はじめに
日本語テキストを画像から抽出したいですが、AWSの既存OCRサービスであるAmazon Textract、その他Recognitionでは日本語のテキスト抽出に対応してなそうでした。
そこで代替手段として、AWSの生成AIサービス「Amazon Bedrock」のマルチモーダル機能を使用することで、画像内の日本語テキストを認識・抽出できるのではないかと考えてみました。
本記事では実際にリソースを構築し、画像から日本語テキストを抽出できるか検証してみます。
やりたいこと
画像から日本語テキストを認識・抽出する
画像
本記事ではテキストを抽出する対象の画像は次のものを使用します。

ゴール
- S3バケットにアップロードした画像(PDF、png、jpeg、Webp)からテキストを抽出できることを確認する
作成する構成
S3に画像をアップロードしておきます。
LambdaではS3から画像を取得後BedrockのAPIをコールし、画像からテキストを抽出します。

環境
- Python:3.13
- Bedrockで使用するモデル:claude 3.5 sonnet v2
- 利用するAWSのリージョン:東京
Bedrockでテキスト抽出(コンソール操作)
まずはマネジメントコンソールからBedrockを使用し、画像から日本語テキスト認識、抽出できるか試してみます。
claude 3.5 sonnet のモデルが使用可能になっていることを想定しています。
claude 3.5 sonnetには以下のシステムプロンプトを設定します。
画像からテキストを抽出してください。必ず以下の形式で出力してください。
・チーム名:
・費用:
・費用の内訳:
・支払日時:
・用途(チェックが入っているもの):
チェックボックスがある場合は、チェックが入っている項目のみを「用途」欄に記載してください。
すべての情報を正確に抽出し、見つからない項目がある場合は「情報なし」と記載してください。
コンソールからBedrockのChatモードを選択して画像からテキストを抽出してみます。
PDF画像
PDF画像をアップロードして実行を押下します。

下記が出力時の画面です。
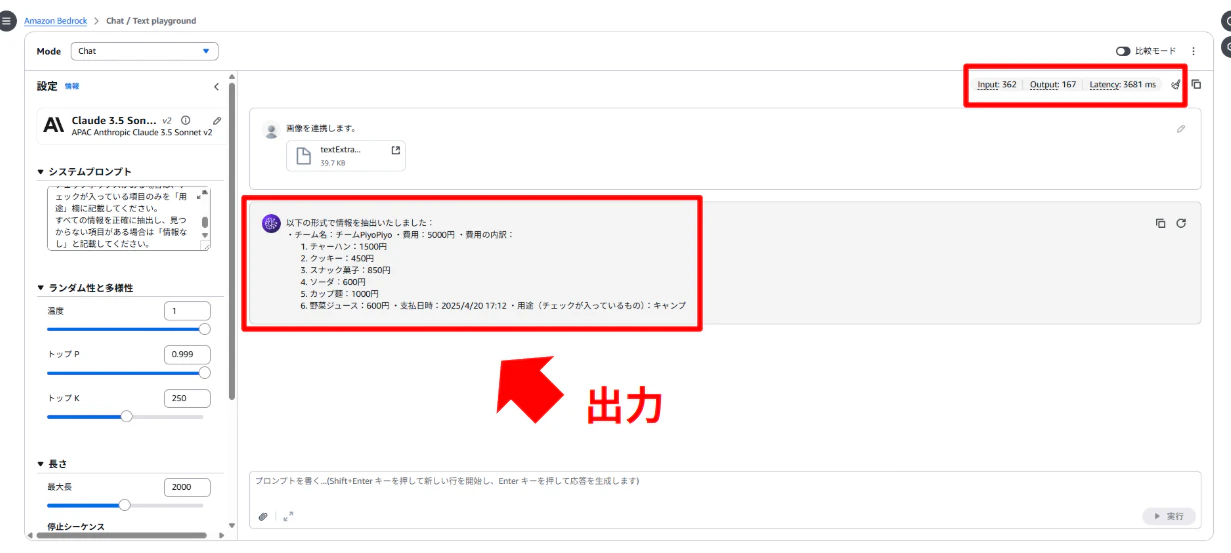
改行ができてない箇所もありますが、それ以外はフォーマット通りPDF画像からテキストを抽出できています。
要求された形式で情報を抽出しました:
・チーム名:チームPiyoPiyo ・費用:5000円 ・費用の内訳:
チャーハン:1500円
クッキー:450円
スナック菓子:850円
ソーダ:600円
カップ麺:1000円
野菜ジュース:600円 ・支払日時:2025/4/20 17:12 ・用途(チェックが入っているもの):キャンプ
- 入力時のトークン数(Input tokens):362
- 出力時のトークン数(Output tokens):162
- Latency:3681 ms
png、jpeg、Webpも試してみましたが、結果としてはいずれも画像からテキストを抽出できていました。
それぞれ以下の通りです。
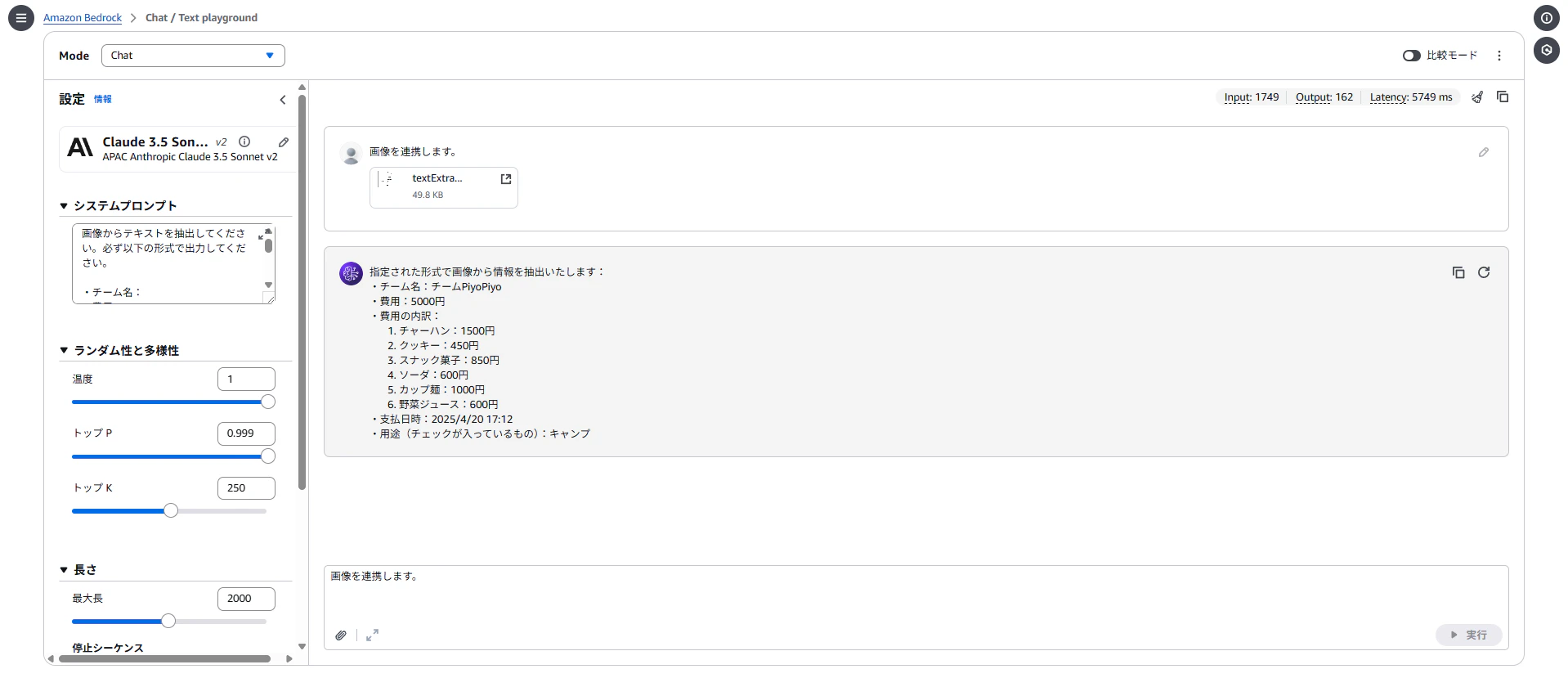
png画像
details
指定された形式で画像から情報を抽出いたします:
・チーム名:チームPiyoPiyo
・費用:5000円
・費用の内訳:
チャーハン:1500円
クッキー:450円
スナック菓子:850円
ソーダ:600円
カップ麺:1000円
野菜ジュース:600円
・支払日時:2025/4/20 17:12
・用途(チェックが入っているもの):キャンプ
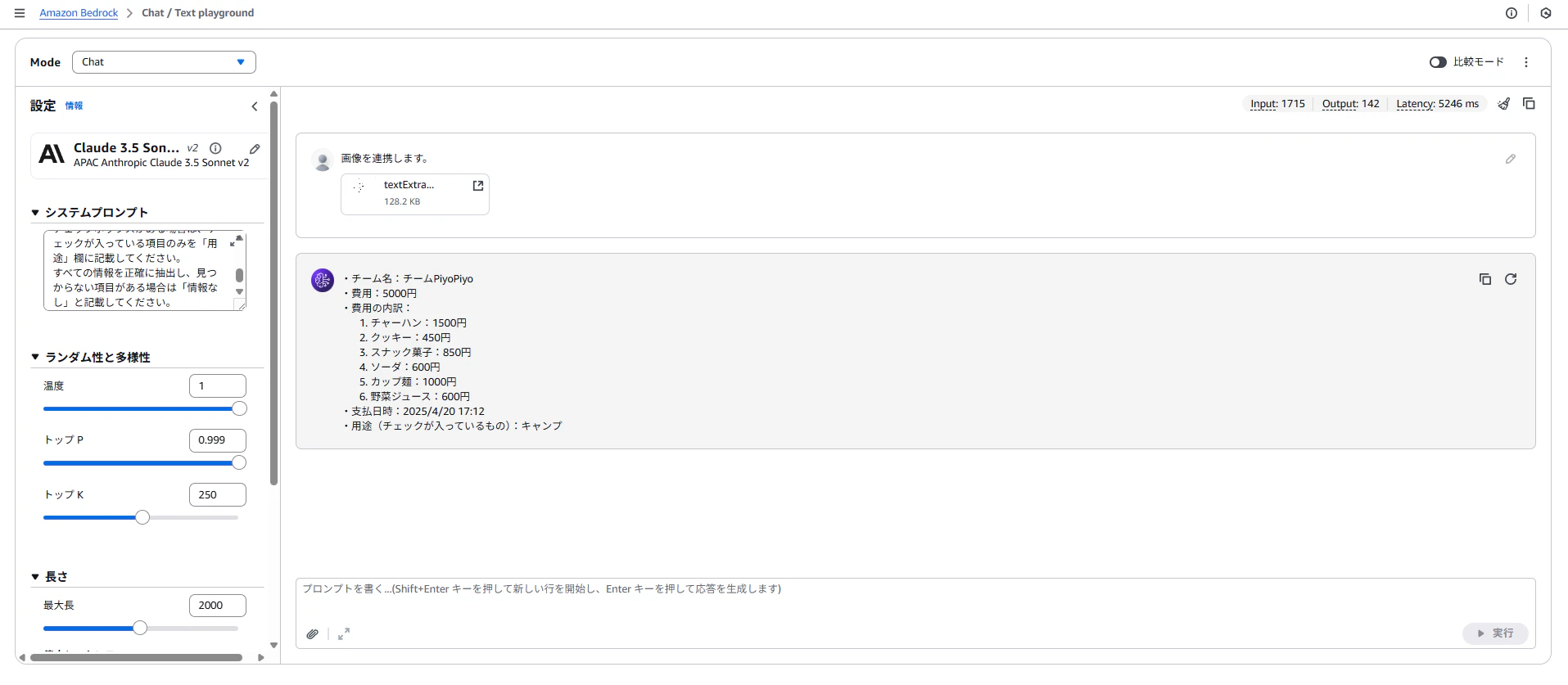
jpeg画像
details
・チーム名:チームPiyoPiyo
・費用:5000円
・費用の内訳:
チャーハン:1500円
クッキー:450円
スナック菓子:850円
ソーダ:600円
カップ麺:1000円
野菜ジュース:600円
・支払日時:2025/4/20 17:12
・用途(チェックが入っているもの):キャンプ
WebP画像
details
ご依頼の形式に沿って情報を抽出いたします:
・チーム名:チームPiyoPiyo
・費用:5000円
・費用の内訳:
チャーハン:1500円
クッキー:450円
スナック菓子:850円
ソーダ:600円
カップ麺:1000円
野菜ジュース:600円
・支払日時:2025/4/20 17:12
・用途(チェックが入っているもの):キャンプ

Lambda → Bedrockをコールしテキスト抽出
以下の構成を作成していきます。
S3バケット
4種類(PDF、png、jpeg、Webp)の画像をS3にアップロードします。

Lambda
今回は検証なのでLambdaのロールには、以下2つのポリシーを当てておきます。
- AmazonBedrockFullAccess
- AmazonS3FullAccess
スクリプトは次の通りです。
import json
import logging
from invoke_bedrock import process_files
from result_formatter import format_results, create_performance_summary
# ロガーの設定
logger = logging.getLogger()
logger.setLevel(logging.INFO)
def lambda_handler(event, context):
# S3バケット名とオブジェクトキーの設定
bucket = "extract-image-used-bedrock"
file_keys = [
"textExtractionSheet.jpeg",
"textExtractionSheet.pdf",
"textExtractionSheet.png",
"textExtractionSheet.webp"
]
# システムプロンプト
prompt = """画像からテキストを抽出してください。必ず以下の形式で出力してください。
・チーム名:
・費用:
・費用の内訳:
・支払日時:
・用途(チェックが入っているもの):
チェックボックスがある場合は、チェックが入っている項目のみを「用途」欄に記載してください。
すべての情報を正確に抽出し、見つからない項目がある場合は「情報なし」と記載してください。"""
# ファイル処理
results, metrics = process_files(file_keys, bucket, prompt)
# 結果フォーマット
formatted_results = format_results(results, metrics, file_keys)
# CWに実行結果を出力
logger.info("実行結果:\n%s", json.dumps(formatted_results, ensure_ascii=False, indent=2))
performance_summary = create_performance_summary(formatted_results, metrics)
logger.info("処理概要: %s", json.dumps(performance_summary, ensure_ascii=False))
return {
'statusCode': 200,
'headers': {
'Content-Type': 'application/json'
},
'body': json.dumps(formatted_results, ensure_ascii=False, indent=2)
}
上記メインのスクリプトから呼んでるスクリプトは次の2つです。
invoke_bedrock.py
import boto3
import time
import logging
logger = logging.getLogger()
# S3からファイルを取得し、Bedrockで処理する
def process_files(file_keys, bucket, prompt):
bedrock_runtime = boto3.client('bedrock-runtime')
s3 = boto3.client('s3')
results = {}
metrics = {}
for file_key in file_keys:
try:
start_time = time.time()
# S3からファイルを取得
response = s3.get_object(Bucket=bucket, Key=file_key)
file_content = response['Body'].read()
# ファイル形式を取得
file_extension = file_key.split('.')[-1].lower()
# メッセージの構築
messages = [
{
"role": "user",
"content": []
}
]
# ファイルタイプに応じてコンテンツを追加
if file_extension in ['jpeg', 'jpg', 'png', 'webp']:
messages[0]["content"].append({
"image": {
"format": file_extension,
"source": {
"bytes": file_content
}
}
})
elif file_extension == 'pdf':
messages[0]["content"].append({
"document": {
"name": "DocumentFile",
"format": "pdf",
"source": {
"bytes": file_content
}
}
})
# プロンプトを追加
messages[0]["content"].append({"text": prompt})
# Bedrockの呼び出し
api_start_time = time.time()
response = bedrock_runtime.converse(
modelId="anthropic.claude-3-5-sonnet-20240620-v1:0",
messages=messages
)
api_end_time = time.time()
# レスポンスを処理
assistant_message = response["output"]["message"]["content"][0]["text"]
end_time = time.time()
# 処理時間の計測
total_time = end_time - start_time
api_time = api_end_time - api_start_time
# 結果の保存
results[file_key] = {
"extracted_text": assistant_message,
"status": "成功"
}
# メトリクスの保存
metrics[file_key] = {
"total_time_seconds": round(total_time, 2),
"api_time_seconds": round(api_time, 2),
"file_type": file_extension
}
logger.info(f"処理完了: {file_key} (API: {round(api_time, 2)}秒, 合計: {round(total_time, 2)}秒)")
except Exception as e:
error_message = str(e)
logger.error(f"エラー発生 ({file_key}): {error_message}")
results[file_key] = {
"extracted_text": f"エラー: {error_message}",
"status": "失敗"
}
metrics[file_key] = {
"error": error_message,
"file_type": file_key.split('.')[-1].lower()
}
return results, metrics
result_formatter.py
import json
import datetime
# 実行結果をフォーマット
def format_results(results, metrics, file_keys):
# 結果を整形
formatted_results = {
"timestamp": datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
"summary": {
"total_files": len(file_keys),
"successful": sum(1 for k in results if results[k]["status"] == "成功"),
"failed": sum(1 for k in results if results[k]["status"] == "失敗")
},
"performance": {
file_key: {
"file_type": metrics[file_key].get("file_type", "不明"),
"processing_time": f"{metrics[file_key].get('total_time_seconds', 'N/A')}秒",
"api_time": f"{metrics[file_key].get('api_time_seconds', 'N/A')}秒" if "api_time_seconds" in metrics[file_key] else "N/A"
} for file_key in file_keys
},
"extraction_results": {
file_key: results[file_key]["extracted_text"] if results[file_key]["status"] == "成功" else f"エラー: {results[file_key]['extracted_text']}"
for file_key in file_keys
}
}
return formatted_results
# パフォーマンス概要を作成
def create_performance_summary(formatted_results, metrics):
performance_summary = {
"timestamp": formatted_results["timestamp"],
"summary": formatted_results["summary"],
"average_processing_time": f"{sum(metrics[k].get('total_time_seconds', 0) for k in metrics) / len(metrics):.2f}秒"
}
return performance_summary
動作の確認
Lambdaをテスト実行させるとステータス200で成功しました。
{
"statusCode": 200,
"headers": {
"Content-Type": "application/json"
},
"body": "{\n \"timestamp\": \"2025-04-26 13:47:10\",\n \"summary\": {\n \"total_files\": 4,\n \"successful\": 4,\n \"failed\": 0\n },\n \"performance\": {\n \"textExtractionSheet.jpeg\": {\n \"file_type\": \"jpeg\",\n \"processing_time\": \"5.08秒\",\n \"api_time\": \"4.6秒\"\n },\n \"textExtractionSheet.pdf\": {\n \"file_type\": \"pdf\",\n \"processing_time\": \"2.44秒\",\n \"api_time\": \"2.37秒\"\n },\n \"textExtractionSheet.png\": {\n \"file_type\": \"png\",\n \"processing_time\": \"4.37秒\",\n \"api_time\": \"4.32秒\"\n },\n \"textExtractionSheet.webp\": {\n \"file_type\": \"webp\",\n \"processing_time\": \"5.03秒\",\n \"api_time\": \"4.98秒\"\n }\n },\n \"extraction_results\": {\n \"textExtractionSheet.jpeg\": \"以下の形式で画像から抽出したテキスト情報を記載します:\\n\\n・チーム名:チームPiyoPiyo\\n・費用:5000円\\n・費用の内訳:\\n1 チャーハン:1500円\\n2 クッキー:450円\\n3 スナック菓子:850円\\n4 ソーダ:600円\\n5 カップ麺:1000円\\n6 野菜ジュース:600円\\n・支払日時:2025/4/20 17:12\\n・用途(チェックが入っているもの):キャンプ\",\n \"textExtractionSheet.pdf\": \"・チーム名:チームPiyoPiyo\\n\\n・費用:5000円\\n\\n・費用の内訳:\\n1. チャーハン:1500円\\n2. クッキー:450円\\n3. スナック菓子:850円\\n4. ソーダ:600円\\n5. カップ麺:1000円\\n6. 野菜ジュース:600円\\n\\n・支払日時:2025/4/20 17:12\\n\\n・用途(チェックが入っているもの):キャンプ\",\n \"textExtractionSheet.png\": \"以下の形式で画像から抽出したテキスト情報を記載します:\\n\\n・チーム名:チームPiyoPiyo\\n・費用:5000円\\n・費用の内訳:\\n 1 チャーハン:1500円\\n 2 クッキー:450円\\n 3 スナック菓子:850円\\n 4 ソーダ:600円\\n 5 カップ麺:1000円\\n 6 野菜ジュース:600円\\n・支払日時:2025/4/20 17:12\\n・用途(チェックが入っているもの):キャンプ\",\n \"textExtractionSheet.webp\": \"以下の形式で画像から抽出したテキスト情報をお伝えします:\\n\\n・チーム名:チームPiyoPiyo\\n・費用:5000円\\n・費用の内訳:\\n1 チャーハン:1500円\\n2 クッキー:450円\\n3 スナック菓子:850円\\n4 ソーダ:600円\\n5 カップ麺:1000円\\n6 野菜ジュース:600円\\n・支払日時:2025/4/20 17:12\\n・用途(チェックが入っているもの):キャンプ\"\n }\n}"
}
CLoudwatchのログから確認
結果としては4つの形式(PDF、png、jpeg、Webp)いずれの場合であっても、画像に記載していたテキストを抽出できました。
"extraction_results": {
"textExtractionSheet.jpeg": "以下の形式で画像から抽出したテキスト情報を記載します:\n\n・チーム名:チームPiyoPiyo\n・費用:5000円\n・費用の内訳:\n1 チャーハン:1500円\n2 クッキー:450円\n3 スナック菓子:850円\n4 ソーダ:600円\n5 カップ麺:1000円\n6 野菜ジュース:600円\n・支払日時:2025/4/20 17:12\n・用途(チェックが入っているもの):キャンプ",
"textExtractionSheet.pdf": "・チーム名:チームPiyoPiyo\n\n・費用:5000円\n\n・費用の内訳:\n1 チャーハン:1500円\n2 クッキー:450円\n3 スナック菓子:850円\n4 ソーダ:600円\n5 カップ麺:1000円\n6 野菜ジュース:600円\n\n・支払日時:2025/4/20 17:12\n\n・用途(チェックが入っているもの):キャンプ",
"textExtractionSheet.png": "以下の形式で画像からの情報を抽出しました:\n\n・チーム名:チームPiyoPiyo\n・費用:5000円\n・費用の内訳:\n 1 チャーハン:1500円\n 2 クッキー:450円\n 3 スナック菓子:850円\n 4 ソーダ:600円\n 5 カップ麺:1000円\n 6 野菜ジュース:600円\n・支払日時:2025/4/20 17:12\n・用途(チェックが入っているもの):キャンプ",
"textExtractionSheet.webp": "・チーム名:チームPiyoPiyo\n・費用:5000円\n・費用の内訳:\n 1 チャーハン:1500円\n 2 クッキー:450円\n 3 スナック菓子:850円\n 4 ソーダ:600円\n 5 カップ麺:1000円\n 6 野菜ジュース:600円\n・支払日時:2025/4/20 17:12\n・用途(チェックが入っているもの):キャンプ"
}
先頭に以下の形式で画像からの情報を~~のような文言がついてるものもありますが、これはシステムプロンプトを改善して修正できるものかと思ってます。
追加例:返答の冒頭に挨拶や説明は不要です。形式に従って直接結果を出力してください。
レイテンシ
最後に、4つの形式(PDF、png、jpeg、Webp)でどれくらいそれぞれ画像からテキストを抽出するのに時間がかかっているのか見てみました。
3回ほど実行してみたのですが、最も処理時間が短かったのはPDFのフォーマットがでした。
次に時間が短かったのは、pngファイルでjpegとwebpは大体同じくらいに見えます。
ただし検証回数が3回程度なのであまり強くは言えないと思います。
-
processing_time:全体の処理時間 -
api_time:Bedorckの処理時間
"performance": {
"textExtractionSheet.jpeg": {
"file_type": "jpeg",
"processing_time": "4.63秒",
"api_time": "4.13秒"
},
"textExtractionSheet.pdf": {
"file_type": "pdf",
"processing_time": "2.34秒",
"api_time": "2.3秒"
},
"textExtractionSheet.png": {
"file_type": "png",
"processing_time": "3.65秒",
"api_time": "3.61秒"
},
"textExtractionSheet.webp": {
"file_type": "webp",
"processing_time": "4.05秒",
"api_time": "3.98秒"
}
}
"performance": {
"textExtractionSheet.jpeg": {
"file_type": "jpeg",
"processing_time": "4.78秒",
"api_time": "4.33秒"
},
"textExtractionSheet.pdf": {
"file_type": "pdf",
"processing_time": "2.25秒",
"api_time": "2.2秒"
},
"textExtractionSheet.png": {
"file_type": "png",
"processing_time": "3.78秒",
"api_time": "3.76秒"
},
"textExtractionSheet.webp": {
"file_type": "webp",
"processing_time": "4.1秒",
"api_time": "4.04秒"
}
}
"performance": {
"textExtractionSheet.jpeg": {
"file_type": "jpeg",
"processing_time": "5.08秒",
"api_time": "4.6秒"
},
"textExtractionSheet.pdf": {
"file_type": "pdf",
"processing_time": "2.44秒",
"api_time": "2.37秒"
},
"textExtractionSheet.png": {
"file_type": "png",
"processing_time": "4.37秒",
"api_time": "4.32秒"
},
"textExtractionSheet.webp": {
"file_type": "webp",
"processing_time": "5.03秒",
"api_time": "4.98秒"
}
}
終わりに
Amazon TextRact、Recognitionでは現状画像から日本語のテキスト抽出ができなさそうでしたが、Amazon Bedrockを使用すると実装できたので代替案にはなるとかと思いました。
また、PythonのライブラリでもPDFから画像の抽出はできると思うので、LambdaのLayerにそれを当てて試してみたいです。