初投稿です。
今回は、どこにでもいるエロゲライターが、スクリプト作業を人工知能を使って楽をしようとした話をシェアさせていただきます。
ちなみに対象としたのはこちらの作品(リンク先成人向け注意)ですが、未発売の作品なので、サンプルとして表示している文章は私の同人時代のものに差し替えてあります。
自己紹介
- 新人エロゲライター
- プログラミングや自然言語処理の経験は有り
某月末日
その日私は、〆切を前に焦っておりました。
Qiitaを読んでおられるようなエンジニア諸氏ならご存じの通り、エロゲのテキスト〆切には「音声収録開始日」というものが大きく関わっています。
そのときの私のテキストは、以下のような状態でした。
我が麗しのメロンソーダを持って専用ブース(ジャンキーの隣だ)へ赴くと、PC前の椅子には見慣れた先客が居た。
「おきゃくさーん、すいませんここ俺のブースなんですけどー」
「あっ、吉野さん! もう、遅いじゃないですか」
「いや待たせてたつもりは微塵もないんだけど。あと聞こえなかったようなので繰り返しますが、ここわたくしめのブースです」
「知ってますよ?」
だからどうかしましたか、とでも言わんばかりに立ち上がりながら首を傾げる。
まるで庶民の持ち物を使うのは貴族の権利、みたいな反応だった。
見て分かるとおり、台詞に発言者のキャラクター名が振ってありません。
これでは声優さんに台本を渡すことができません。困った!
Qiitaを読んでおられるようなエンジニア諸氏ならご存じの通り、エロゲのテキストというのは本当に膨大で、キャラ名を振るだけでも数日作業となってしまいます。
さてどうするか……となった時に、私ははっと閃きました。
「人工知能、使えるのでは……?」
目標
ここまでは前振りで、ここからが本題です。
- 機械学習を利用して、発言者の分類を行う
- うまくいったら、スクリプト作業(立ち絵の表情表示など)にも応用する
セリフの発言者を分類する方法は、すでに多くの先例があります。
参考にさせていただいたのは下記あたり。
「耳をすませば」の月島雫のセリフは分類できるか?
城ヶ崎美嘉(CV:佳村はるかさん)の誕生日なので,セリフが城ヶ崎美嘉か城ヶ崎美嘉じゃないかを多層パーセプトロンで判別してみた
今回はChainerのTrainerを用いて作成することにしました。
実装
予測結果取得
ChainerのMNISTのサンプルを改造して使用します。
今回は学習後の正答率だけではなく、学習後の予測結果自体が欲しいので、
chainer/functions/evaluation/accuracy.pyを以下のようにいじりました。
def forward(self, inputs):
xp = cuda.get_array_module(*inputs)
y, t = inputs
...
else:
pred = y.argmax(axis=1).reshape(t.shape)
# 予測結果取得(forwardのたびに上書き…)
f = open('output_path/output.txt', 'w')
arr = map(lambda x:str(x), list(pred))
lines = f.write(','.join(arr))
f.close()
return xp.asarray((pred == t).mean(dtype=y.dtype)),
ミニバッチで学習させると予測結果が一括では取得できなくなるので、
batchsizeを要素数より大きくして回しています。
データ整理
いろいろと手法は考えられるのですが、今回はいわゆるBag of Wordsを使います。
- MeCabを利用、セリフのみを収集
- キャラクターの呼称をMeCab辞書に登録
- 「……」や「――!」みたいなのを省くため、4文字以下のセリフは切り捨て
- 出現回数が2回以下の要素は無視
- 極端に台詞が少ないサブキャラは無視
- 教師として、その時点ですでに発言者名が入っていたシーンのテキストを利用
発言者を確定できるセリフ(呼称が特殊とか)を集めてそれを教師とする案もあったのですが、意外と量が集まらなかったので諦めました。
結果
unit: 50
Minibatch-size: 3000
epoch: 200
教師データの要素数 653
〃 台詞数 1401
テストデータの台詞数 289
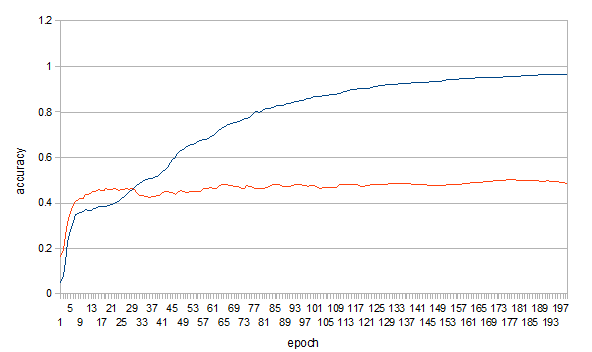
青が教師、赤がテストデータです。
見ての通り、accuracyが0.5前後で停滞しているのが分かります。
最終出力は10キャラにしたので、ランダムよりは遥かにいいですが、実用にはちょっと…という結果になりました。
考察
いろいろ試したことを箇条書きに。
- BoWの単語から記号(?、…等)を抜くと、精度が悪化する。
- 考えてみれば、キャラによっては「!」を多用したり「…」を多用したりと差があるので、納得です。
- MNISTのデフォルトと同じく三層で試したのですが、二層目は30~50辺りにすると安定しました。
- キャラを推測するのに必要な要素は、出現単語の種類よりずっと少ないためでしょうか。
- 精度は5割だったものの、意外としっかり学習してるっぽい。
- 予測を誤った文章を見ていくと、「同じ呼称を使うキャラ同士」「男勝りな口調の女性キャラと男性キャラ」など、結構納得いく誤りが多かったです。
- 一番精度にいい影響があったのは、MeCabへのキャラ名の辞書登録。二番目が考慮するキャラ数を減らすこと。
- 視点が変わったり、個別ルート等でキャラクターの登場に偏りが生じたりすると、一気に精度が悪化。
- ちなみにHシーンはノイズすぎるので省きました。
- 今回の作品はあまり口調で特徴付けしていないのですが、そこでうまく差をつけている作品なんかだと大きく改善する可能性を感じます。
今後
入力補助くらいにはなれば、と思ってましたが、5割ではさすがに…。
ただ上述したとおり、個別に見ればそれなりに学習はしているようなので、シーン毎に登場キャラを指定して予測させる、確定ワードやNGワードを作って個別にケアをする、あたりをすると、そこそこの精度になるような気はします。
あとは地の文も入力層に突っ込むとか、LSTMとか色々あるとは思いますが…。
ちなみにどうしてテストデータのaccuracyが取得できているかというと、プログラム作ったのがマスターアップ後だからです:)
次があれば、もうちょっと調整して作業軽減に繋げられるようにしたいと思います。