あまり英語が得意ではないので原文から離れないように訳して残しておくためのものです。
おなじようにPrometheusを使用している方、これから使用するかたの為になればと思います。
訳し方間違えてるとか、ちょっとPrometheusの思考とは逸れた訳し方してるよ
などあればご指摘ください!
1章については
- Prometheusの概要
- PrometheusでのMonitorigとは
- Monitoringを構成する4要素
- Monitorig界隈の簡単な歴史的背景
- データの量を最適化する4アプローチ
- 4つのログについて
- メトリクスについて
などこの本を読み進めていくのとPrometheusを理解していくのに必要な前提が記載されていました。
また最後の方にはPrometheusの基本構成とそれらを構成する内容についてそれぞれ簡単に説明されており
最後にPrometheusには向かないものが記載されていました。
Chahpter1.
What Is Prometheus?
- Prometheus = ossのmetricsベースのモニタリングシステム
- SoundCloud社が2012年に開始
- Go で書かれておりApache2.0ライセンスの元、公開されている
- 2016年CNCFの第2メンバーとなる
- 様々な環境においてメトリクスを取得することで監視できる
- メトリクスはGrafanaなどを使用してビジュアライズできる
- グラフ化する場合はPromeQLを使用
- アラートを作成する際はラベルベースとなるので管理が容易
- アラートはグラフを作成するPromQLと同じように書ける
- EC2やGCE,K8sなら監視対象を探しだしてくれる
- 1台のPrometheusで毎秒数百万のメトリクスをとりこむことができる
What Is Monitoring?
中学校では、先生の一人に教えてもらった。
10人のエコノミストに経済学が意味することを質問したら11個の答えを得られるだろう
これはMonitoringが正確になにを意味するのかを考える必要があるし
コンセンサスが欠けていてはならない。
監視とはなにか
- 工場の温度を監視すること
- 勤務時間中にだれがfacebookにアクセスしているかを監視すること
- 不正アクセスの検出などを行うこと
上記のように様々な監視が必要であり存在しているが
Prometheusは上記のようなことをするために作られてはいない。
Prometheusは人気のあるwebサイトのサーバやアプリケーション、
ツール、データベース、ネットワークなど実稼働している
コンピュータシステムの運用をおこなっているソフトウェア開発者や管理者を支援するために作らた。
Prometheusが扱うMonitoringは4つ
Alerting
- システムの稼働に問題があるときが、監視をしたい瞬間
- 問題があったときは人間をMonitoringSystemに呼び込む
Debugging
- 根本的な原因を突き止めるために調査
- 問題がなにであれ解決する必要がある
Trending
- AlertとDebuggは通常数分から数時間程度の間で行われる
- 緊急性が高くなくても、システムがどのように使用されているのかを監視
- 時間の経過とともにシステムを変化させることが有益である
- トレンドを知ることはキャパシティプランニングなどの設計上の意思決定に良い影響を与える
Plumbing
- 全ての監視システムはデータ処理パイプライン
- 別のソリューションを構築するのではなく、監視システムの一部を別の目的に適合させる方が便利な場合もある
A Brief and Incomplete History of Monitoring
近年ではPrometheusをはじめとして様々な監視ツールがあるが
NagiosとGraphiteの組み合わせやその変種がまだまだ支配的なソリューションとなっている
ここでいうNagiosとは
- Icingga
- zmon
- Sensu
のような定期的にチェックスクリプトによって処理をおこない
0以外の終了コードを返すことによってチェックが失敗となりアラートが生成されるもの
またここでいうGraphiteとは
メトリクスデータを格納するRRD(ラウンドロビンデータベース)を基礎する
- Smokeping
- Graphite
などのことである。
ここで重要なのは、グラフ作成とアラート作成が完全に別々のものになっているということ
もう1つこの時代の障害としてはサービスを管理する為にとっているアプローチが比較的手動であるという点
これらはシステム管理者が1つ1つ作り上げ愛着をもって管理をし
問題を示唆するアラートを検知した際には献身的なエンジニアによって対応されていた。
EC2やDocker,K8sなどのようにクラウドとクラウドのネイティブテクノロジーが目立つようになるにつれて
1つ1つのマシンやサービスをペットのように扱うと規模を拡大していくのが難しい。
むしろそれらはより多くの牛としてみられグループとして管理されるべきである。
chefやAnsibleのようなツールに移行したのと同じように
K8sのようなテクノロジを使用するような場合、個々のサービスなどと同等にサービス全体として健全性を保つべき。
ログについては歴史的にtailやgrep,awkなどを駆使して使用されてきた。
近年ではelasticsearchやlogstash,Kibanaなどを用いることにより監視の重要な部分としても使用されている。
Categories of Monitoring
監視はイベントと同義である
- HTTPリクエストを受信する
- HTTP400レスポンスを返す
- 関数の入力
- if文のelseへの到達
- 関数を残す
- ログインしているユーザ
- ディスクにデータを書き込む
- ネットワークからのでーたの読み取り
- カーネルからより多くのメモリを要求する
HTTPリクエストには
- 自分が出入りするIPアドレス
- リクエストされているURL
- 設定されているクッキー
- リクエストを行ったユーザ
が含まれます。
HTTP応答には
- 応答の所要時間
- HTTPステータスコード
- 応答本文の長さ
が含まれます。
関数を含むイベントは、それらの上にある関数の呼び出しスタックと、
HTTP要求などのスタックのこの部分をトリガにしたものを持ちます。
すべてのイベントのすべてのコンテキストをデバッグすることは
テクニカルとビジネスの両面でシステムがどのように動作しているかを理解するのに最適だが
その量のデータは処理と格納には実用的ではない。
したがって、データの量を実行可能なものする必要があり、そのアプローチは下記の4つである。
Profiling
プロファイリング =
常にすべてのイベントのすべてのコンテキストを持つことができない =
限られた期間だけコンテキストの一部を持つことができる
プロファイリングツールの一例 = Tcpdump
バイナリのデバッグビルドは多くの有益な情報を提供するが、
継続的に本番環境で実行することは一般的に実用的ではない。
Linuxカーネルでは、拡張されたBerkeley Packet Filters(eBPF)により、
ファイルシステム操作からネットワークのカーネルイベントの詳細なプロファイリングが可能になった。
これらは、以前は一般的に入手できなかったレベルのものであり、Brendan Gregg氏の著書を読むことをお勧めする。
Tracing
トレースはすべてのイベントを調べるのではなく、関心のある機能のうちの1つのイベントの割合を取る。
トレースは、関心のあるポイントのスタックトレース内の関数、および関数のそれぞれが実行するのに要した時間も記録する。
これにより、プログラムがどこで時間を費やしているのか、どのコードパスがレイテンシに最も貢献しているのかを知ることができる。
たとえば、100人のユーザーのHTTP要求のうち1つがサンプリングされ、
その要求に対して、データベースやキャッシュなどのバックエンドとの会話に費やされた時間を確認できる。
これにより、キャッシュヒットとキャッシュミスのような要因に基づいてタイミングがどのように異なるかを確認できる。
分散トレースはこれをさらに進めます。
これは、リモート・プロシージャー・コール(RPC)の1つのプロセスから別のプロセスに渡される要求にユニークなIDを付けて、
トレースする必要があるかどうかに加えて、プロセス間でトレースを行います。
要求IDに基づいて、異なるプロセスおよびマシンからのトレースを一緒に戻すことができる。
これは、分散マイクロサービスアーキテクチャをデバッグするための重要なツールです。
この分野の技術には、OpenZipkinとJaegerがある。
トレースの場合、データ量と計測パフォーマンスが理由で影響を受けるのはサンプリングです。
Logging
ロギングは、限定された一連のイベントを見て、これらのイベントのそれぞれのコンテキストの一部を記録する。
たとえば、すべてのHTTP要求、またはすべてのデータベース呼び出しを調べることができる。
あまりにも多くのリソースを消費することを避けるため、経験則として、ログエントリごとに約100フィールドの範囲に制限されている。
それを超えると、帯域幅とストレージスペースが懸念される傾向にある。
たとえば、毎秒1000件の要求を処理するサーバーの場合、
それぞれが10バイトを取る100個のフィールドを持つログエントリは、
毎秒メガバイトとして動作する。
これは、100 Mbitネットワークカードの重要な部分であり、
ロギングのためだけに1日あたり84 GBのストレージを使用する。
ロギングの大きな利点は、イベントのサンプリングが(通常は)ないことである。
1つの特定のAPIエンドポイントにおいて発生する遅い要求がどの程度影響しているかを判断することが現実的である。
監視とは異なる人物を意味するのと同じように、
ロギングとは、誰が尋ねるかによって異なるものを意味し、混乱を招く可能性があります。
さまざまな種類のログには、使用方法、耐久性、および保持要件が異なります。
これらは一般的に4つのやや重複するカテゴリがある。
- Tlanscation logs:
これらは重要なビジネス記録であり、すべてのコストをかけて安全に保つ必要がある
重要なユーザー向け機能に使用されているものは、このカテゴリに入る - Request logs:
すべてのHTTP要求またはすべてのデータベース呼び出しを追跡するログ。
対ユーザ機能を実装するために、または内部の最適化のために処理される。
一般的に消失してはならないがなくなっても世界の終わりではない - Application logs:
すべてのログが要求に関するものではなく、プロセス自体に関するものもある。
スタートアップ・メッセージ、バックグラウンド・メンテナンス・タスク、およびその他のプロセス・レベルのログ・ラインが典型的。
これらのログは人間によって直接読み取られることが多いため、通常の操作では1分間に数回以上の処理を避けるようにするのが望ましい。 - Debug logs:
デバッグログは非常に細かく、作成して保存するのに費用がかかる傾向がある。
非常に狭いデバッグ状況でのみ使用されることが多い。
信頼性と保持の要件は低くなる傾向がある。
さまざまな種類のログを同じ方法で処理することは、
デバッグログのデータ量とトランザクションログの極度の信頼性要件を合わせた
世界最悪の状況になる可能性がある。
システムが大規模になると、デバッグログを分割して別々に処理できるようにする必要がある。
ロギングシステムの例には、ELKスタックとGraylogがある。
Metrics
メトリクスは主にコンテキストを無視し、時間の経過とともにさまざまなタイプのイベントの集計を追跡する。
リソースの使用状況を維持するためには、追跡される異なる数値の数量を制限する必要があり1プロセス当たり1万が念頭におくべき妥当な上限。
メトリックの種類の例としては、
- HTTPリクエストを受信した回数
- リクエストの処理に費やされた時間
- 現在進行中のリクエストの数
などがあります。
コンテキストに関する情報を除外することにより、必要なデータ量と処理が妥当なものに保たれる。
ユーザーのメールアドレスなどのコンテキストを使用することは、無限の基数を持つため、賢明ではない。
メトリクスを使用して、アプリケーションの各サブシステムで処理されるレイテンシとデータボリュームを追跡することができる。
これにより、正確に何が減速の原因となっているのかを簡単に特定できる
ログは多くのフィールドを記録することはできませんが、どのサブシステムに責任があるか分かるので、
どのユーザー要求が関係しているかを把握するのに役立つ。
これは、ログとメトリクスのトレードオフが最も明確になる場所です。
メトリクスを使用すると、プロセス全体からのイベントに関する情報を収集することができますが、
一般的には、限定されたカーディナリティーを持つ1つまたは2つ以上のコンテキストフィールドはない。
ログを使用すると、1つのタイプのイベントすべてに関する情報を収集できますが、無限の基数を使用して100項目のコンテキストしか追跡できません。
この基数の概念とそれがメトリクス上に置く制限は理解することが重要であり、後の章で取り上げる。
メトリクスベースの監視システムとして、Prometheusは個々のイベントではなくシステム全体の健全性、動作、パフォーマンスを追跡するように設計されています。
言い換えれば、Prometheusは、最後の15回のリクエストで処理に4秒かかり、40回のデータベースコール、17回のキャッシュヒット、
および顧客による2回の購入が発生したと考えています。個々の呼び出しのコストおよびコードパスは、プロファイリングまたはロギングの懸案事項です。
Prometheusが全体の監視空間にどこに収まるかを理解したので、Prometheusのさまざまなコンポーネントを見ていく。
Prometheus Architecture
下記は、Prometheusの全体的なアーキテクチャである。
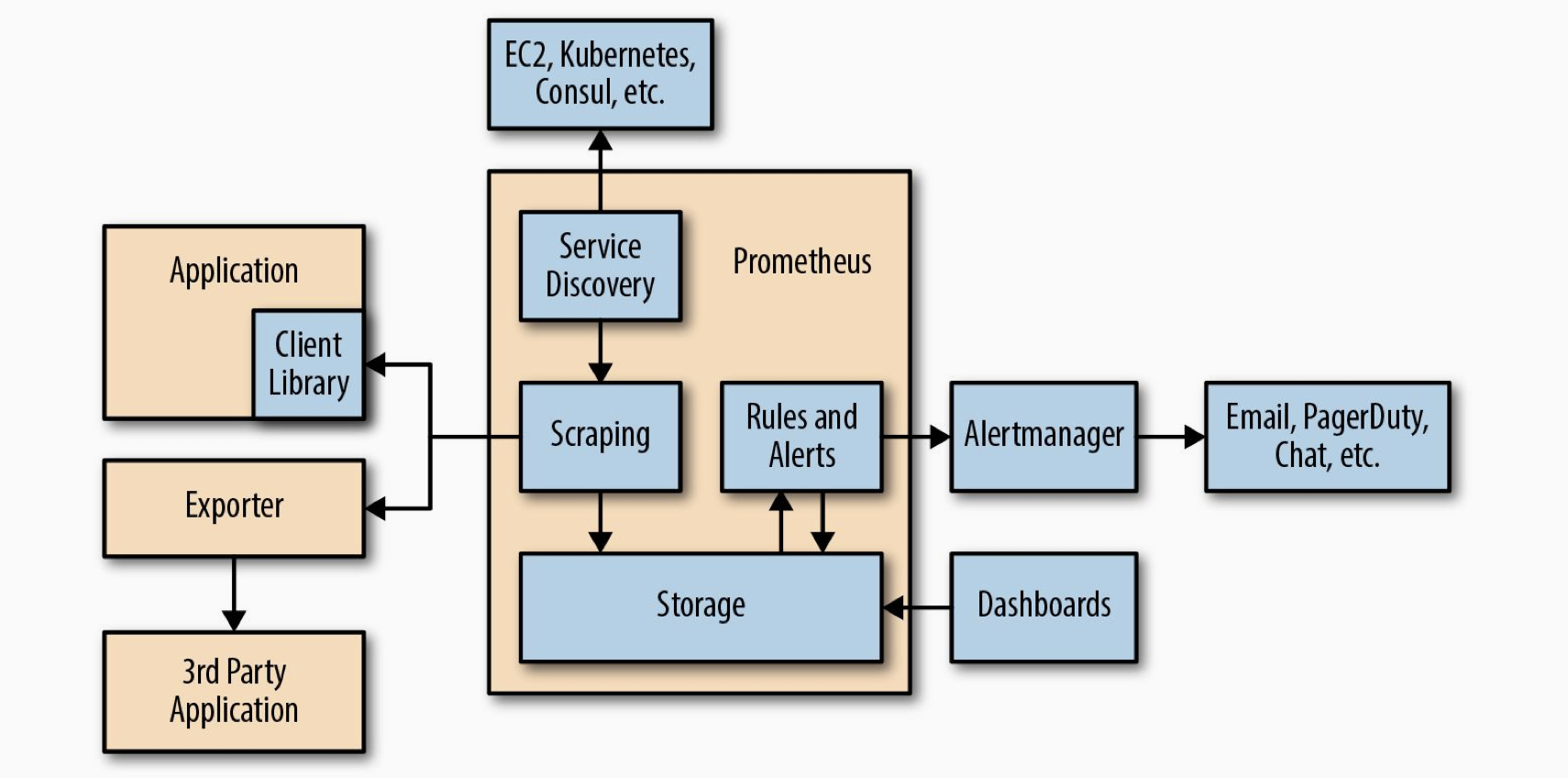
Prometheusは、service discoveryによりターゲットを発見します。
これらは、Exporter経由でスクレイプできる独自の計測アプリケーション
またはサードパーティ製のアプリケーションです。
スクレイプされたデータは保存され、PromQLを使用してダッシュボードで使用するか、
アラートをAlertmanagerに送信して、ページ、電子メール、およびその他の通知に変換する。
Client Libraries
メトリクスは通常、アプリケーションから魔法のように飛び出すことはなく、誰かがそれらを生成する機会を加える必要がある。
通常、わずか2〜3行のコードでは、メトリックを定義し、制御するコードにインラインで目的のインスツルメンテーションを追加できます。
これを直接計装といいます。 クライアントライブラリは、すべての主要言語とランタイムで使用できます。
Prometheusプロジェクトは、下記の言語で公式のクライアントライブラリを提供している。
- Go
- Python
- Java / JVM
- Ruby
またC#/などのサードパーティのさまざまなクライアントライブラリもあります。
Net、Node.js、Haskell、Erlang、およびRustが含まれます。
クライアントライブラリは、スレッドの安全性、簿記、HTTP要求に応じたPrometheusのテキスト提示形式の生成など、細部まで細かく処理します。
メトリックベースの監視では個々のイベントは追跡されないため、クライアントライブラリのメモリ使用量が増えてもイベントは増加しません。
アプリケーションのライブラリ依存関係の1つにPrometheusでの計測が含まれていると、自動的に選択されます。
したがって、RPCクライアントなどのキーライブラリを計装することによって、
すべてのアプリケーションでそのクライアント用の計測器を取得できます。一部のメトリクスは、通常、CPUなどのクライアントライブラリによって提供される。
使用状況、およびガベージコレクションの統計情報が含まれています。
クライアントライブラリは、Prometheusテキスト形式のメトリクスを出力することに限定さない。
Prometheusはオープンエコシステムであり、生成テキスト形式を供給するために使用された同じAPIを使用して、
他のフォーマットのメトリックを生成したり、他の計測システムにフィードしたりすることができる。
同様に、まだすべてをPrometheus計測に変換していない場合は、他の計測システムからメトリックを取り込み、Prometheusクライアントライブラリに組み込むことができます。
Exporters and integrations | Prometheus
Exporters
実行するすべてのコードが制御でき、アクセスできるコードではないため、直接計測を追加することは実際の選択肢としてはない。
たとえばOSのカーネルがPrometheus形式のメトリクスをすぐにHTTP経由で出力し始めることはほとんどなく、
メトリクスにアクセスするためのインタフェースから出力する。
これは、多くのLinuxメトリクスやSNMPなどの確立された、カスタムの解析と処理を必要とする特別なフォーマットである可能性があります。
Exporterは、メトリクスを取得したいアプリケーションの横に配置するソフトウェアです。
- Promehteusからの要求を受け取る
- アプリケーションから必要なデータを収集
- 正しいフォーマットに変換し
- Prometheusへの応答を返す
Exporterは、1対1の小さなプロキシと考えることができ、アプリケーションのメトリクスインタフェースとPrometheus形式の間でデータを変換します。
あなたが管理するコードに使用する直接計装とは異なり、ExporterはカスタムコレクタまたはConstMetricsと呼ばれる別のスタイルの計装を使用します。
良いニュースは、Prometheusコミュニティの規模を考えると、あなたがすでに必要とするものがおそらく存在し、
あなたの努力のために少しでも使えるということです。
もし興味のあるメトリックを見つけられない場合は、いつでもプルリクエストを送信して改善することがでるので、次の人がそれを使用するほうが優れています。
Service Discovery
Exporterを実行したら、Prometheusはどこにいるかを知る必要がある。
これはPromehteusが何を監視するのかを知り、監視対象のものが応答していない場合に気付くことができるようにするため。
動的な環境では、保持している監視対象のリストを期限切れにするだけでは、こと足りない。
Prometheusは、Kubernetes、EC2、Consulなどの多くの共通サービス発見メカニズムとの統合を行っている。
しかしPromehteusが監視対象のリストを持っているからといって、それがあなたのアーキテクチャにどのように適合しているかを知っているわけではない。
たとえば、EC2 Nameタグを使用して、アプリケーションがマシン上で実行されていることを示している場合や、appというタグを使用している場合があります。
すべての組織がわずかに違うので、Promehteusでは、Service Discoveryのメタデータを、
ラベルの付け替えを行うことにより監視対象をそのラベルにマッピングする方法を構成できます。
Scraping
Service Discoveryと再ラベル付けは、監視対象のリストを生成し
Prometheusは、Scrapeと呼ばれるHTTPリクエストを送信することでメトリクスの収集を行う。
SCrapingの応答は解析され、ストレージに取り込まれます。
スクレープが成功し、どれくらいかかったかなど、いくつかの有用な指標も追加されてる。
Scrapingの間隔はターゲットごとに10〜60秒ごとに実行するように設定するのが望ましい。
Prometheusはプルベースのシステムです。 その構成に基づいて、いつ、何をscrapeするかを決定する。
Prometheusのユーザーとして、pullがPrometheusの中心であると理解しておき、代わりにpushするようにしようとするのは賢明ではない。
Storage
Prometheusはデータをローカルのカスタムデータベースに保存します。
分散型システムは信頼性が高いため、Prometheusはクラスタリングをしないため、Prometheusの実行が容易になる。
長年にわたって、ストレージは数多くの再設計を経ており、Prometheus 2.0のストレージシステムは3回目の反復となる。
ストレージシステムは、毎秒数百万のサンプルを処理することができ、1台のPrometheusサーバーで数千台のマシンを監視することができます。
使用される圧縮アルゴリズムは、実際のデータで1サンプルあたり1.3バイトを達成できます。 SSDが推奨されますが、厳密には必要ではない。
Dashbords

プロメテウスには多数のHTTP APIがあり、生データを要求してPromQLクエリを評価することができ、グラフやダッシュボードの作成に使用できる。
Prometheusはブラウザを提供しており、アドホッククエリとデータ探索に適してるが、一般的なダッシュボードシステムではない。
ダッシュボードにはGrafanaを使用することがお勧め。
Prometheusをデータソースとして公式にサポートするなど、幅広い機能を備えている。
図1-2のような多種多様なダッシュボードを作成できます。
Grafanaは、単一のダッシュボードパネル内であっても、複数のPrometheusサーバーとの会話をサポートしてる。
Recording Rules and Alerts
PromQLとストレージエンジンは強力で効率的だが、グラフをレンダリングするたびに何千ものマシンからのメトリクスを集約すると、少し遅れてしまうことがある。
記録規則により、PromQL式は定期的に評価され、その結果はストレージエンジンに取り込まれる。
警告ルールは、記録ルールの別の形式です。
PromQL式も定期的に評価し、その式の結果はアラートになりAlertmanagerに送信されます。
Alert Management
Alertmanagerは、Prometheusサーバーからアラートを受信し、通知に変換します。
通知には、電子メール、Slackなどのチャットアプリケーション、PagerDutyなどのサービスがある。
Alertmanagerは、アラートを1対1で盲目的に通知に変換するだけではなく、
関連するアラートを1つの通知に集約し、通知の嵐を減らすために抑制することができ、異なるルーティングと通知の出力をそれぞれのチームごとに構成可能。
アラートの削除も可能で、メンテナンスが予定されている場合には、事前にスヌーズすることができる。
Alertmanagerの役割は、通知の送信を停止します。 PagerDutyや発券システムなどのサービスを使用すべきであるインシデントへの人の反応を管理するためです。
Long Term Storage
プロメテウスはローカルマシン上にのみデータを保存するため、そのマシンにどれくらいのディスク容量があるかによって制限がある。
通常、最も最近の日またはそれほどの価値のあるデータのみを気にするが、長期的な容量計画では、より長い保存期間が望ましい。
プロメテウスは、複数のマシンにまたがってデータを格納するためのクラスター化されたストレージソリューションを提供していないが、
他のシステムがこの役割を引き受けられるようにするリモートの読み取りおよび書き込みAPIがある。
これにより、ローカルデータとリモートデータの両方に対して、PromQLクエリを透過的に実行することが可能。
What Prometheus Is Not
Prometheusが広範な監視環境に適合するか、その主要コンポーネントが何であるかを知ったので、
Prometheusが特に良い選択ではないユースケースを下記に記載。
- メトリクスベースのシステムとして、プロメテウスはイベントログや個々のイベントの保存
- 電子メールアドレスやユーザー名など、上位のカーディナリティデータ
プロメテウスは、カーネルのスケジューリングやスクレーピングの失敗などの要因による小さな不正確さや競合状態が人生の事実である業務監視用に設計されている。
プロメテウスは、トレードオフを行い、完璧なデータを待っている間に監視を破ることより99.9%正確なデータを提供することを好む。
したがって、お金や請求を伴うアプリケーションでは、プロメテウスを慎重に使用する必要がある。
最後までみていただきありがとうございます。
2章については訳して読みながら
ゆっくり書いていこうと思っています。