はじめに
記事の対象者と目的
こんにちは!株式会社エンラプト開発チームです。
本記事では、画像生成技術に興味がある方、またはAI開発に興味がある方に向けて、openAIが提供するサービスDALL·E2とChatGPTを組み合わせて、自らの頭の中に思い描いたイメージにより近しい画像を生成する方法について解説します。
DALL·E2の概要
DALL·E2は、openAIが開発した画像生成AIです。DALL·E2は、与えられた文章に対して、その意味に基づいた画像を生成することができます。
たとえば、「白い毛並みの猫が家の中で寝ている」などのテキストの説明に基づいて、最適な画像を生成します。
DALL·E2は画像を入力として受け取ることも可能で、入力された画像とテキストを組み合わせて新しい画像を生成することや、画像の編集も可能です。
また、「赤い靴を履いた象」や「翼を持った丸い蛇」など、想像上にしか存在しない画像を生成することもできます。
DALL·E2にはコンテンツポリシーやリスク、制限などが存在します。詳しくはDALL·E2の公式ページをご確認ください。
ChatGPTの概要
ChatGPTは、openAIが開発した自然言語処理AIです。ChatGPTは、大量の文章データを学習し、与えられた文章に対して、自然な返答を生成することができます。ChatGPTは、文章生成や文章理解の分野で高い性能を発揮しています。
ChatGPTに関してはこちらの記事でも詳しく紹介しているため、合わせてご覧いただけると幸いです。
DALL·E2とChatGPTを組み合わせた画像生成
DALL·E2のみを使用した場合
DALL·E2は、文章を読み取って画像を生成することができます。しかし、DALL·E2は画像を生成するために必要な情報が不十分な場合、出力結果にばらつきが生じてしまいます。
自らの想像する状態を詳細に表すにはDALL·E2に渡すプロンプトに適切なキーワードを追記する必要があります。
例えば、「可愛い猫」という曖昧な状態を表す文章を与えられた場合、DALL·E2は猫の画像を生成することはできますが、猫の種類や色などはバラバラになってしまいます。
DALL·E2の出力結果

DALL·E2とChatGPTを組み合わせた場合
DALL·E2とChatGPTを組み合わせることで、曖昧な画像情報のテキストから追加すべきキーワードをユーザーから聞き出し、よりイメージに近しい画像を生成することができます。
具体的にはChatGPTに以下のプロンプトを与え、曖昧なテキストからより具体的な画像を生成するための属性を出力します。
[画像の抽象的な情報]をより具体化するための属性をできるだけ多く洗い出して、出力してください。
* 余計なラベルや補足は出力しないでください。
[画像の抽象的な情報]
可愛い猫
種類:例えば、スコティッシュフォールド、アメリカンショートヘア、ペルシャ猫など
毛の色や模様:例えば、茶色、白黒、三毛、斑点模様など
毛の質感:例えば、柔らかそう、フサフサ、つややかなど
目の色:例えば、黄色、緑、青など
耳の形:例えば、折れ耳、立ち耳、大きめの耳など
顔つき:例えば、丸顔、細長い顔、シャープな顔つきなど
しぐさ:例えば、寝そべっている、顔を洗っている、じゃれているなど
背景色や環境:例えば、屋内、屋外、植物のある場所など
ポーズ:例えば、横向きに寝そべっている、正面を向いて立っている、飛び跳ねているなど
大きさ:例えば、小さい子猫、大きめの成猫など
ChatGPTから提案された属性に対するキーワードを追加して、DALL·E2に渡すデータとして最適化したテキストをChatGPTで生成します。
DALL·E2のプロンプトを向上させるための方法は以下のリンクに詳しく記載されています。
今回は画像の情報とキーワードをカンマ区切りの英語で出力します。
[画像の抽象的な情報]と[属性]を基に画像生成AIで画像を生成したいです。
画像を生成するためのプロンプト[出力フォーマット]のみを英語で出力してください。
余計なラベルや補足は出力しないでください。
[出力フォーマット]
{Description of the image},{keyword1}, {keyword2},..., {keywordN}
[画像の抽象的な情報]
可愛い猫
[属性]
種類:スコティッシュフォールド
毛の色や模様:白
毛の質感:フサフサ
目の色:青
耳の形:折れ耳
顔つき:丸顔
しぐさ:寝そべっている
背景色や環境:屋内
ポーズ:横向きに寝そべっている
大きさ:小さい子猫
Cute cat, Scottish Fold, white fur, fluffy texture, blue eyes, folded ears, round face, lying down, indoor environment, lying sideways, small kitten.
簡潔な情報がカンマ区切りの英語で出力されました。
出力結果を実際にDALL-E2に入力してみます。
DALL·E2の出力結果
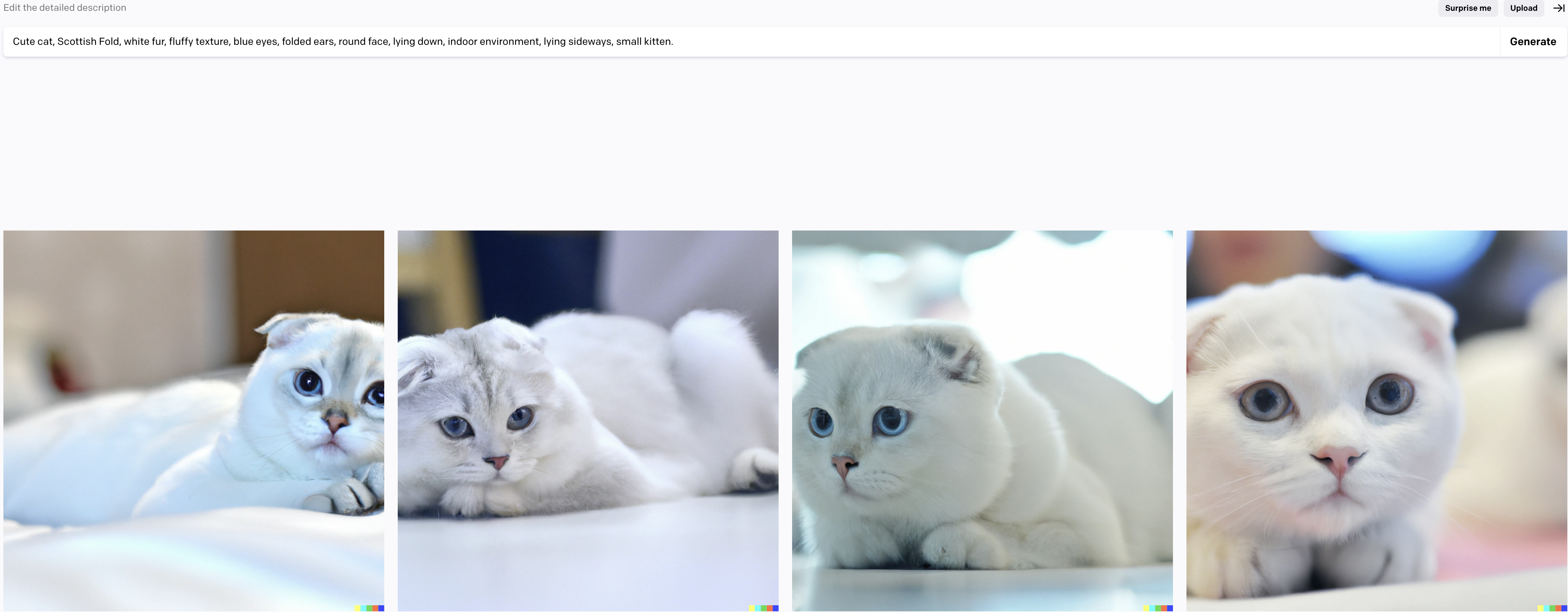
このように出力結果の画像にばらつきの少ない、入力した情報に応じた画像が生成されました。
DALL·E2に追加すべき属性をChatGPTが提案してくれるため、属性に沿ったキーワードを入力することでより詳細な結果を出力することが可能になります。
DALL·E2とgpt-3.5-turboのAPIを使用したアプリケーションの作成
アプリケーションの概要
DALL·E2とChatGPTを組み合わせた画像生成の技術を用いて、よりイメージに近い画像を自動生成するwebアプリケーションをnext.jsで作成します。
このアプリケーションでは、以下の流れで画像を生成します。
- ユーザーが画像の曖昧な情報(可愛い猫)を入力することで、画像をより具体的にするための属性(種類,毛の色)の入力欄をgpt-3.5-turboのAPIが生成します。
- 画像の曖昧な情報と属性に対する入力に基づいてDALL·E2のプロンプトに渡すべきテキストをgpt-3.5-turboのAPIが生成します。
- 出力されたテキストをDALL·E2のAPIのpromptに渡し、画像を自動的に生成します。
作成したアプリケーション
アプリケーションの実装
環境構築や表示部分の説明は省略し、作成したAPIのコードのみ説明します。
APIは2種類あり、一つはユーザーが入力した画像の情報から属性を出力します。
もう一つはユーザーから入力された情報を元に最適なプロンプトを作成し、画像生成APIに渡して画像を生成します。
属性出力API
import type { NextApiRequest, NextApiResponse } from 'next';
import { Configuration, OpenAIApi } from 'openai'
const configuration = new Configuration({
apiKey: process.env.OPENAI_API_KEY,
})
const openai = new OpenAIApi(configuration)
export default async function handler(
req: NextApiRequest,
res: NextApiResponse,
) {
const keyword = req.query.keyword as string;
const response = await openai.createChatCompletion({
model: "gpt-3.5-turbo",
temperature: 0.7,
messages: [
{
role: "system",
content:`[画像の抽象的な情報]をより具体化するための属性をできるだけ多く洗い出して、
* コードブロックなし
* [出力フォーマット]で出力してください。
* 余計なラベルや補足は出力しないでください。
* 出力結果は[出力フォーマット]のみ出力してください。
[出力フォーマット]
[
{\"attribute_name\": \"スタイル\", \"description\": \"写真、デジタルアート、油絵など\"},
{ \"attribute_name\": \"構図\", \"description\": \"俯瞰、正面図、斜めから見た図など\" },
{ \"attribute_name\": \"背景\", \"description\": \"森、山、海、湖、街並みなど\"}...
]
`
},
{ role: "user", content: `[画像の抽象的な情報]=${keyword}` },
],
});
const variables = await response.data.choices[0].message?.content;
res.status(200).json({ variables });
}
ユーザーから入力されたテキストはkeywordという変数に渡されます。
openai.createChatCompletionを使用して、keywordに基づく属性をgpt-3.5-turboが出力フォーマットに合わせて出力します。
プロンプトですがoutputは出力フォーマットのみにしたかったため、制約をいくつか記載しています。
プロンプト生成と画像生成のAPI
import type { NextApiRequest, NextApiResponse } from 'next';
import { Configuration, OpenAIApi } from 'openai'
const configuration = new Configuration({
apiKey: process.env.OPENAI_API_KEY,
})
const openai = new OpenAIApi(configuration)
export default async function handler(
req: NextApiRequest,
res: NextApiResponse
) {
// openAIでDALL-E2に渡すプロンプト生成
const abstractInputKeyword = req.body.keyword;
const attributeVariables = req.body.variables;
const formattedStringAttributes = attributeVariables.map((attribute: { attribute_name: string; value: string; }) => `${attribute.attribute_name}:${attribute.value}`).join("\n");
const responseGPT = await openai.createChatCompletion({
model: "gpt-3.5-turbo",
temperature: 0.7,
messages: [
{
role: "system",
content:`[画像の抽象的な情報]と[属性]を基に画像生成AIで画像を生成したいです。
画像を生成するためのプロンプト[出力フォーマット]のみを英語で出力してください。
余計なラベルや補足は出力しないでください。
[出力フォーマット]
{Description of the image},{keyword1}, {keyword2},..., {keywordN}
`
},
{ role: "user", content: `[画像の抽象的な情報]=${abstractInputKeyword},\n [属性]=${formattedStringAttributes}` },
],
});
const imagePrompt = await responseGPT.data.choices[0].message?.content;
// 画像生成AIを使って画像を生成する処理
if (imagePrompt) {
const response = await openai.createImage({
prompt: imagePrompt,
n: 4,
size: "512x512",
response_format: "url"
});
const images = await response.data.data
res.status(200).json({ images });
}
}
openai.createChatCompletionが画像の抽象的な情報と属性に対するinputからopenai.createImageに渡すべきテキストを生成します。
生成されたテキストはimagePromptという変数に格納され、画像生成のAPIにプロンプトとして渡されます。
createImageにはoptionを指定することが可能で、今回は画像は4枚生成,画像のサイズを512×512,レスポンスをurlで指定しています。
デフォルト値や設定できる範囲など、詳しい情報は公式ドキュメントを参照ください。
アプリケーションの実際の使用結果
このアプリケーションを使用することで、ユーザーは自分がイメージする画像をより詳細に生成することができます。
例えば先ほどと同じように「可愛い猫」と入力してみます。
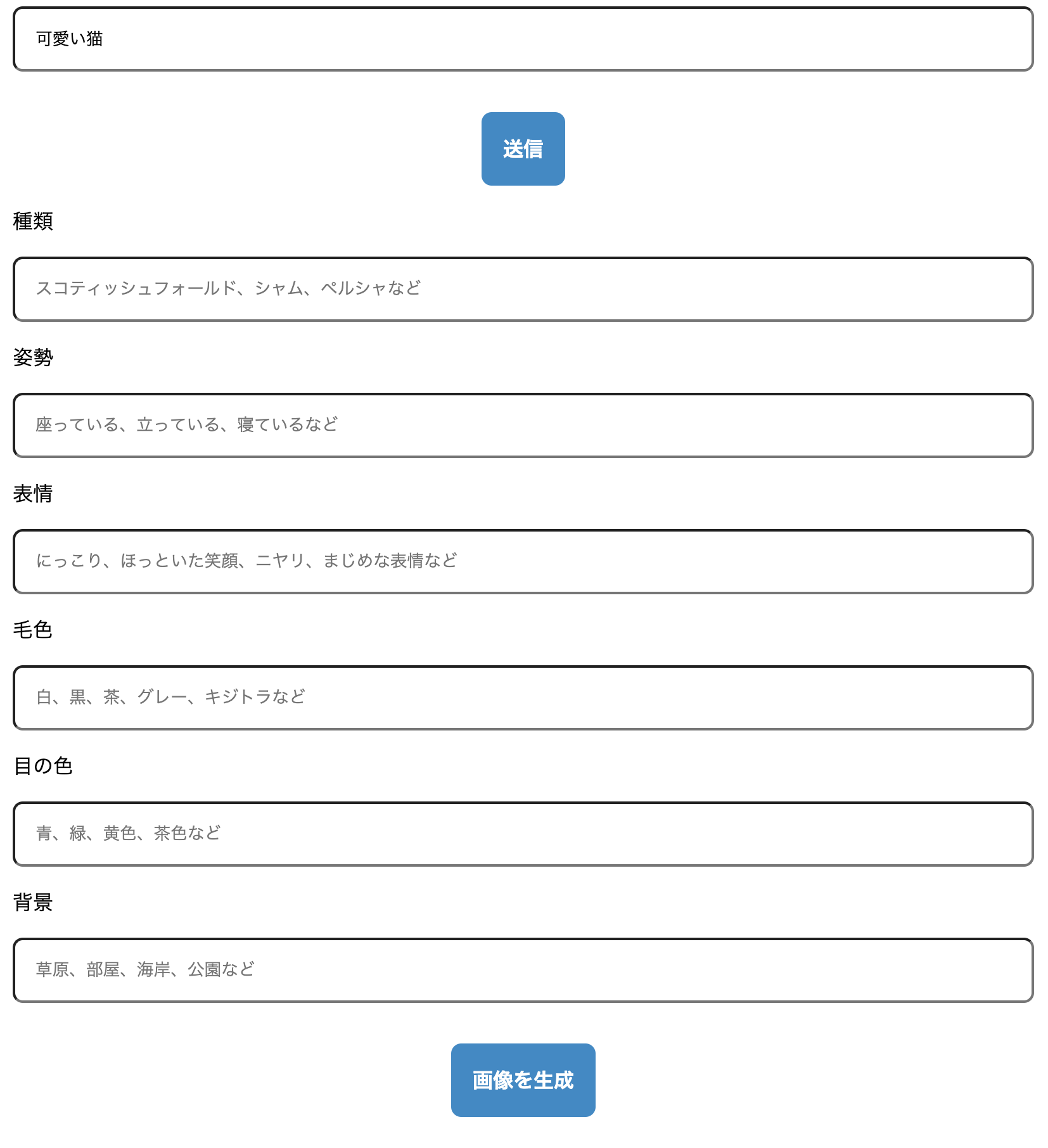
「可愛い猫」というテキストから画像をより詳細に出力するためのinputが生成されます。
'[\n' +
' {"attribute_name": "種類", "description": "スコティッシュフォールド、シャム、ペルシャなど"},\n' +
' {"attribute_name": "姿勢", "description": "座っている、立っている、寝ているなど"},\n' +
' {"attribute_name": "表情", "description": "にっこり、ほっといた笑顔、ニヤリ、まじめな表情など"},\n' +
' {"attribute_name": "毛色", "description": "白、黒、茶、グレー、キジトラなど"},\n' +
' {"attribute_name": "目の色", "description": "青、緑、黄色、茶色など"},\n' +
' {"attribute_name": "背景", "description": "草原、部屋、海岸、公園など"}\n' +
']'
出力された属性に対して、キーワードを入力し、画像を生成します。
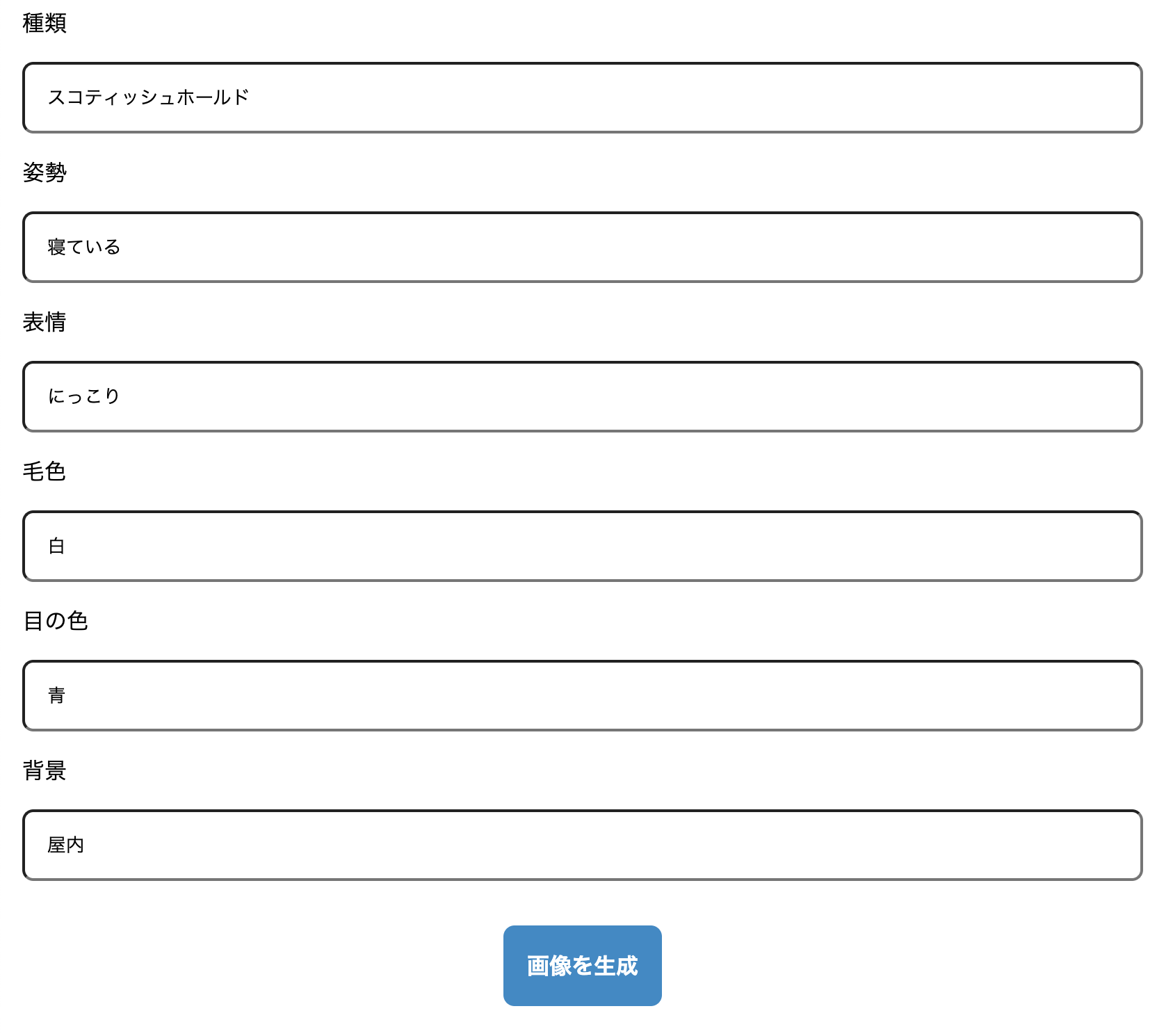
実際にcreateImageに渡すプロンプト
Cute sleeping Scottish Fold cat with a smiling face, white fur, blue eyes, and indoor background.
生成された画像

inputの情報に応じた画像を生成することができました。
出力される属性はgpt-3.5-turboが自動的に判断するため、ランダム性はありますがこれを使用することでよりイメージに近しい画像を生成することができます。
そのほかにもテーマを変えて生成した画像の例です。
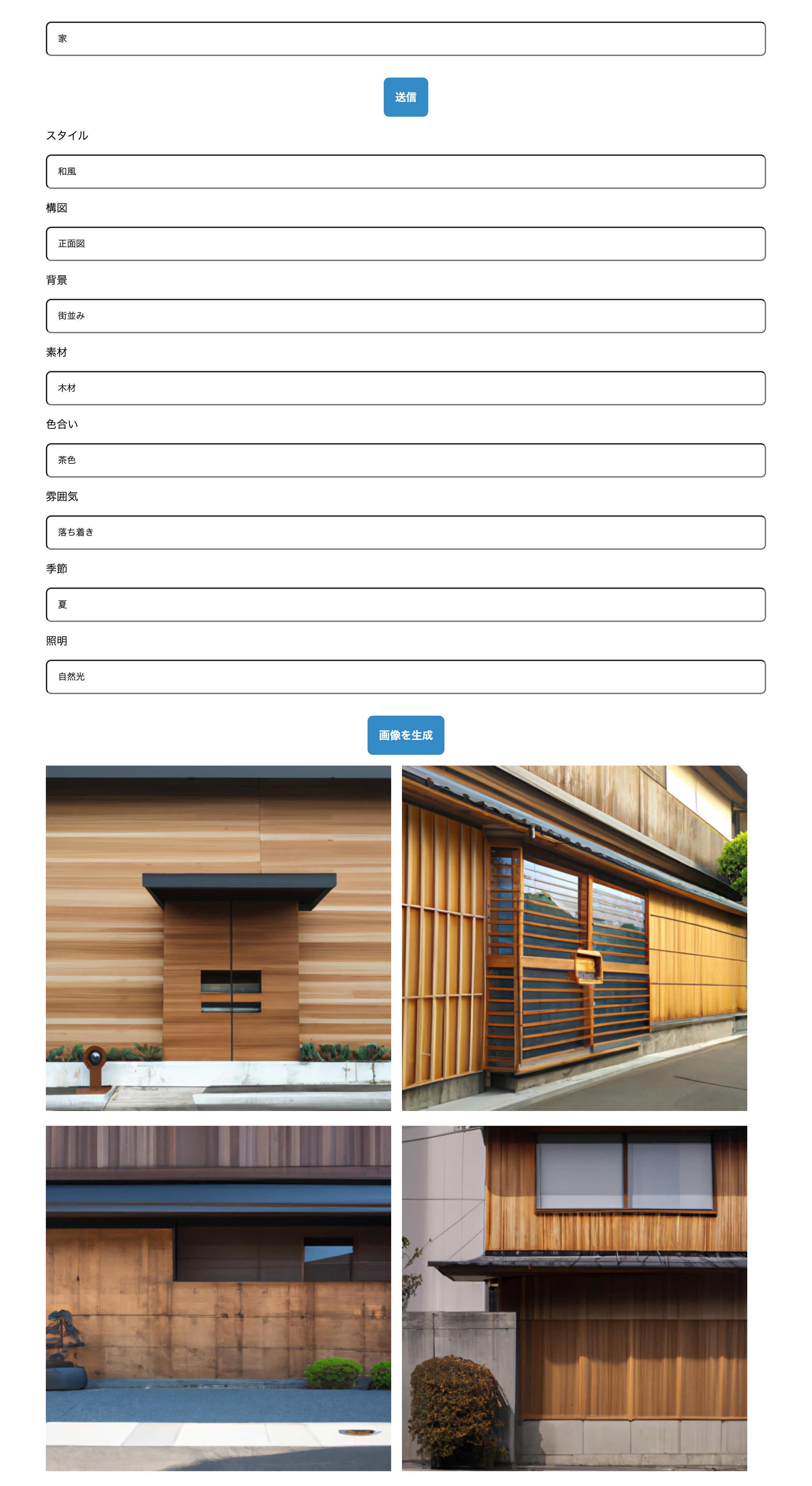

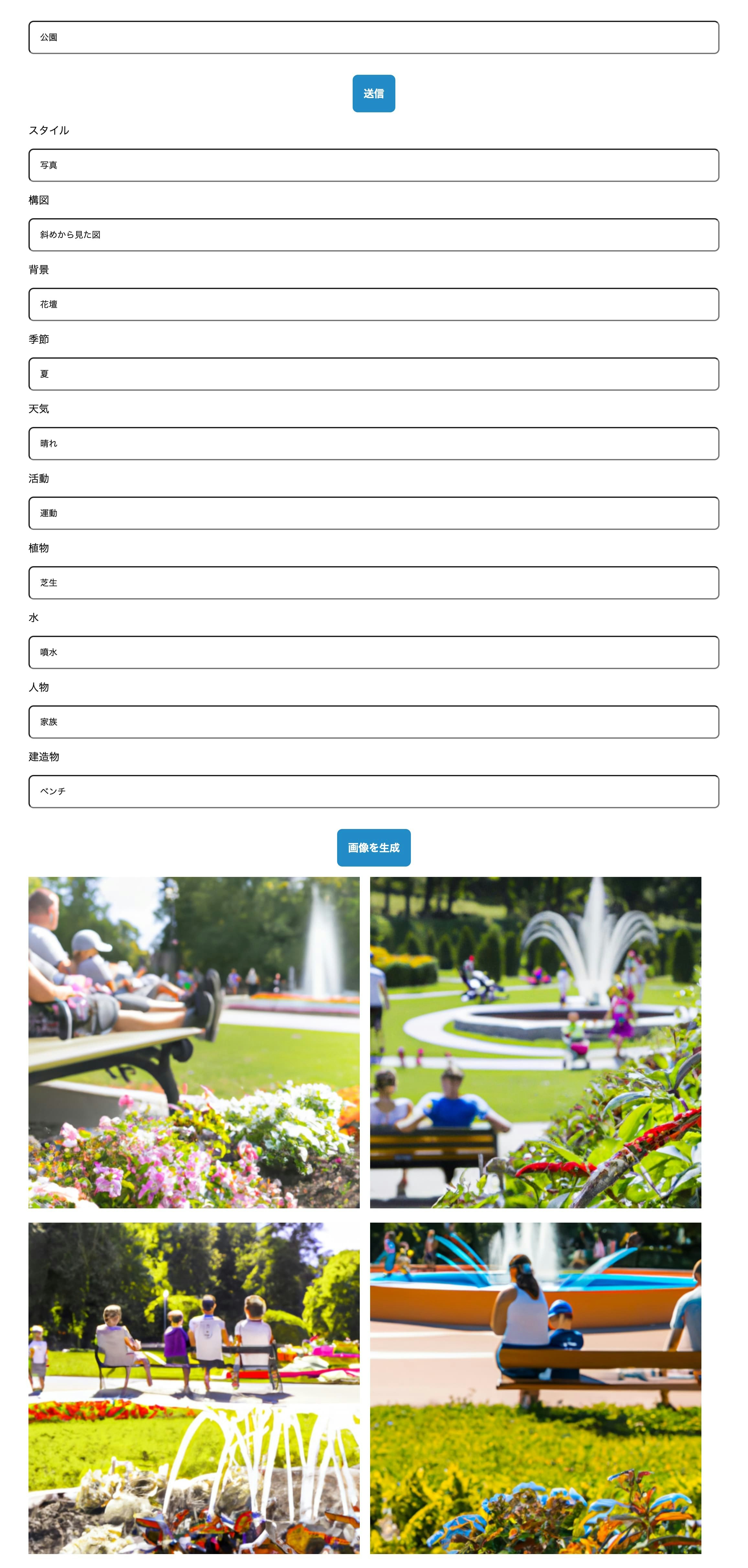
まとめ
この記事では、DALL·E2とChatGPTを組み合わせることで、よりイメージに近い画像を生成する方法を紹介しました。今後さらにDALL·E2とChatGPTの技術が進歩することで、より詳細な画像の生成が可能になるでしょう。
現在法整備や倫理規定が追いついていないこともあり、商用利用には慎重になる必要がありますが、これから画像生成AIはさらに普及されていくと筆者は感じます。
画像が大量に必要なサービスにおいては、コスト削減につながるかもしれません。この記事を参考に是非ともお試しください。
また、株式会社エンラプトでは、OpenAIのサービスを使ったソリューションの研究を日々行っています。もし、弊社のサービスや採用に関心があればお気軽にお問い合わせください。ホームページにはOpenAIサービスを利用したFAQチャットもご用意しています。
それでは、最後までご覧いただきありがとうございました!