Yahoo! JAPAN Tech Blog向けに寄稿した記事を、会社の許可を得てこちらにも転載しています。
メッセージングPF「Apache Pulsar」の使い方(入門編) - Yahoo! JAPAN Tech Blog
こんにちは。ヤフー株式会社 システム統括本部クラウドプラットフォーム本部の水嶋と申します。私は現在、社内向けにキューイング・Pub-Sub・ストリーミングなどのメッセージングプラットフォームを提供するチームに所属しています。
このチームでは、メッセージングプラットフォームとしてOSS Apache Pulsar(以降、Pulsar)を利用しています。チームは数年間Pulsarを開発・運用しており、この経験からノウハウが蓄積されています。これらを公開し、皆さんにぜひPulsarについて興味を持っていただければと考えています。そこで、Pulsarの使い方、運用方法、ヤフーでの事例などをシリーズ記事として投稿していくことにいたしました。本稿に限らず、今後投稿予定の記事もぜひ読んでいただけると幸いです。
さて、今回は連載初回ということでPulsar入門編と題して大きく下記2点を紹介いたします。
- Pulsarの基本的な解説
- さまざまな機能
- Pulsarを構成するコンポーネント
- Pulsarの基本的な使い方
- 簡易的なサーバー起動
- サンプルコード実行
ヤフー社内におけるPulsar活用状況
私の所属するチームはPulsarがOSS化される2016年9月頃から携わっており、Pulsarのコミッターも複数名在籍しています。社内では、Pulsarを安定的にユーザーに利用していただけるように運用することに加えて社内における需要・事例をもとに機能拡張・バグ修正等の開発を通じたOSSへの貢献もしています。
ここで運用するPulsarを社内のプロダクトが利用することにより、プロダクトを開発するエンジニアはメッセージングプラットフォームを個別に運用する必要がなくなります。その結果、プロダクトは本来やるべきサービスやそれに伴うユーザー価値の創造に専念できるようになります。ヤフーとPulsarの関わりについては、直近で別記事を投稿しているのでこちらもご覧ください。
前提知識
Pulsarについて解説する前に、メッセージングシステムにおいて用いられる用語やPulsarで用いられる用語について説明します。
Producer/Consumer
Producerはメッセージの送信側、Consumerはメッセージの受信側と考えてください。あるいは、Pub-SubメッセージングなどではこれらをそれぞれPublisher/Subscriberと呼ぶこともあります。Pulsarでも、これらの用語が同じ意味で使われています。メッセージングシステムはProducerからメッセージを受信してConsumerに送信(あるいはConsumerが受信)します。このことをそれぞれProduce/ConsumeあるいはPublish/Subscribeと呼びます。
このようにメッセージングシステムによって中継されることで、メッセージ送信側のシステムと受信側のシステムの疎結合化が期待できます。
テナント/ネームスペース/トピック/サブスクリプション
Pulsarでは一般的なメッセージングシステムで用いられるトピックをさらに階層化していて、独自の用語と意味を持ちます。図1はそれぞれの大まかな包含関係を示しています。
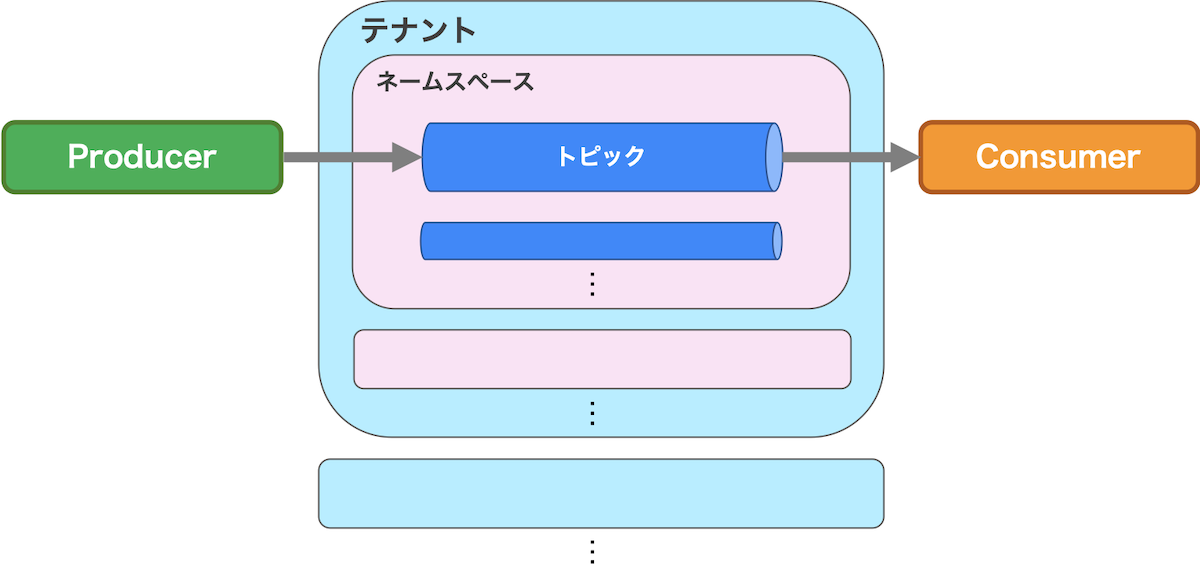
図1. テナント/ネームスペース/トピックの包含関係
まずトピックとは、メッセージをProduce/Consumeするときのエンドポイントと考えてください。次にネームスペースとは、トピックを束ねる空間のことです。このネームスペース単位でトピックに対する権限や制限などの設定を与えることでトピックを容易に管理できます。次にテナントとは、ネームスペースを束ねる空間のことです。
また、Pulsarではメッセージ送受信のエンドポイントであるトピックを次のような形式で指定する事ができます。
persistent://${テナント}/${ネームスペース}/${トピック}
最後にサブスクリプションとは、ConsumerがトピックをConsumeするときに使用する識別子です。図2はメッセージとサブスクリプションの関係を示すイメージです。このように、あるサブスクリプションを指定したConsumerがどこまでメッセージをConsumeしたかを管理しています。
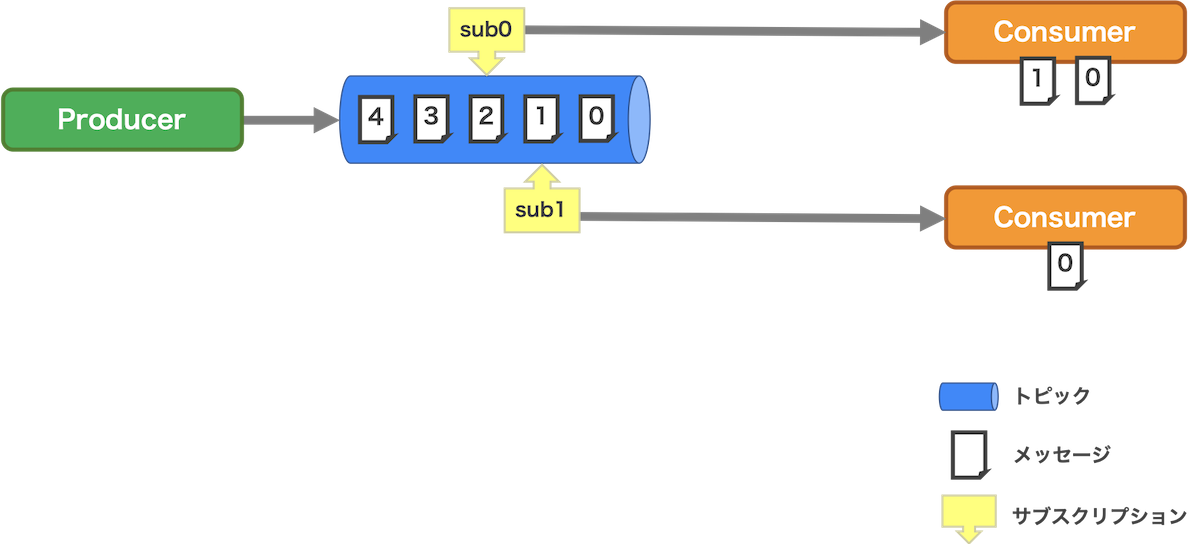
図2. サブスクリプションのイメージ
Pulsarの機能
Pulsarには基本的な機能や発展的な機能があります。ここでは、そのいくつかをピックアップして紹介いたします。
Pulsarの基本的な機能
Pulsarの基本的な機能として、次のような事項が挙げられます。
- 水平スケール可能
- 低レイテンシ
- マルチテナンシー
- システムやソフトウェアなどを複数の利用者で共有して利用できるような設計・構造であること
- 永続メッセージ
- 配信保証
運用面では特に水平スケール可能な点が特徴的で、単純なサーバー増設によりクラスタの処理性能を向上させることができます。なぜ水平スケールが容易であるかは後述のアーキテクチャの節で説明します。利用面では特にマルチテナンシーが特徴的で、複数の利用者で共有して利用できる設計・構造になっています。実際には、テナント管理者が配下のネームスペースを管理できる認証認可機構やネームスペースの全トピックに対してProduce/Consumeするための権限が設定可能であることなどによって実現されています。
Pulsarの発展的な機能
Pulsarの発展的な機能をいくつか紹介いたします。
サブスクリプションタイプ
前述したサブスクリプションにはいくつかの種類があります。現在(Pulsar v2.5.0)はExclusive, Failover, Shared, Key_Sharedの4種類で、それぞれ次のような働きをします。
-
Exclusive
- 1つのサブスクリプションを1つのConsumerだけがConsumeできる
-
Failover
- 1つのサブスクリプションに複数のConsumerが接続できる
- 最も優先度の高いConsumerだけがConsumeできるが、このConsumerがダウンしたとき次の優先度のConsumerがConsumeできるようになる
-
Shared
- 1つのサブスクリプションを複数のConsumerがConsumeできる
- メッセージがラウンドロビンに近い形でConsumerに配信される
-
Key_Shared
- 1つのサブスクリプションを複数のConsumerがConsumeできる
- ProducerはメッセージにKeyと呼ばれる識別子を付与して、同じKeyを持つメッセージは同じConsumerに配信される
- 同じKeyを持つメッセージの順序保証ができる
これらにより、Pulsarを導入するだけでメッセージングシステムへの複数の要件を満たすことができます。
複数のサーバーを使ったトピック処理能力の向上 (Partitioned Topics)
Pulsarでは通常トピックは1つのBrokerサーバー(ProducerとConsumerのメッセージ送受信を中継するPulsarのコンポーネント。詳しくは後述)によって処理されます。これはつまり、トピックに対するProduce/Consumeの処理能力は1つのBrokerサーバーの性能を超えないことを意味します。Partitioned Topicsではトピックを複数の内部トピックと呼ばれる通常トピックの集まりとして取り扱うことができるようになります。これにより内部トピックを複数のBrokerで処理することでトピックに対する処理能力の向上が期待できます。また、Producer/Consumerからは通常トピックと同じインターフェースで取り扱うことができます。
図3は、Partitioned Topicsのイメージです。詳細は、こちらもご覧ください。
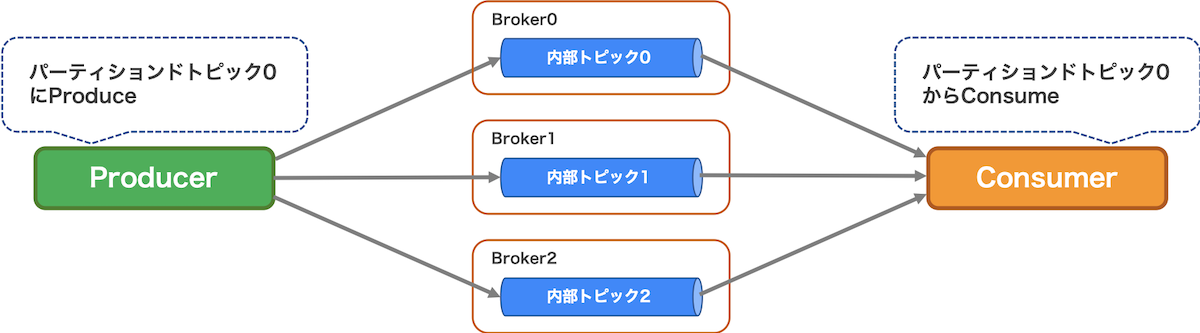
図3. Partitioned Topicsのイメージ
クラスタ間レプリケーション (Geo Replication)
Pulsarにはクラスタ間でメッセージを複製(レプリケーション)する機能があります。こちらを有効にすることで複数のクラスタで同じメッセージをConsumeできるようになります。これにより、Producerは別クラスタへの同じメッセージのProduceが不要になり、ConsumerはConsumerから近いPulsarのクラスタでのConsumeができるようになる利点があります。また、クラスタ間での冗長構成を作ることもできます。ただしメッセージは非同期に複製されるためPulsar上では完全な冗長化にはならない点に注意が必要です。
図4は、Geo Replicationのイメージです。青矢印のように、Pulsarの別のクラスタにあるトピックにメッセージを複製できます。詳細は、こちらもご覧ください。
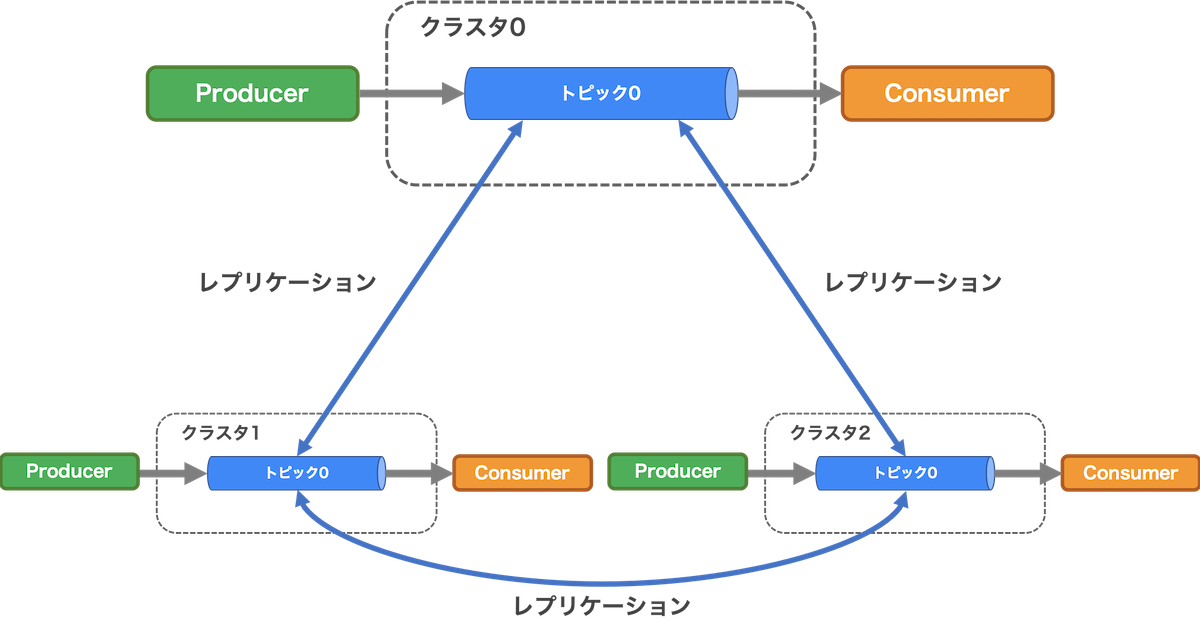
図4. Geo Replicationのイメージ
永続化ポリシー
前節で紹介したトピックの指定形式に対して付いていたpersistent とは、メッセージの永続化ポリシーを指します。このほかにnon-persistentというポリシーがあります。
persistent ポリシーはメッセージが永続化されることが保証されています。対して non-persistent ポリシーではメッセージは永続化されません。かわりに、Consumerへの高速な配信を実現できます。これらを要件に合わせてユーザーが適宜選択できます。詳細は、こちらもご覧ください。
コードによるメッセージの処理 (Pulsar Functions)
Pulsarには、トピックのメッセージに対してコードを記述して処理できる機能があります。ユーザーは処理に必要なコードを書くだけでこの機能を利用できます。
内部では具体的には、下記のようなフローで処理されます。
- トピックからメッセージをConsumeする
- ユーザーの書いたコードに沿ってメッセージを処理する
- 結果を他のトピックにProduceする
図5は、Pulsar Functionsのイメージです。このようなストリーム処理をPulsar以外のシステムなしで実現できます。詳細は、こちらもご覧ください。
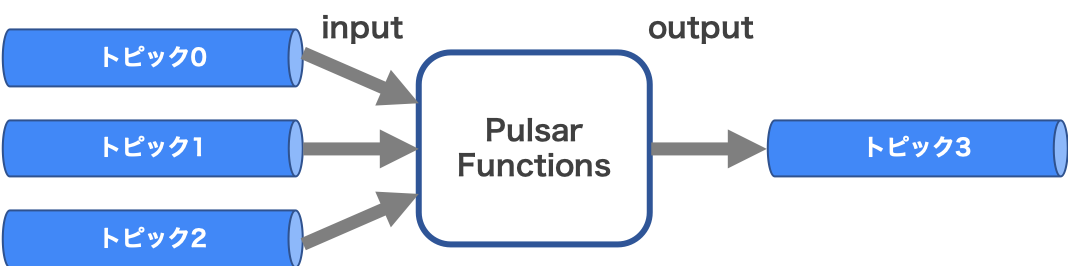
図5. Pulsar Functionsのイメージ
メッセージのクエリによる抽出 (Pulsar SQL)
ここでは紹介していませんが、Pulsarにはメッセージのスキーマを定義できる仕組みがあります。このスキーマを定義することで、SQLを用いてメッセージを抽出処理できます。仕組みとしてはPrestoを利用しています。詳細は、こちらもご覧ください。
Pulsarと他のシステムとの接続 (Pulsar IO)
Pulsarのメッセージングシステムとその他のシステムを接続してメッセージを送受信できます。これにより、例えばPulsarにメッセージをProduceしてそれをデータベースに格納することや他のMQからPulsarにメッセージをProduceするような仕組みを作ることができます。詳細は、こちらもご覧ください。
Pulsarのアーキテクチャ
Pulsarは、メッセージングプラットフォームとしてさまざまなケースで利用できます。ヤフーにおいてよく利用されているケースはこちらをご覧ください。
Pulsarはこのようなプラットフォームをどのようなアーキテクチャで実現しているかを見ていくことにします。図6は、Pulsarを構成する基本的なコンポーネントとアーキテクチャをまとめたイメージです。ただし、これ以外にもさまざまな機能のためのコンポーネントが存在します。
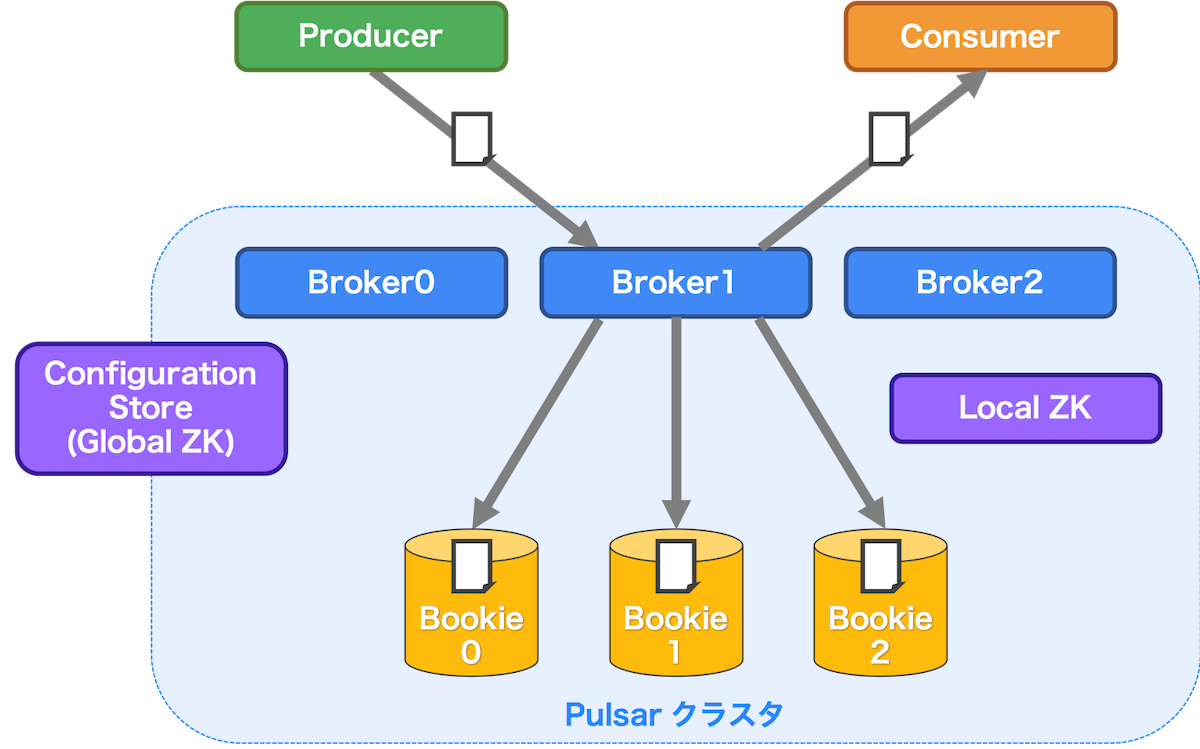
図6. Pulsar アーキテクチャイメージ
図6から、コンポーネントとして
- Broker
- Bookie
- ZK (ZooKeeper)
と呼ばれるものが存在していていることがわかります。また、Producer/ConsumerはBrokerを介してメッセージをやり取りしているようですが、その他にBrokerがBookieに対してメッセージを送信しているように見えるかと思います。これらが何を意味しているのか、それぞれのコンポーネントの役割とともに説明いたします。
Broker
Brokerは、その名の通りProducer/Consumerのメッセージのやり取りを仲介する役割を担います。加えて、前述したGeo Replicationを実現するための機能やテナント、ネームスペースの作成・権限設定などを行うREST APIを提供します。
Bookie
ソフトウェア名としては、Apache BookKeeperと呼ばれるストレージシステムを利用しています。Apache BookKeeperでは、メッセージを保存するサーバーのことをBookieと呼びます。Bookieには、メッセージに加えてサブスクリプションがメッセージのどの位置までConsumeしたかを管理するカーソルと呼ばれる情報も保存します。このようにメッセージを格納することで、もし障害発生などの理由でConsumerがメッセージを受信できなかったときもメッセージを再送して処理できます。Brokerから複数のBookieに対してメッセージが送信されているように見えるのは、Bookieでは同じデータを複数のBookieに保存できるからです。Broker側で設定したメッセージ(より正確にはBookieのEntriesという概念)の書き込み台数に応じていずれかのBookieに書き込まれます。これにより、1台のBookieに障害が発生したとしてもメッセージを引き続き読み出すことができます。
ZK (ZooKeeper)
ソフトウェア名としては、Apache ZooKeeper(以降、ZooKeeper)と呼ばれるメタデータストアシステムを利用しています。Pulsarでは、ZooKeeperを下記の2種類の使い方に分けて別プロセスで起動します。
- Configuration Store
- Pulsarのすべてのクラスタで共通する設定情報(例: テナント、ネームスペースなど)を保持します
- Local ZooKeeper
- Pulsarのそれぞれのクラスタで独立した設定情報(例: Broker、Bookieのメタデータなど)を保持します
水平スケール
Pulsarの機能にて前述したとおり、Pulsarの基本的な機能の中に水平スケールが可能であることを挙げています。この要因の一つにBrokerとBookieで役割が分かれていることがあります。
例えば、メッセージ書き込みの負荷が高くなってきたときはBookieだけを増設して配置するだけで良いです。Bookieは特徴としてスケーラブルであり、増設時に他のBookieの設定を変更することなく配置できます。同様にProducer/Consumerからのアクセス増加によって負荷が高くなってきたときは、Brokerだけを増設して配置するだけで負荷を分散できます。これは、Brokerはデータを永続化しておらずステートレスであるからです。
この仕組みに対照的なのは、例えばApache Kafka(以降、Kafka)が挙げられます。Kafkaは基本的なコンポーネントはBrokerとZooKeeperによって構成されています。Kafkaにもメッセージの永続化の仕組みはありますが、こちらはBrokerに保存される仕組みです。このため、新しいBrokerサーバーを追加したとしても既存のBrokerから新規のBrokerへと自動的に負荷が分散されることはありません。
Hello Pulsar
ここからは、Pulsarを実際に使ってみるための一連の手順を紹介します。前提として、Pulsarにはstandaloneと呼ばれるBroker, Bookie, ZooKeeperが一つのJVMプロセスとして起動可能なモードが存在しています。今回は、このstandaloneモードでPulsarを立てて、Javaクライアントを使ってProducer/Consumerを作成してみます。
前提
まず、今回の環境構築はmacOSもしくはLinuxで行う想定です。また、standaloneモードはデフォルトで2GBのメモリを必要とします。ちなみに、この手順は基本的に公式ドキュメントに準拠しています。
Java11 インストール
JDK 11より、Java11をインストールします。
Pulsarのダウンロードと展開
下記コマンドを使ってPulsar v2.5.0をダウンロードします。
$ wget https://archive.apache.org/dist/pulsar/pulsar-2.5.0/apache-pulsar-2.5.0-bin.tar.gz
ダウンロードが完了したら、下記コマンドを使ってPulsarを展開して移動します。
$ tar xfz apache-pulsar-2.5.0-bin.tar.gz
$ cd apache-pulsar-2.5.0
Pulsarの起動とテナント・ネームスペースの作成
上記に続いて下記コマンドを使ってstandaloneモードのPulsarを起動します。
$ bin/pulsar standalone
上記とは別のターミナルを用意して、上記と同じディレクトリまで移動してください。下記コマンドを使ってサンプルコードで利用するテナント・ネームスペースを作成します。ちなみにデフォルトの設定ではトピックはProduce/Consumeする際に自動的に作成されます。
$ bin/pulsar-admin tenants create my-tenant
$ bin/pulsar-admin namespaces create my-tenant/my-namespace
サンプルコード
Producer
HelloProducer.java
package pulsar.hello;
import org.apache.pulsar.client.api.PulsarClient;
import org.apache.pulsar.client.api.Producer;
class HelloProducer {
public static void main(String[] args) throws Exception {
PulsarClient pulsarClient = PulsarClient.builder()
.serviceUrl("pulsar://localhost:6650")
.build();
Producer<byte[]> producer = pulsarClient.newProducer()
.topic("persistent://my-tenant/my-namespace/my-topic")
.create();
for (int i = 0; i < 10; i++) {
// メッセージを送信する
producer.send(String.format("my-message-%d", i).getBytes());
}
pulsarClient.close();
}
}
Consumer
HelloConsumer.java
package pulsar.hello;
import org.apache.pulsar.client.api.PulsarClient;
import org.apache.pulsar.client.api.Consumer;
import org.apache.pulsar.client.api.Message;
class HelloConsumer {
public static void main(String[] args) throws Exception {
PulsarClient pulsarClient = PulsarClient.builder()
.serviceUrl("pulsar://localhost:6650")
.build();
Consumer<byte[]> consumer = pulsarClient.newConsumer()
.topic("persistent://my-tenant/my-namespace/my-topic")
.subscriptionName("my-subscription-name")
.subscribe();
for (int i = 0; i < 10; i++) {
// メッセージを受信する
Message msg = consumer.receive();
System.out.println("Received message: " + new String(msg.getData()));
// BrokerにACKを返す
consumer.acknowledge(msg);
}
pulsarClient.close();
}
}
pom.xml
Mavenを利用していることが前提ですが、<dependencies>ブロック内に下記を追加してください。
<dependency>
<groupId>org.apache.pulsar</groupId>
<artifactId>pulsar-client</artifactId>
<version>2.5.0</version>
</dependency>
コード実行
上記サンプルコードをビルドして
- Consumer
- Producer
の順に別々のターミナルで起動します。すると、Consumerの標準出力に下記のようなメッセージが出力されることが確認できます。
Received message: my-message-0
Received message: my-message-1
Received message: my-message-2
Received message: my-message-3
Received message: my-message-4
Received message: my-message-5
Received message: my-message-6
Received message: my-message-7
Received message: my-message-8
Received message: my-message-9
このように、比較的簡潔なクライアントの仕様のため簡単に初期導入できます。
終わりに
第1回は以上です。全体をおさらいすると、下記のような内容を書きました。
- Pulsarの基本的な解説
- さまざまな機能
- Pulsarを構成するコンポーネント
- Pulsarの基本的な使い方
- 簡易的なサーバー起動
- サンプルコード実行
少しコンテンツが多かったかもしれませんが、もし深堀りしたい話などありましたら適宜配置したリンクにも詳細がありますので参考にしてください。次回は少しコンテンツを絞って、クライアントのコードについてより応用的な機能を紹介する予定です。今回は前半で紹介した機能の実際の使い方を説明できなかったため、そのあたりを補完したいと考えています。
ここで紹介ですが、PulsarコミュニティではPulsar Summitというサミットの開催が計画されているようです。個人的には、コミュニティがどのように盛り上がっているかを知る機会になるのではないかと思います。GitHub上でも積極的なIssue, PRが続いておりコミュニティが盛り上がりつつあることが感じられます。余談ですが、私はPulsarを開発・運用するチームに所属して5カ月程度と非常に浅い期間しか見ていませんが、それでも毎日のようにコミュニティが動いているのを見て、以前よりPulsarが改善されているのを実感しています。今後もどのような動向かを見ていきたいと考えています。
それでは不定期での投稿になるかと思いますが、次回もお楽しみに!