はじめに
皆さん、今回は早めに投稿できたと思っています。enp(えん)です。恋愛がしたいです。
この記事は『RPAツール』を作ろうとする人の進捗報告になります。
RPAやRPAツールの作り方が書いてあるものではございませんので、ご了承ください。(もしかしたら、ソースは少しだけ載せるかもしれません。気分次第です)
今回はseleniumと仲良くなろうPart.2です。やったこととしては『住所から郵便番号への変換』と『郵便番号から住所への変換』です。
また長い記事になってしまいますが、お付き合いいただければ幸いです。
僕はテキストを取得したいだけなんですッ!!
はい。タイトルそのまんまです。
ブログに書いてある文字やウィキペディアに記載されている文字などを取得したい。今回の記事はそれだけです。
じゃあ、なんで住所から郵便番号取得しようとしてんの? ってなりますよね。
それは__仕事で必要なインターネット上の情報を僕の偏見と独断で考えた結果、郵便番号だったから__です。
仕事内容によって他にインターネットで必要な情報はあると思います。
ですが、__仕事内容関係なく__郵便番号って調べそうだと思いました。あくまで私の偏見です。
また、__扱うテキスト多そう__という単純な理由も含みます。
じゃあ、なんで郵便番号から住所を取得しようとしてんの? 住所から郵便番号分かればいいじゃん。そうです。
しかし、__逆の機能がないと不便かもしれないじゃないですか。あと、なんか逆の機能がないと落ち着きませんでした。
という訳で今回は『住所から郵便番号への変換』と『郵便番号から住所への変換』__という二つの機能を実装しました。
(はっきり言って、探せば住所や郵便番号を扱うライブラリはあると思います。しかし、今回はselenium学習のために実装するのでライブラリで住所を探す等の行為は行いません。seleniumで実装していきます)
まずはサイトの仕様を知ろう
サイトの仕様が分からなければ実装の仕様がありません。なので郵便番号検索等について学びましょう。
まずは郵便番号から住所の検索についてです。

上記は郵便番号検索の検索バーです。まぁ、テキストボックスに郵便番号いれてボタンを押せば終了ですよね。分かりやすい。
では、検索した後はどうでしょう?

こんな感じに表示されます。表の中から住所を抜き出せば取得できそうですね。
次に住所から郵便番号の検索です。
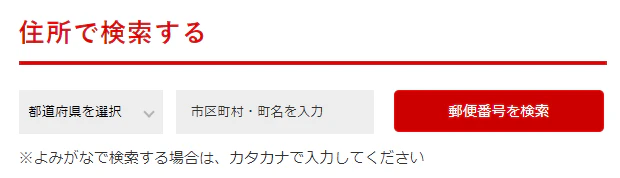
さて、ここで気になるのが__都道府県の選択__です。選択をseleniumで実装するのは少し骨が折れそうなイメージ。
しかし、日本郵便局は大変親切です。市区町村などを入力する欄に必要な住所全て入れても検索可能なのです。
有難い。今年は年賀状を出すか検討することにしましょう。送る人はいませんが。
検索後は以下のようになります。

郵便番号は記載されていませんね。町域にある住所をクリックした場合はどうなるのでしょうか?
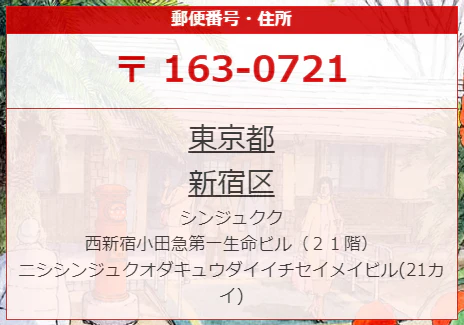
上記のようになります。ここでようやく郵便番号が出てきます。住所から郵便番号への変換の方がひと手間増えますね。
以上がサイトの仕様です。
(『検索後、他に候補がない』ことを前提として実装していきます。郵便番号で検索した場合、郵便番号が対応している住所は一つに定まるはずです。また、一部を除き住所検索でも曖昧検索をしなければ一つに定まるはずです。曖昧検索をする場合、『ユーザーが選択する前提』で検索を行っているので『自動化』ではないと思います。そのため、曖昧検索には対応しないことにしました)
要素取得の限界
じゃあ、早速実装していきましょう! と言いたいところですが、ここで問題が発生しました。
今までは__要素の属性名を使ってテキストボックスに文字を入力したり、ボタンをクリックしたりしてきました。__
(要素とはdivやinput、属性はclassやidのことを指します)
では、属性名が複数の要素で使われていたらどうなるでしょうか?
例えばclassにsampleという名前がいろんなdivに使われている場合です。
その場合、入力したい場所やクリックしたい場所を正確に特定することができません。
属性名で要素を特定したいときはid名やname名を使うのですが、必ずidやnameが使われている保証はありません。
また、属性名を使用していない場合もあります。
要素名を使って指定することもできますが、Webページにはdivという要素が多用されていて一つを特定するのには不向きです。
じゃあ、どうすればいいんや!! そういう時はXPathを使いましょう。
XPath? なにそれ? バンド? と思われるかもしれません。その人が想像しているのはX JAPANかもしれない。
ということで、次の項目ではXPathについて軽く説明します。
XPathとは何ぞや?
XPathとは簡単に言うと__要素の住所__のことです。
ちょっとサンプルを用いて説明しましょう。
<html>
<head>
<title>Sample HTML</title>
</head>
<body>
<h1>HTMLのサンプル</h1>
<p>This is HTML Sample.</p>
<p>This is HTML Sample.</p>
</body>
</html>
上記はHTMLのサンプルプログラムです。サンプルであることを過剰に主張しています。
HTMLの説明をしているわけではないので、どのようなHTMLなのかというところは省きますが、
重要なのは属性が使われておらず、要素が複数使われているものがあるということです。
さぁ、ここで皆さんに質問です。<○○>○○>で一個の塊に見えないでしょうか?
見方としてはhtmlの中にbodyがあるような感じです。その感じがXPath。
htmlの中のbodyの中の二番目のpと聞くと、サンプルプログラムでの8行目のことかな? となんとなく分かるはずです。
同じことがseleniumでも出来るということです。
じゃあ、どうやって書くの? 文字で書けなければプログラムに書けませんね。
書き方としては下記のとおりです。
/html/body/p[2]
言ってることはさっきと一緒です。『htmlの中のbodyの中の二番目のp』を指しています。
しかし、いちいちhtmlから書いていくのは難しいです。
全てのHTMLがサンプルのように短ければ出来るかもしれませんが、長いと頭がこんがらがってきます。
そのため、必要な部分までのXPathを『//』で省略することができます。
以上XPathの説明でした。もっと詳しいことが知りたい方は自分でお調べください。
実装!
さぁ、いよいよ実装しましょう。プログラムは以下の通りです。
# ライブラリインポート
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
import psutil
import re
# 郵便番号または住所の入力
postHint = input("郵便番号または住所:")
# ドライバーインポート
chrome = webdriver.Chrome(r".\driver\chromedriver.exe")
# JPの郵便番号検索ページへ移動
chrome.get("https://www.post.japanpost.jp/zipcode/")
# 『郵便番号から住所』か『住所から郵便番号』かの条件分岐
while True :
if re.fullmatch("((\d{3})-(\d{4}))|(\d+)", postHint) : # 郵便番号から住所を検索する場合
if re.fullmatch("(\d{3})-(\d{4})", postHint) : # -ありの場合、-を削除
postNumber = postHint.replace("-", "")
else :
postNumber = postHint
# 郵便番号から住所を検索する
textarea = chrome.find_element_by_name("zip") # 郵便番号を入力するテキストボックス
textarea.send_keys(postNumber) # 郵便番号を入力
textarea.send_keys(Keys.ENTER) # エンターで決定
# 住所を取得
ken = chrome.find_element_by_xpath("//table[@class='prefList sp-b10']/tbody/tr[2]/td[2]/small").get_attribute("textContent")
si = chrome.find_element_by_xpath("//table[@class='prefList sp-b10']/tbody/tr[2]/td[3]/small").get_attribute("textContent")
machi = chrome.find_element_by_xpath("//table[@class='prefList sp-b10']/tbody/tr[2]/td[4]/div/p/small/a").get_attribute("textContent")
# 住所の結合
address = ken + si + machi
# 結果
print("検索結果:" + address)
# ループを抜ける
break
elif re.fullmatch(".+?県.+?\d*?-?\d*?-?\d*?-?\d*?-?\d*?", postHint) : # 住所から郵便番号の場合
# 住所の数字部分を削除
if re.search("\d", postHint) :
postAddress = re.sub("\d+?-?\d*?-?\d*?-?\d*?-?\d*?", "", postHint)
else :
postAddress = postHint
# 住所から郵便番号を検索する
textarea = chrome.find_element_by_name("addr") # 住所を入力するテキストボックス
textarea.send_keys(postAddress)
textarea.send_keys(Keys.ENTER)
#一秒間待機(ブラウザの処理が追い付かないため)
time.sleep(1)
# 郵便番号の取得
button = chrome.find_element_by_xpath("//table[@class='prefList sp-b10']/tbody/tr[2]/td[2]/div/p/a") # リンクを取得
button.click()
addressNumber = chrome.find_element_by_xpath("//table[@class='zip-detail']/tbody/tr[2]/td[1]/span").get_attribute("textContent")
# 結果の出力
print("検索結果:" + re.sub("\s*?", "", addressNumber))
# ループを抜ける
break
else :
postHint = repr(input("郵便番号または住所:"))
p = psutil.Process(chrome.service.process.pid)
p.terminate()
シンタックスハイライトを無効にしたので少し見辛いかもしれません。
しかし、シンタックスハイライトを有効にしたらもっと見辛かったので無効にしました。
待機処理についてはsleepよりも良いものがるのですが、今回はsleepにしました。理由は特にありません。本題ではないので。
プログラムがやってることは簡単です。検索して情報を取得する。以上! シンプル!
ですが、このプログラムには__致命的な欠点が二つほどあります。__
そもそもエラーハンドリングしてませんからね。厳密には二つどころじゃないでしょうが。
さて、致命的な欠点一つ目は住所での検索時、候補がいくつかあったらバグります。
全ての住所を正しく入力しても候補が出てくる事があります。その場合、正しい郵便番号を出力しない可能性があります。
原因はXPathで第一候補を選択するようにしているからです。
第一候補以外ない状況を想定していた為のバグと言えるでしょう。
解決策の一つとして、候補それぞれの住所とユーザーが入力した住所を比較するという方法があります。
致命的な欠点の二つ目は住所検索の正規表現が緩いです。
問題の正規表現は『.+?県.+?\d*?-?\d*?-?\d*?-?\d*?-?\d*?』。
文字化け? と一瞬思いそうな文字たちですね。
正規表現については説明しませんが、__表していることは『○○県の後ろに何かしらの文字があればOK』というもの__です。
つまり『熊本県桜』と書いても正しいと認識します。究極『まる県か』でもOKです。
しかし『東京都』や『京都府』など『○○県』でないものは検索してくれません。
ユルユル過ぎて話にならない。もちろん検索して何もヒットしなかったらエラーを吐いてプログラムは終了します。
__正規表現がユルユルな理由は住所の書き方は都道府県で違うから__です。
○○県○○市○○があれば○○県○○市○○区○○、○○県○○群○○などなど。
その全てを調べて対応するのは不可能です。何かしらのリストがあれば出来るかもしれません。
しかし、今のところ個人で調べるしか方法はないのでユルユルな正規表現になりました。
__また、東京都などを検索してくれない問題は単純に私が忘れていただけです。__申し訳ない。
RPAツールを実装する上で必要なこと
さて、今回も今までの経験に基づき、実装にかかわる内容を列挙したいと思います。
以下、箇条書きです。
- 要素の取得にXPathが使えないと限界がある
- プログラミングができない人のためにXPathが何か説明が必要
- プログラミングができない人のためにXPathの書き方には工夫が必要
- 待機処理がないとうまく動かない場合がある
- 条件分岐や繰り返しができた方がRPAの幅が広がると感じた
- 繰り返しについてbreakなどが使えたら便利
- 正規表現が使えた方がいい
- プログラミングができない人のために正規表現が何か説明が必要
- プログラミングができない人のために正規表現の書き方には工夫が必要
- テキスト取得にはget_attribute("textContent")を使った方が良い
- 文字列の結合機能も欲しい
- 結構しっかりとエラーハンドリングしないとすぐ壊れそう
現在、思いつく限りでは以上です。
get_attribute("textContent")はブラウザに表示されていない文字も取得できるため、
エラーを吐きにくくなると考えています。
最後に
最後までお付き合いいただきありがとうございます。
今回でseleniumさんとは結構仲良く出来るかなと思っています。
しかし、最後にseleniumさんとやりたいことがあるので、まだしばらくselenium編が続きます。
次回の記事は『seleniumと仲良くなろう Part.3』になると思いますので、よろしくお願いいたします。
以上、enpがお送りいたしました。