せっかく作った仕組みですが、使わない方向に進んでいるので供養として投稿。
皆さんはLinuxのユーザ管理はどのように実施されていますでしょうか?
一台一台、温かみのある手作業による管理も良いのですが、流石に令和のこの時代、何らかの方法で一元管理を行いたいものです。
EC2 Instance Connect、Systems Manager Session Manager、Teleportなどなど、Linuxへログインするだけであれば、昔から比べると色々な方法が用意されていますが、所属グループの管理やsudo権限の管理なども考え出すと、やはりOpenLDAP + SSSDによる管理がノウハウも豊富で安定しています。
本記事では、Linuxユーザ管理のためのOpenLDAPをAWS Fargate上で稼働させるために私が考えた方法を紹介します。(大枠での挙動に絞って記載し、細かなところは端折っています)
OpenLDAPはコンテナとマッチしない?
いきなりOpenLDAPをコンテナ環境で稼働させてハイ終わりではなく、コンテナ稼働に最適化されたOpenLDAPとはどんなものか、について考えてみます。
一般的に、コンテナ上で稼働させるアプリケーションはImmutableで状態を持たないことが望ましいです。
今回のOpenLDAPであれば、ユーザ情報のような、変更可能性があるようなデータをコンテナ内には持たないような仕組みにしたいです。
それでは、状態を持つデータをNFSのようにコンテナ外部に置いておけばOKでしょうか?
困ったことにOpenLDAPのバックエンドとしてよく使われているbdbはNFSのような共有ストレージで使われることは想定されていません。(mdbはどうなんだろう…?)
Can OpenLDAP use NFS to store back-bdb/hdb data?
単一のコンテナしか建てられず、ストレージもホストのものを使う、となると果たしてそれはコンテナ化する必要があるのか? という疑問が湧いてきます。
認証はしたいけど認証システムの管理はしたくない
タイトルはOpenLDAPをコンテナで動かしてみたいと思った方へのリーチできるように設定しましたが、実はコンテナでの運用は結果としてそれが最適解となっただけで、最初からOpenLDAPをコンテナで運用する! といったことを目指したわけではありませんでした。
まず、第一にあったのが「認証サーバの運用をしたくない」です。
認証一元管理の仕組み自体はすごく重要ですが、これ自体は企業としての競争優位性を生み出すものではありません。
手間を省くための一元管理の仕組みなのに、その仕組みの管理に手間を取られるのは本末転倒です。
(そして、往々にしてこういったシステムは原因不明のトラブルが起こりがちです……)
そこで「認証システム管理の手間を減らすため、OpenLDAPをDisposable/Immutableな環境として運用できないか?」と考えた結果、
「保持するユーザデータを外部で管理して、変更が入るたびに都度コンテナ化してデプロイするのはどうだろう?」と思いつき、その仕組みを設計・構築していきました。
処理の流れ
実際にどのような仕組みでOpenLDAPをImmutableなコンテナで稼働させることにしたのか、全体の流れを図にしてみました。
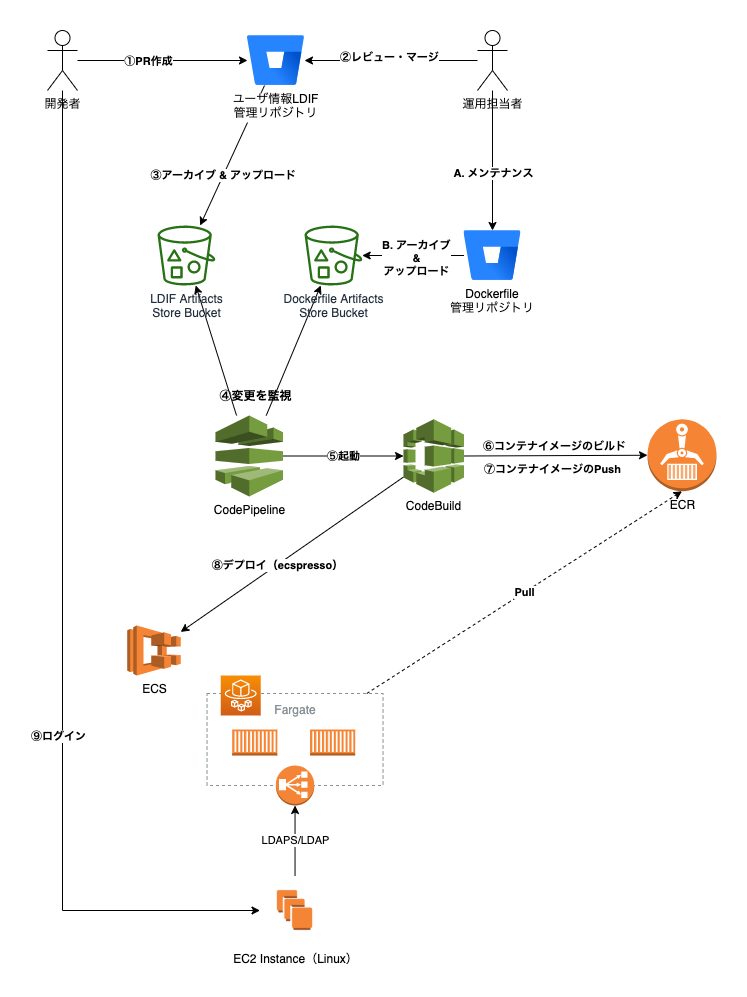
それぞれをステップごとに説明します。
ユーザ情報の管理・変更
ここが従来のOpenLDAP運用と大きく違うポイントです。
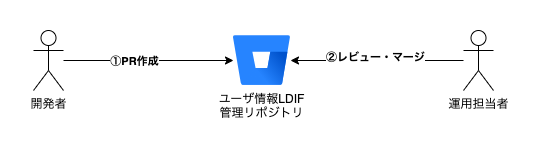
ユーザ情報はLDIFファイルをGit(BitBucket)リポジトリで管理しています。
Linuxへのパスワード認証は無効で、公開鍵認証のみでしたので、ユーザ名・UID/GID・公開鍵などは社内限定公開としています。
具体的に管理される情報(LDIFファイル)のサンプルは下記の通りです。
dn: cn=hoge.hoge,ou=Users,dc=mydomain,dc=local
objectClass: inetOrgPerson
objectClass: posixAccount
objectClass: ldapPublicKey
uid: hoge.hoge
uidNumber: 10010
gidNumber: 10000
homeDirectory: /home/hoge.hoge
loginShell: /bin/bash
mail: hogehoge@hamee.co.jp
sn: hoge
givenName: hoge
gecos: hoge.hoge
sshPublicKey: ssh-rsa *****************************************************
dn: cn=foo.bar,ou=Users,dc=mydomain,dc=local
objectClass: inetOrgPerson
objectClass: posixAccount
objectClass: ldapPublicKey
uid: foo.bar
uidNumber: 10013
gidNumber: 10000
homeDirectory: /home/foo.bar
loginShell: /bin/bash
mail: foobar@hamee.co.jp
sn: foo
givenName: bar
gecos: foo bar
sshPublicKey: ********************************************
sshPublicKey: ********************************************
dn: cn=hamee,ou=Groups,dc=mydomain,dc=local
objectClass: posixGroup
objectClass: top
gidNumber: 10000
cn: developer
dn: cn=sre,ou=Groups,dc=mydomain,dc=local
objectClass: posixGroup
objectClass: top
gidNumber: 10010
cn: sre
memberUid: hoge.hoge
memberUid: foo.bar
dn: cn=sre,ou=SUDOers,dc=mydomain,dc=local
objectClass: sudoRole
objectClass: top
cn: sre
sudoHost: ALL
sudoCommand: ALL
sudoOption: !authenticate
sudoUser: %sre
パスワードなどの本人以外が閲覧可能であるとマズいような情報は含まれていません。
この情報はGitで管理されているため、ユーザがPCのリプレースなどで公開鍵が変更された場合やメールアドレスの変更など、登録上の変更については、自分で変更のためのプルリクを作成することが可能です。
所属グループの変更やsudo権限の申請なども、プルリクに申請理由を書く、または別途ワークフローシステムと連携して自動的に作成もできそうです。
作成されたプルリクは承認者によるレビューを経て、適切な権限を持った運用担当者によってマージされます。
OpenLDAPコンテナイメージの生成
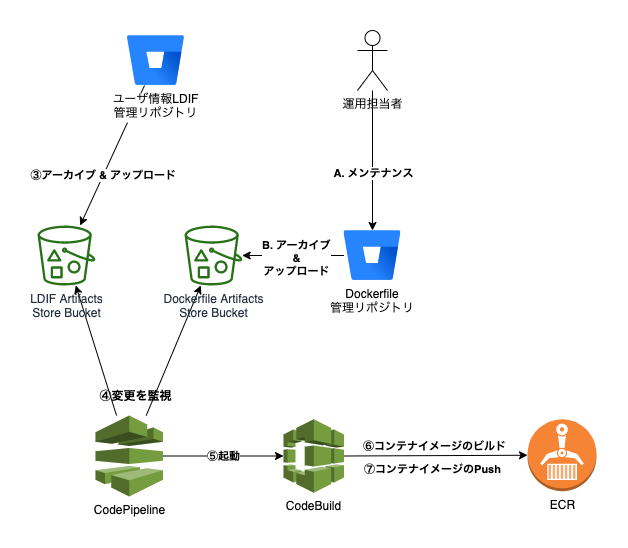
運用担当者によるBitBucketでのマージをトリガーにし、BitBucket Pipelineが起動。
LDIFファイルを含むArtifactsをS3にアップロードされS3内アイテムのバージョン変更をトリガーにCodePipeline/CodeBuildが起動します。
CodeBuildでは更新されたユーザ情報を含むLDIFファイルを元に、OpneLDAPコンテナイメージを作成しECRにプッシュします。
その後、新たなコンテナイメージはFargateで構成されたECSにデプロイされます。
一見、CodePipelineを使用しなくてもBitBucket Pipelineだけですべての処理を完結することができそうです。
なぜCodePipeline/CodeBuildを使用したのか? について説明します。
この仕組みでは、ユーザ情報(LDIFファイル)を管理するリポジトリとコンテナイメージを作成するためのDockerfileを管理するリポジトリを分けてあります。
DockerfileのリポジトリにはOpenLDAPの設定ファイルが含まれており、これらのファイルを一般ユーザが閲覧・操作できる場所に置くのは好ましくなかったため、運用者のみにアクセス権が付与されたリポジトリで管理しています。
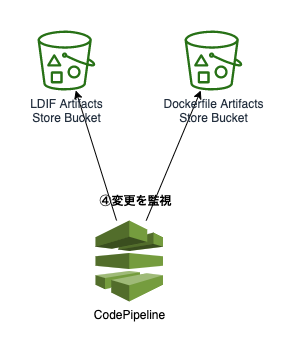
CodePipeline/CodeBuildには複数のソースをトリガにしてビルドを走らせる機能があり、複数のソースのうちどちらかが更新されたらビルドを開始する、という設定が可能です。
AWS CodePipeline を CodeBuild の複数の入力ソースおよび出力アーティファクトと統合するサンプル
ここでは、ユーザ情報が変更された場合・Dockerfileが更新された場合、どちらがトリガーでもコンテナイメージの再作成・デプロイが動くように設定を行いました。
Dockerfileはこのような内容で、 /ldif ディレクトリに必要なLDIFファイルが配置されている想定で初期化を行っています。
FROM alpine:latest
EXPOSE 636
RUN apk --update --no-cache add openldap-back-mdb openldap openldap-clients openldap-passwd-pbkdf2
RUN mkdir -p /run/openldap && mkdir -p /var/lib/openldap/run && mkdir -p /etc/openldap/slapd.d
RUN rm -f /etc/openldap/slapd.conf
COPY ldif /ldif
COPY slapd.ldif /etc/openldap/slapd.ldif
COPY --from=cert-builder /certs /certs
RUN slapadd -n0 -F /etc/openldap/slapd.d -l /etc/openldap/slapd.ldif
RUN slapd -h ldapi:/// \
&& sleep 3 \
&& ldapadd -Y EXTERNAL -H ldapi:/// -f /ldif/init/10-domain.ldif \
&& ldapadd -Y EXTERNAL -H ldapi:/// -f /ldif/init/20-ou.ldif \
&& ldapadd -Y EXTERNAL -H ldapi:/// -f /ldif/groups.ldif \
&& ldapadd -Y EXTERNAL -H ldapi:/// -f /ldif/users.ldif -c || true \
&& ldapadd -Y EXTERNAL -H ldapi:/// -f /ldif/sudoers.ldif \
&& kill -SIGTERM $(pidof slapd)
WORKDIR /etc/openldap
CMD ["slapd", "-h", "ldap:/// ldaps:///", "-d", "256"]
余談ですがこのDockerfileを書いているときに、AlpineLinuxのAportsに登録されているOpenLDAPで、slapd.ldifから初期化する処理がうまくいかず、よく見てみると不要な改行が入っていることに気づき修正のプルリクを作成しました。マージされたときはほんのり嬉しかったです![]()
https://github.com/alpinelinux/aports/pull/10225
CodeBuildに渡す buildspec.yml はこんな感じ。
version: 0.2
phases:
install:
runtime-versions:
docker: 18
build:
commands:
- echo "### mix up each source"
- echo "${CODEBUILD_SRC_DIR_SOURCE_LDIF}"
- cp -f ${CODEBUILD_SRC_DIR_SOURCE_LDIF}/ldif/*.ldif ${CODEBUILD_SRC_DIR}/ldif/
- echo "### build image"
- docker build -t myopenldap:latest ${CODEBUILD_SRC_DIR}
- echo "### generate tag"
- REPO=************.dkr.ecr.ap-northeast-1.amazonaws.com/myopenldap
- LDIF_COMMIT_HASH=$(cat ${CODEBUILD_SRC_DIR_SOURCE_LDIF}/commit-id.txt | cut -c1-7)
- DOCKERFILE_COMMIT_HASH=$(cat ${CODEBUILD_SRC_DIR}/commit-id.txt| cut -c1-7)
- TAG=${LDIF_COMMIT_HASH}_${DOCKERFILE_COMMIT_HASH}
- docker tag myopenldap:latest ${REPO}:${TAG}
- echo "### push"
- $(aws ecr get-login --no-include-email --region=ap-northeast-1)
- docker push ${REPO}:${TAG}
# この後はデプロイのためのstepが続くが省略
${CODEBUILD_SRC_DIR_SOURCE_LDIF}はLDIF管理のリポジトリからのArtifactsが保存されたディレクトリで、${CODEBUILD_SRC_DIR}はDockerfile管理のリポジトリのものとなります。
つまり、docker buildより前の行でDockerfileリポジトリ内の/ldifディレクトリにLDIFリポジトリのLDIFファイルをコピーしています。
各リポジトリのbitbucket-pipelines.ymlには
- echo ${BITBUCKET_COMMIT} > commit-id.txt
というステップが定義されていて、コミットIDをcommit-id.txtというファイルに吐き出してArtifactsに含めるようにしています。
このファイルを元にしてコンテナイメージのタグ名コミットハッシュをつなぎ合わせたユニークな値に設定しています。
Fargateへのデプロイ
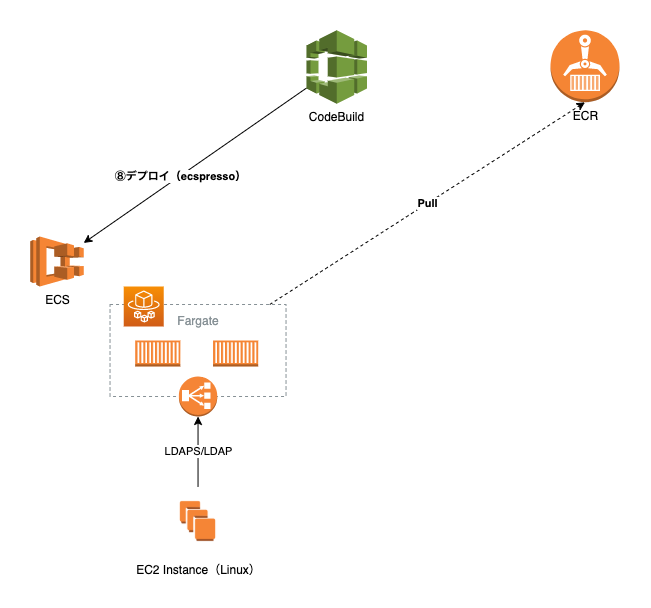
デプロイはCodeDeployを使用せず、CodeBuild内でecspressoを呼び出しています。
デプロイされたコンテナはNLBのターゲットとして起動し、ヘルスチェックを経てLinuxからのLDAPS/LDAPアクセスを受け取り始めます。
コンテナは別々のAZで2つ以上起動され、一方が何らかの障害で応答不能になったとしても片肺での処理が可能です。ECS Serviceの設定で2つ以上のコンテナが起動している状態を維持しようとしますので、ホスト障害や何らかの原因でコンテナのヘルスチェックに失敗した場合は、自動的にコンテナが入れ替えられます。
通常のOpenLDAP運用であれば可用性担保のためレプリケーションの設定が必要となりますが、この仕組みの場合、2つのOpenLDAPコンテナは同じデータを保持し、中身が書き換わることがないためそのような設定は不要となります。
メリット・デメリット
この仕組みによって、得られるメリット・デメリットは下記の通りです。
サーバの管理が不要
OpenLDAPコンテナはFargate上で稼働しているため、ホストのハードウェア・OSのメンテナンスは不要です。
運用担当者が気にするべき事項はベースイメージのOSバージョン、OpenLDAPのバージョンのみとなります。
OpenLDAPの基本的な機能しか使用していないので、クリティカルなセキュリティパッチ以外はほぼメンテナンス不要でしょう。
ユーザ情報化の管理が容易
一般的なOpenLDAPの管理では、ユーザの登録情報(公開鍵など)が変更される場合は、運用担当者が申請を元に変更したり、ユーザ自身に変更権限を付与して変更のための操作マニュアルを要する必要がありました。
この仕組みであれば、ユーザは使い慣れたGitのプルリクという形で登録情報の変更申請が行なえます。
また、運用担当者側のレビュー・承認もプルリクベースで行うことができ、さらにその証跡はBitBucket上に記録されます。
データの変更反映に時間がかかる
BitBucket上で管理されたユーザ情報が書き換えられた際、コンテナイメージのビルド・デプロイという流れを経て変更が反映されるため、通常のOpenLDAPサーバ運用の場合と比べて、変更反映に時間がかかります。
これについては、弊社の場合はユーザ数がそこまで多くはないことと、データの書き換え頻度が少ないため大きな問題とはなりませんでした。
緊急時のロックダウンについては、AWSのSSM RunCommandでLinuxの設定を変更することで対応する想定でした。(nsswitchの設定でローカルの/etc/passwdを優先するようにしてあったため、そこにロック済みの同名ユーザを追加することで緊急ロックが可能)
また、同様の理由で大量のユーザ情報を格納する大規模なLDAPサーバの稼働方法としては不向きと言えます。
ユーザ情報は公開可能な情報のみに限る
BitBucketでユーザ情報を管理するため、パスワードのような、社内であっても非公開の情報を保持することができません。
基本的にはLinux認証には公開鍵認証のみを想定していたので、こちらも特に運用上困ることはありませんでした。
新しい認証方式へ
ここでは記載しませんでしたが、MySQLのユーザ認証にもこの仕組みを拡張すべく、API Gateway + Lambda + DynamoDBで別途パスワードを管理するRESTエンドポイントを作成、DynamoDB Streamでパスワード変更をトリガにLDIFをArtifactsとして出力、CodePipelineのマルチソースビルドのソースの1つとして組み込んでVaultを使って連携、みたいなことも行っていました。
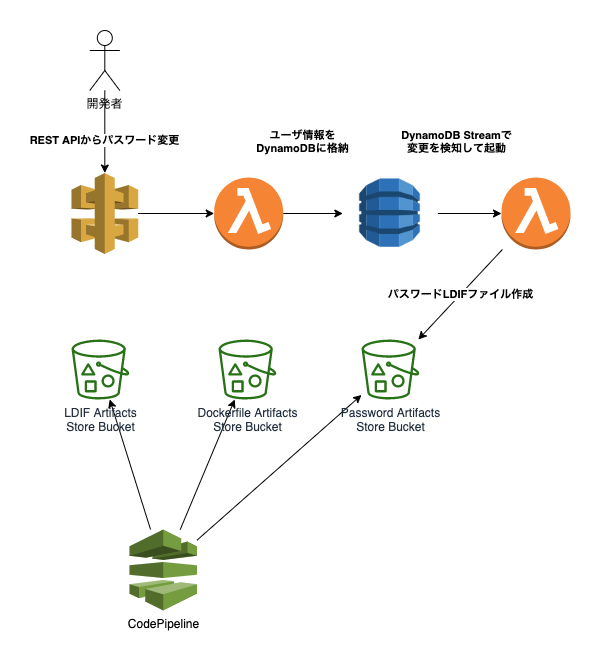
しかしながら、作りかけの状態で私自身に別の大きなタスクが降ってきたこと、
パスワードの取り扱いのためリソースを拡張した結果、把握しなければいけないシステムの範囲が大きくなってしまったこと、
OpenLDAPやSSSDが古い仕組みになってきているのか、Web上でも参考となるページが少なくなっており、今後新しく参加してくれるエンジニアにとって優しくない技術要素となる懸念、
一番大きな要因として、アプリケーションのコンテナ化とログの取り扱い方法の変化というモダンなアーキテクチャへの切り替えにより、EC2へのログイン制御にユーザグループやsudo権限などの細かな管理が不要となったこと、
これら諸々の事情が重なったところに、同僚がAWS SSOとSSM Session ManagerやVaultを組み合わせた、更に面白く便利な仕組みを作ってくれたため、今回紹介した仕組みはそのままお蔵入りとすることにしました。
結果として弊社では本番稼働前にお蔵入りとなってしまいましたが、OpenLDAPをDisposable/Immutableなコンテナで扱うためユーザ情報をGit上で管理する、というアプローチは我ながら面白いなと思っており、この記事が同じような問題で悩んでおられる方への一助となれば幸いです。