeWorker/perform",
:type=>"job",
:request_count=>339,
:unique_account=>342,
:error_count=>0,
:error_unique_account=>0,
:slow_count=>0,
:slow_unique_account=>0,
:response_time_max=>7.688,
:response_time_percentile_99_9=>7.435,
:response_time_percentile_99=>5.695,
:response_time_percentile_95=>4.643,
:response_time_percentile_50=>3.096,
:success_rate=>100.0,
:timestamp=>"2019-12-23T02:00:00Z"},
...
error_unique_account, slow_unique_account は、エラーや遅いリクエストを出しているユニークなユーザー数です。多くのユーザーで問題が起きているのか、特定のユーザーで問題が起きているのかも役立ちそうだと思い取得しています。
上記のデータからは
- Hoge#fuga のコントローラー・メソッドに
- 2019/12/23 09時〜 1時間あたり259リクエストあり
- レスポンスタイムの99パーセンタイルが1.4秒
- 遅いリクエストは1ユーザーで10回発生している
というようなことが窺えます。
HogeWorker/perform の方もジョブの実行回数や実行時間を取得できています。
このスクリプトを1時間に1回どこかで実行すれば、1時間ごとの集計ができます。
ユビレジは一部のバッチをECSスケジュールタスクで動かしており、今回はそこに乗せました。
BigQueryの準備
スクリプトの実行結果をBigQueryに保存していくためテーブルを作成します。
下記のようなスキーマを書いたJSONファイルを作成しておきます。
[
{
"mode": "REQUIRED",
"name": "name",
"type": "STRING"
},
{
"mode": "REQUIRED",
"name": "type",
"type": "STRING"
},
{
"mode": "NULLABLE",
"name": "request_count",
"type": "INTEGER"
},
{
"mode": "NULLABLE",
"name": "error_count",
"type": "INTEGER"
},
{
"mode": "NULLABLE",
"name": "slow_count",
"type": "INTEGER"
},
{
"mode": "NULLABLE",
"name": "unique_account",
"type": "INTEGER"
},
{
"mode": "NULLABLE",
"name": "error_unique_account",
"type": "INTEGER"
},
{
"mode": "NULLABLE",
"name": "slow_unique_account",
"type": "INTEGER"
},
{
"mode": "NULLABLE",
"name": "response_time_max",
"type": "FLOAT"
},
{
"mode": "NULLABLE",
"name": "response_time_percentile_99_9",
"type": "FLOAT"
},
{
"mode": "NULLABLE",
"name": "response_time_percentile_99",
"type": "FLOAT"
},
{
"mode": "NULLABLE",
"name": "response_time_percentile_95",
"type": "FLOAT"
},
{
"mode": "NULLABLE",
"name": "response_time_percentile_50",
"type": "FLOAT"
},
{
"mode": "NULLABLE",
"name": "success_rate",
"type": "FLOAT"
},
{
"mode": "REQUIRED",
"name": "timestamp",
"type": "TIMESTAMP"
}
]
作成。プロジェクトやデータセットの作成は割愛します。
$ bq mk --schema schema.json --time_partitioning_field timestamp --time_partitioning_expiration 63072000 PROJECT_ID:DATASET.sli_test
RedashをHerokuに構築する
社内でしか使わないような「ちょっとしたもの」をどこに立てるか。既に統合基盤があればそこに立てれば良いでしょう。
ユビレジは主にHerokuを活用しているのと、RedashはPostgreSQLを使うためHerokuとの相性も良さそう(HerokuのマネージドなPostgreSQLが使える)、ということでHerokuに立てました。
RedashをHerokuに立てるためのDockerfileがGitHubに公開されていて、これを使ってとても簡単に構築できました。作者様に感謝です。
https://github.com/willnet/redash-on-heroku
Redashで可視化してみる
Redashの細かい使い方は割愛しますが、雑なSQLを書いて登録してみました。
CREATE TEMP FUNCTION interval_day() AS (7);
CREATE TEMP FUNCTION day(timestamp TIMESTAMP) AS (timestamp_trunc(CAST(timestamp AS timestamp), day));
CREATE TEMP FUNCTION start_day() AS (day(timestamp_add(current_timestamp(), INTERVAL - (interval_day() * 24) HOUR)));
CREATE TEMP FUNCTION end_day() AS (day(current_timestamp()));
WITH unachieved AS (
SELECT
DISTINCT name
FROM
`test.sli_test`
WHERE
day(`timestamp`) BETWEEN start_day() AND end_day()
AND `type` = 'controller'
AND `success_rate` < 99.5
)
SELECT
`name`,
FORMAT_TIMESTAMP('%Y-%m-%d %H:%M:%S', timestamp_trunc(`timestamp`, hour), 'Asia/Tokyo') AS timestamp,
IFNULL(min(`success_rate`), 100) AS success_rate
FROM
`test.sli_test`
WHERE
day(`timestamp`) BETWEEN start_day() AND end_day()
AND `name` IN (SELECT `name` FROM unachieved)
GROUP BY `name`, `timestamp`
ORDER BY `name` ASC, `timestamp` ASC
成功率 (success_rate) が閾値を下回っている機能名の一覧を出し、その機能名の成功率を時系列で可視化します。
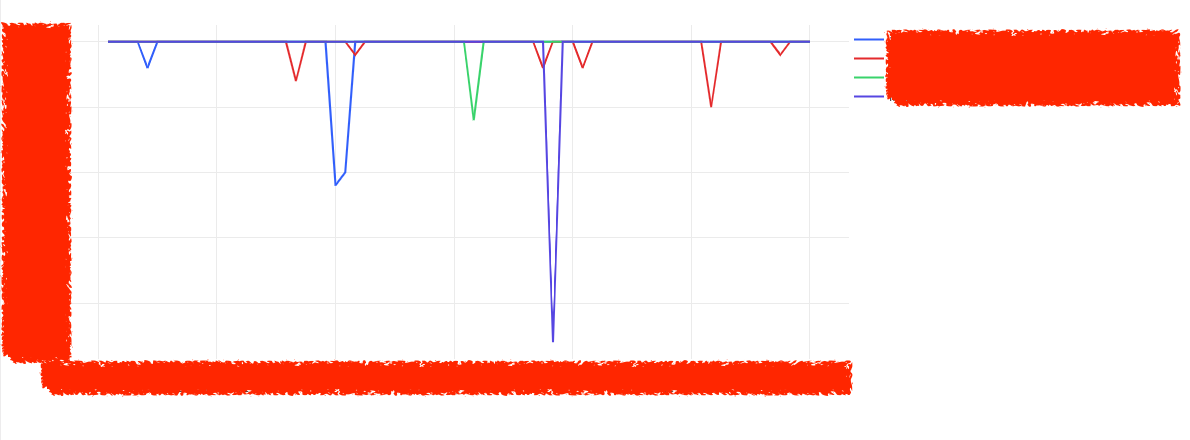
ほとんどモザイクやんけ 数値などはお見せできませんが、、、問題がありそうな機能の成功率を時系列で可視化することができました。
ただ、これだと「1時間に1回しかリクエストがないがその1回がコケたので成功率0%」みたいなものもあり、もう少しフィルターをどうにかしたいところです。
おわりに
これをチーム間に浸透していけるかはまた別のお話。