これは Elasticsearch Advent Calendar 2014 16日目の記事です。
2014年12月上旬、社内SNS Talknote の検索機能の一部に Elasticsearch を導入しましたので
そこで使用した parent-child relationship についての事例を紹介します。
Elasticsearch のバージョンは執筆時点で最新の 1.4.1 を対象とします。
(1.3.x でも問題無いと思います)
はじめに
parent-child relationship とは、異なるインデックスタイプのドキュメント間に親子関係を持たせることで
SQL でいうテーブルの結合(JOIN)のような処理をして検索することが出来ます。
ただし、現時点では SQL ほどの複雑な結合条件を書くことができないため注意が必要です。
このあたりは今後のバージョンアップに期待、といったところでしょうか。
Talknote で投稿を検索したイメージ
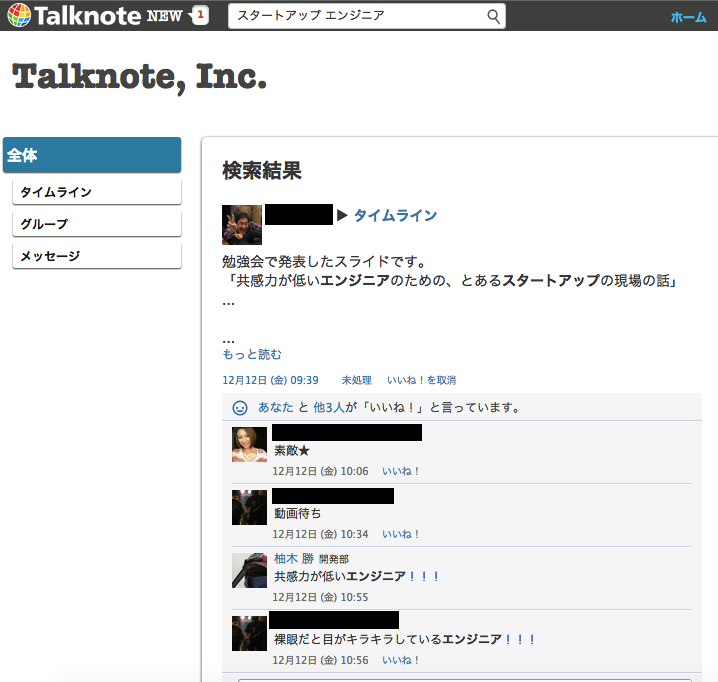
Talknote では、1つの投稿に複数のコメントを付けることができます。
検索機能は、キーワードが投稿またはコメントに含まれていれば
その投稿とコメントの一覧を投稿日時順に並べて表示する仕様となっています。
削除されたデータの扱いは、削除された投稿はそのコメントを含め検索対象に含まれないようにし、
削除されたコメントはそのコメントが検索対象に含まれないようにします。
なお、キーワードのハイライトは JavaScript で正規表現を駆使して実装しています。
Elasticsearch(Lucene)のハイライトも検討したのですが、HTMLタグを含むドキュメントに html strip char filter を使っていると、HTMLタグが<a><b></a></b>のように交差してしまうケースがあったため今回は使用を見送りました。
データ移行前のスキーマ
現在 Talknote はデータストアに Amazon RDS for MySQL を使用しています。
Elasticsearch へ流し込む元データは、下記のような親子関係のあるテーブルに格納されています。
※ここに書かれているテーブル定義は parent-child relationship の説明に不要な情報を取り除いたもので、実際のものとは異なります。
messages テーブル(親テーブル)
| カラム名 | 型 | 制約 | |
|---|---|---|---|
| 1 | message_id | int | Primary Key |
| 2 | message | text | Not Null |
| 3 | created_at | datetime | Not Null |
| 4 | updated_at | datetime | Not Null |
| 5 | delete_flag | int | Not Null |
message_comments テーブル(子テーブル)
| カラム名 | 型 | 制約 | |
|---|---|---|---|
| 1 | message_comment_id | int | Primary Key |
| 2 | message_id | int | Foreign Key |
| 3 | message_comment | text | Not Null |
| 4 | created_at | datetime | Not Null |
| 5 | updated_at | datetime | Not Null |
| 6 | delete_flag | int | Not Null |
データ移行後のスキーマ
上記2つのテーブルに格納されているデータを、下記4つのインデックスタイプにマッピングしました。
(全て1つのインデックスへ入れます)
今回 Elasticsearch のインデックステンプレート(詳しくは後述)には
"_source": { "enabled": false }
を指定し、元のドキュメントを持たせないようにしています。
加えて、現時点では必要なかったこともあり
"_all": { "enabled": false }
も指定しました。
_sourceを無効化したことで削除フラグの更新に差分アップデートを使うことができなくなるため
別途、削除フラグに相当するインデックスタイプを子ドキュメントとして設けることにしました。
(投稿が削除されるのは全体から見てわずかという事情もあります)
また、Amazon SQS を経由して Elasticsearch へデータを同期しているため、
投稿後にすぐ削除された場合など、順序保証の無い Amazon SQS では index アクションよりも delete アクションが先に実行されてしまうことも考えられるので
オンラインでの同期処理は index アクションのみとし、delete アクションは一定時間経過後にバッチ処理で削除するという仕様としました。
パフォーマンス上の懸念はありますが、今は公開範囲を絞っていることと、検索自体が使用頻度の高い機能ではないため、それほど大きな問題とはなっていません。
(後述する N-gram(min_gram: 1, max_gram: 2) といい、性能面では悪い判断でしょう)
messages インデックスタイプ(親ドキュメント)
| カラム名 | 型 | 同期元カラム名 | |
|---|---|---|---|
| 1 | message_id | integer | messages.message_id |
| 2 | message | string | messages.message |
| 3 | created_at | date | messages.created_at |
| - | _id | string | messages.message_id |
| - | _parent | string | - |
| - | _routing | string | messages.message_id |
deleted_messages インデックスタイプ(子ドキュメント)
| カラム名 | 型 | 同期元カラム名 | |
|---|---|---|---|
| 1 | message_id | integer | messages.message_id |
| 2 | created_at | date | messages.updated_at |
| - | _id | string | messages.message_id |
| - | _parent | string | messages.message_id |
| - | _routing | string | messages.message_id |
message_comments インデックスタイプ(子ドキュメント)
| カラム名 | 型 | 同期元カラム名 | |
|---|---|---|---|
| 1 | message_comment_id | integer | message_comments.message_comment_id |
| 2 | message_id | integer | message_comments.message_id |
| 3 | message | string | message_comments.message_comment |
| 4 | created_at | date | message_comments.created_at |
| - | _id | string | message_comments.message_comment_id |
| - | _parent | string | message_comments.message_id |
| - | _routing | string | message_comments.message_id |
deleted_message_comments インデックスタイプ(孫ドキュメント)
| カラム名 | 型 | 同期元カラム名 | |
|---|---|---|---|
| 1 | message_comment_id | integer | message_comments.message_comment_id |
| 2 | created_at | date | message_comments.updated_at |
| - | _id | string | message_comments.message_comment_id |
| - | _parent | string | message_comments.message_comment_id |
| - | _routing | string | message_comments.message_id |
_idはインデックスタイプ内でのドキュメントのID
_parentは子ドキュメントから見た親ドキュメントのID、孫ドキュメントから見た子ドキュメントのID
_routingはルートとなる親ドキュメントのID
となります。
_routingを明示的に指定している理由は、孫ドキュメントで_routingを指定し忘れ
(この場合は_parentが使われます)
コメントの削除フラグドキュメントが他のシャードへ行ってしまい
画面上で削除したのに検索にはマッチしてしまうバグがリリース直前に見つかったからです・・・
開発中はnumber_of_shardsを1にしていたため、このバグに気付くことが出来ませんでした。
parent-child を使用する場合は、_routingの明示的な指定と、開発中からnumber_of_shardsに大きめの数値を指定することを心掛けたほうが良いでしょう。
インデックステンプレート
最終的に、インデックステンプレートは下記のようになります。
※本番環境で動かす場合にはnumber_of_replicasに1以上を指定しましょう。
トークナイザですが、形態素解析は特に必要ではなかったため Kuromoji は使わず、
N-gram(min_gram: 1, max_gram: 2) と match_phrase クエリで
RDBMS でのLIKE検索に近い結果となるようにしました。
(日本語では形態素解析とN-gram(min_gram: 2, max_gram: 3)の組み合わせが定番です)
icu_normalizerとicu_foldingは大文字/小文字、半角/全角を区別なくマッチさせるために指定しています。
(濁点、半濁点の区別もなくなってしまいます)
※実行には elasticsearch-analysis-icu プラグインのインストールが必要になります。
{
"template": "message_index",
"settings": {
"index": {
"number_of_shards": 10,
"number_of_replicas": 0,
"analysis": {
"analyzer": {
"message_analyzer": {
"type": "custom",
"tokenizer": "message_ngram_tokenizer",
"filter": [ "icu_folding" ],
"char_filter": [ "html_strip", "icu_normalizer" ]
}
},
"tokenizer": {
"message_ngram_tokenizer": {
"type": "ngram",
"min_gram": 1,
"max_gram": 2,
"token_chars": [ "letter", "digit", "punctuation", "symbol" ]
}
}
}
}
},
"mappings": {
"_default_": {
"_source": { "enabled": false },
"_all": { "enabled": false }
},
"messages": {
"_id": { "path": "message_id" },
"properties": {
"message_id": { "type": "integer" },
"message": { "type": "string", "analyzer": "message_analyzer" },
"created_at": { "type": "date" }
}
},
"message_comments": {
"_id": { "path": "message_comment_id" },
"_parent": { "type": "messages" },
"properties": {
"message_comment_id": { "type": "integer" },
"message_id": { "type": "integer" },
"message": { "type": "string", "analyzer": "message_analyzer" },
"created_at": { "type": "date" }
}
},
"deleted_messages": {
"_id": { "path": "message_id" },
"_parent": { "type": "messages" },
"properties": {
"message_id": { "type": "integer" },
"created_at": { "type": "date" }
}
},
"deleted_message_comments": {
"_id": { "path": "message_comment_id" },
"_parent": { "type": "message_comments" },
"properties": {
"message_comment_id": { "type": "integer" },
"created_at": { "type": "date" }
}
}
}
}
インデックステンプレートの登録は、Elasticsearchをローカルで起動した状態では
下記のコマンドを実行して登録します。
$ curl -XPUT 'http://localhost:9200/_template/message_index'?pretty -d @index_template.json
{
"acknowledged" : true
}
検索してみる
まずはドキュメントの登録です。
{"index": {"_index": "message_index", "_type": "messages", "_id": "1", "_routing": "1"}}
{"message_id": 1, "message": "これは削除された投稿1", "created_at": "2014-12-16T00:01:02+09:00"}
{"index": {"_index": "message_index", "_type": "deleted_messages", "_id": "1", "_parent": "1", "_routing": "1"}}
{"message_id": 1, "created_at": "2014-12-16T00:01:04+09:00"}
{"index": {"_index": "message_index", "_type": "messages", "_id": "2", "_routing": "2"}}
{"message_id": 2, "message": "これは削除された投稿2", "created_at": "2014-12-16T00:05:02+09:00"}
{"index": {"_index": "message_index", "_type": "deleted_messages", "_id": "2", "_parent": "2", "_routing": "2"}}
{"message_id": 2, "created_at": "2014-12-16T00:05:05+09:00"}
{"index": {"_index": "message_index", "_type": "message_comments", "_id": "21", "_parent": "2", "_routing": "2"}}
{"message_comment_id": 21, "message_id": 2, "message": "これは削除されていないコメント21", "created_at": "2014-12-16T00:06:10+09:00"}
{"index": {"_index": "message_index", "_type": "messages", "_id": "3", "_routing": "3"}}
{"message_id": 3, "message": "これはマッチしない投稿3", "created_at": "2014-12-16T00:02:03+09:00"}
{"index": {"_index": "message_index", "_type": "message_comments", "_id": "31", "_parent": "3", "_routing": "3"}}
{"message_comment_id": 31, "message_id": 3, "message": "これはマッチしないコメント31", "created_at": "2014-12-16T00:02:05+09:00"}
{"index": {"_index": "message_index", "_type": "message_comments", "_id": "32", "_parent": "3", "_routing": "3"}}
{"message_comment_id": 32, "message_id": 3, "message": "これは削除されたコメント32", "created_at": "2014-12-16T00:02:08+09:00"}
{"index": {"_index": "message_index", "_type": "deleted_message_comments", "_id": "32", "_parent": "32", "_routing": "3"}}
{"message_comment_id": 32, "created_at": "2014-12-16T00:02:09+09:00"}
{"index": {"_index": "message_index", "_type": "messages", "_id": "4", "_routing": "4"}}
{"message_id": 4, "message": "これは削除されていない投稿4", "created_at": "2014-12-16T00:03:29+09:00"}
{"index": {"_index": "message_index", "_type": "messages", "_id": "5", "_routing": "5"}}
{"message_id": 5, "message": "これはマッチしない投稿5", "created_at": "2014-12-16T00:03:31+09:00"}
{"index": {"_index": "message_index", "_type": "message_comments", "_id": "51", "_parent": "5", "_routing": "5"}}
{"message_comment_id": 51, "message_id": 5, "message": "これは削除されていないコメント51", "created_at": "2014-12-16T00:03:40+09:00"}
下記のコマンドを実行してドキュメントを一括登録します。
$ curl -XPOST 'http://localhost:9200/_bulk?pretty' --data-binary @index_data.json
{
"took" : 1602,
"errors" : false,
"items" : [ {
"index" : {
"_index" : "message_index",
"_type" : "messages",
"_id" : "1",
"_version" : 1,
"status" : 201
}
},
(中略)
{
"index" : {
"_index" : "message_index",
"_type" : "message_comments",
"_id" : "51",
"_version" : 1,
"status" : 201
}
} ]
}
では、検索してみましょう。
「削除」の単語を含むドキュメントを検索するクエリーは下記のようになります。
※時系列のカラムでのソートしかしていないため、スコアを気にしないクエリーになっています。
これは Elasticsearch の Java API で実際に実行されるクエリーを少々加工したものです。
意味のない記述(bool queryとか)があるように見えますが、
それは複数キーワードや除外キーワードを指定して検索するときに意味があるものです。
{
"query" : {
"filtered" : {
"query" : {
"bool" : {
"should" : [ {
"bool" : {
"must" : {
"match" : {
"message" : {
"query" : "削除",
"type" : "phrase"
}
}
}
}
}, {
"has_child" : {
"query" : {
"filtered" : {
"query" : {
"bool" : {
"must" : {
"match" : {
"message" : {
"query" : "削除",
"type" : "phrase"
}
}
}
}
},
"filter" : {
"not" : {
"filter" : {
"has_child" : {
"filter" : {
"match_all" : { }
},
"child_type" : "deleted_message_comments"
}
}
}
}
}
},
"child_type" : "message_comments"
}
} ]
}
},
"filter" : {
"bool" : {
"must_not" : {
"has_child" : {
"filter" : {
"match_all" : { }
},
"child_type" : "deleted_messages"
}
}
}
}
}
},
"sort" : [ {
"created_at" : {
"order" : "desc"
}
}, {
"message_id" : {
"order" : "desc"
}
} ]
}
下記のコマンドを実行してドキュメントを検索します。
$ curl -XGET 'http://localhost:9200/message_index/messages/_search?pretty' --data-binary @index_query.json
{
"took" : 136,
"timed_out" : false,
"_shards" : {
"total" : 10,
"successful" : 10,
"failed" : 0
},
"hits" : {
"total" : 2,
"max_score" : null,
"hits" : [ {
"_index" : "message_index",
"_type" : "messages",
"_id" : "5",
"_score" : null,
"sort" : [ 1418655811000, 5 ]
}, {
"_index" : "message_index",
"_type" : "messages",
"_id" : "4",
"_score" : null,
"sort" : [ 1418655809000, 4 ]
} ]
}
}
削除フラグドキュメントを持たず、投稿かコメントに「削除」を含む投稿のIDが2件返ってきました!
おわりに
Elasticsearch の parent-child relationship は親-子-孫と扱えます、という紹介でした。
明日の記事は @chimerast さんです。お楽しみに。