はじめに
こんにちは!エン・ジャパン株式会社でバックエンドエンジニアをしております、長谷部です。
この記事では、先日新卒組で参加した AWS JumpStart 2023 for NewGrads設計編 という研修から、
「アーキテクチャ設計」 について学んだことを、主に個人的な視点でまとめてみました。
あくまで筆者が勉強になった部分をピックアップしていますので、「AWSの研修で何を行なったか」という内容の記事ではないことをあらかじめご了承ください。
また、理解が曖昧な部分や間違っている部分もあるかとおもいます。
見つけた際は、是非コメントでご指摘いただけたらと思います。
アーキテクチャ設計について
アーキテクチャ設計とは何か
機能・非機能要件、制約条件を満たすシステム全体の設計を、ソフトウェアだけでなくインフラの観点も含めて行うこと(AWSの資料から引用)
クラウド上で運用するにあたって、機能要件だけでなく、非機能要件にも考慮したシステム全体のアーキテクチャ設計が重要になる、ということみたいです。
アーキテクチャ設計のポイント
アーキテクチャ設計を行う上で、ポイントだと感じたのは
- 可用性
- スケーラビリティとパフォーマンス
- コスト
の3つです。
お恥ずかしながら、私は今回の講習を受けるまで、正直言ってスケーラビリティと可用性の違いについてはっきりと理解ができていなかったです。
ということで自分のためにも改めておさらいしながら紹介していきたいと思います。
可用性について(Availability)
はじめに、可用性の観点から見たAWSのアーキテクチャ設計についてです。
可用性とは
可用性とは、システムが継続して稼働できる能力のこと
例えばサーバーが落ちてしまったとしても、問題なくサービス提供を続けられるか、そういう状態にあるか、という視点だと思っています。
以下はすごく極端な例になりますが、可用性が低い場合と高い場合でサービスが提供できるできないを表した図になります。

- 可用性が低い
- あるサーバーが落ちた時にサービスの提供が停止する
- 可用性が高い
- あるサーバーが落ちた時でもサービスの提供が続けられる
可用性の観点で見たAWSのアーキテクチャ設計
AWSではこの可用性への対応方法として、いくつかの方法を挙げていました。
1. 複数個インスタンス(サーバー)を設置する。
これは単純で、
複数個インスタンスを置くことで、どれか1個サーバーがダウンしてしまっても、他のインスタンスが代わりにサーバーになる
ということです。
これで、片方のインスタンスが落ちてしまった場合でも、継続してサービスを提供することができます。

しかし、これにも欠点はあります。
それは、このインスタンスを置いてある場所自体(データセンター)がダウンしてしまったとき、可用性が担保されていない、という点です。
AvailabilityZoneという考え方
AWSでは、AvailabilityZoneという考え方があります。
上記の複数個インスタンスを置いたのは、1つのAvailabilityZone内 という想定でした。
では、「このAvailabilityZone自体が何かしらの原因でダウンしてしまったら?」というところに対応した解決策が次の2つめの方法になります。
2. 複数のAvailabilityZoneにそれぞれインスタンスを設置する
AvailabilityZone自体は一定距離離れているところにあるので、片方のAvailabilityZoneが落ちたとしても、その影響が他のAvailabilityZoneにいくことは滅多にないらしいです。滅多にないだけで、状況としては起こり得るとは思いますが。
複数のAvailabilityZoneにインスタンスを置くことで、片方のAvailabilityZoneがダメになっても、もう片方のAvailabilityZoneにあるインスタンスが代わりのサーバーとなり、サービスは継続して提供できる状態が出来上がる、というわけです。
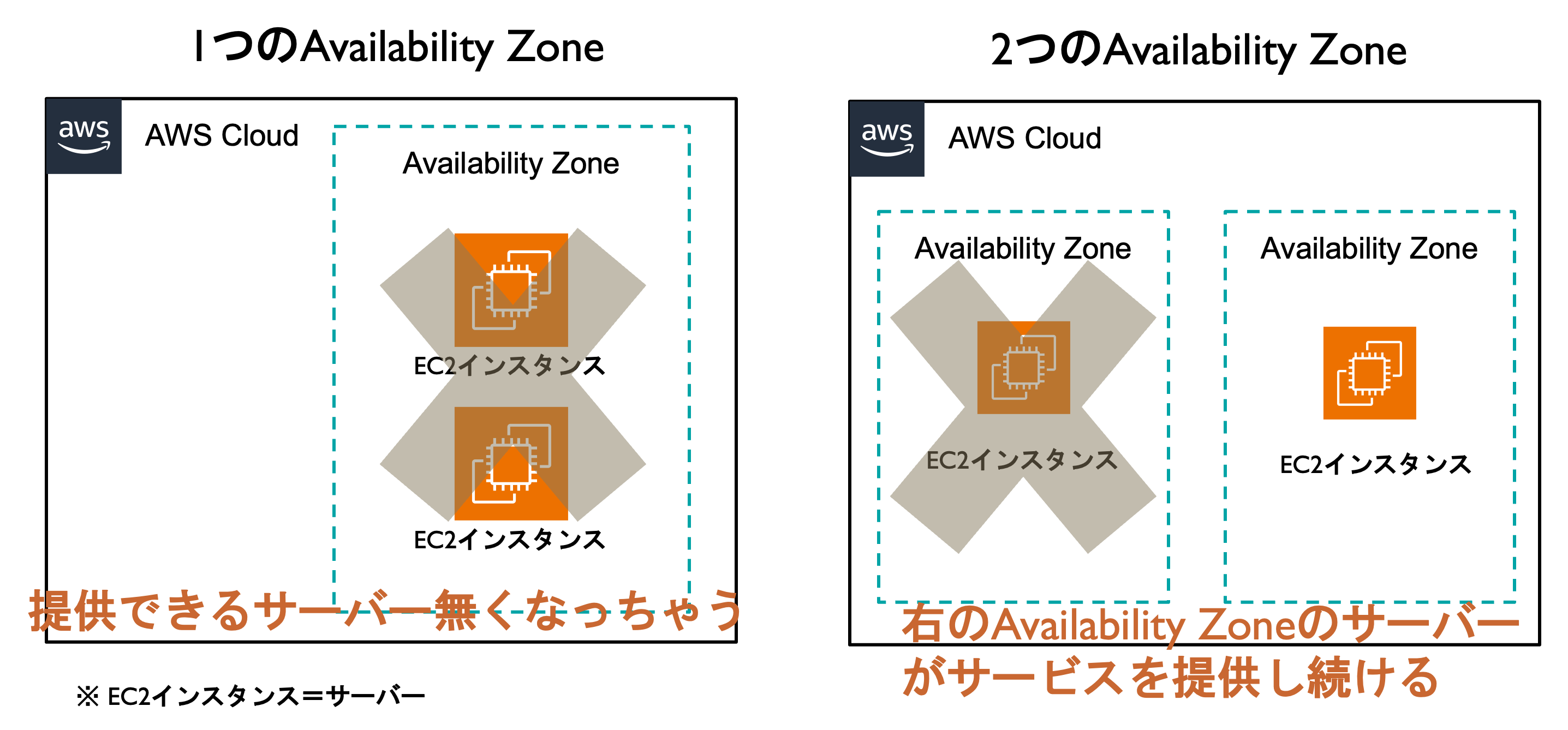
大体AWSの手順ブログを見ていたりすると、AvailabilityZoneを2つ置いたりしているのは、可用性の観点から見た設計である ということが理解できました。
スケーラビリティについて
次に、スケーラビリティの観点からみたAWSのアーキテクチャ設計についてです。
スケーラビリティとは
スケーラビリティとはシステムやネットワークなどが、規模や利用負荷などなどの増大に対応できる度合いのこと
例えば、
- サービスを始めた当初に比べて最近利用者10倍に増えているけど、サーバーはこのままで耐えられそう?
- 朝と昼と夕方で利用人数、アクセス数違うけど、ずっと同じである必要あるの?
という視点だと思っています。
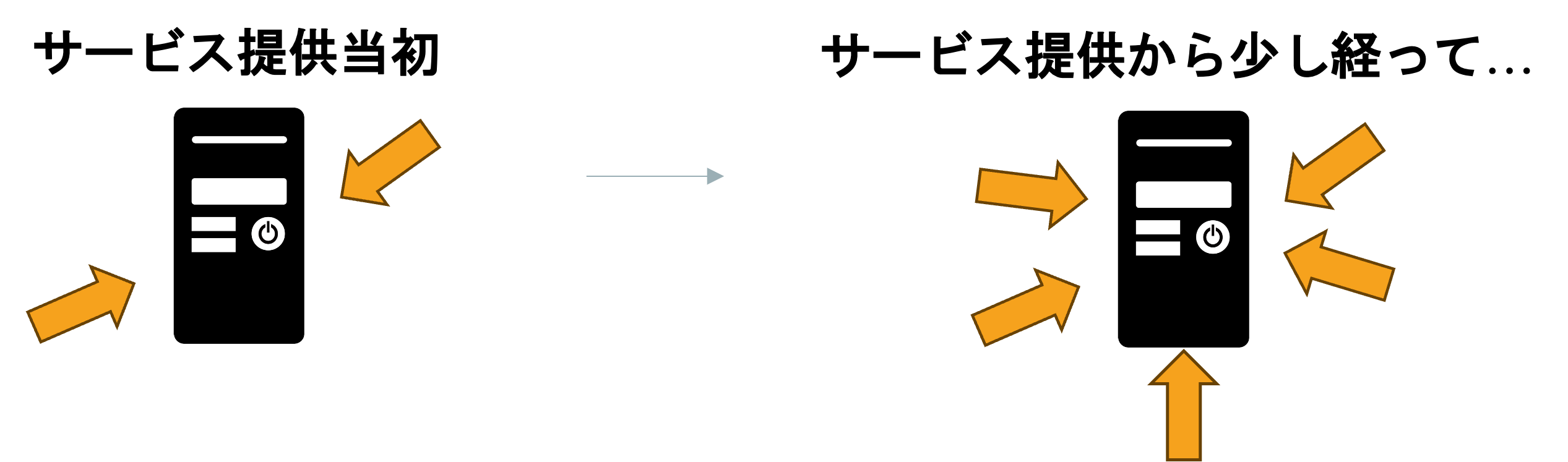
(矢印だと攻撃のように見えますが、この矢印はアクセスを表しています)
スケーラビリティへの対応の考え方として、まずスケールアップ(ダウン)とスケールアウト(イン)の紹介をします。
スケールアップ(ダウン)
サーバーのスペックを変化させること
サーバー自体のスペックを増減させることでサーバーとしての能力値をコントロールします。
スケールアウト(イン)
同じスペックのサーバーの台数を変化させること
サーバー1台のスペックは変わりませんが、同じスペックのサーバーの数を増減させることで、サーバーとしての能力値をコントロールできます。

スケールアップ(ダウン)では本体自体の限界値があるので、スケールアウト(イン)が可能な構成にすることをAWSでは推奨していました。
AutoScaling
そして講習ではスケーラビリティへの対応の一例として、AutoScalingの活用について紹介されていました。
AutoScalingとは
アクセスなどによって増減する負荷に対応して、インスタンスの数を自動で増減してくれる仕組み
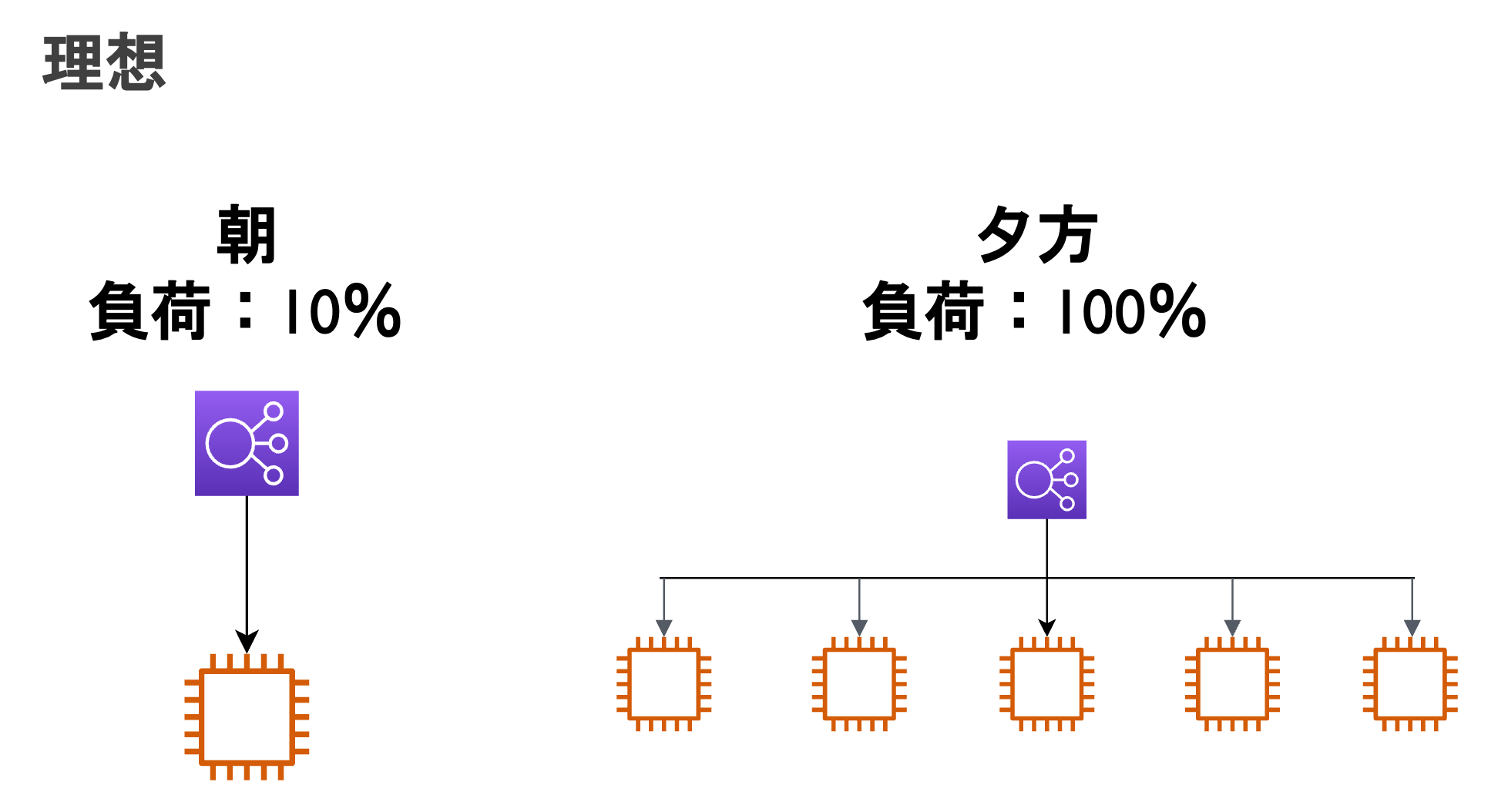
例えば、朝と夕方でインスタンスへの負荷が変化する場合を見てみましょう。
AutoScalingの活用方法
-
AutoScalingを利用しない場合
- 基準:最大の負荷に耐えられるような設計と運用
- 問題点:無駄なコストがかかってしまう
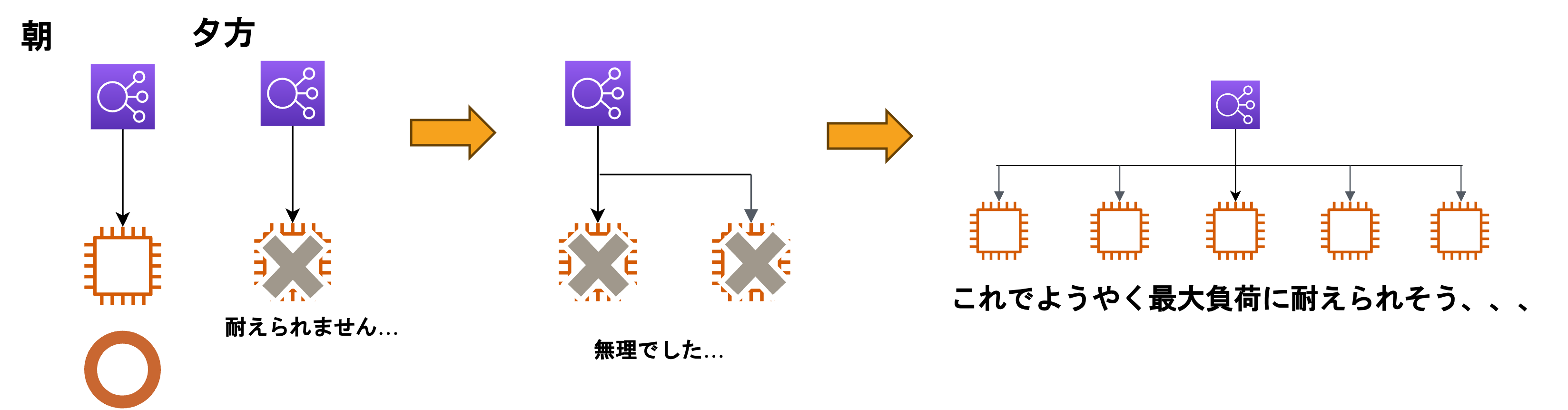
石油王でない限り大体の人は、「無駄なコストは省いていきたい」という気持ちになると思います。
と、いうことで、理想を以下のように想定します。
-
AutoScalingを利用する場合
- 理想の基準:常に負荷が40〜50%くらいをキープしている状態
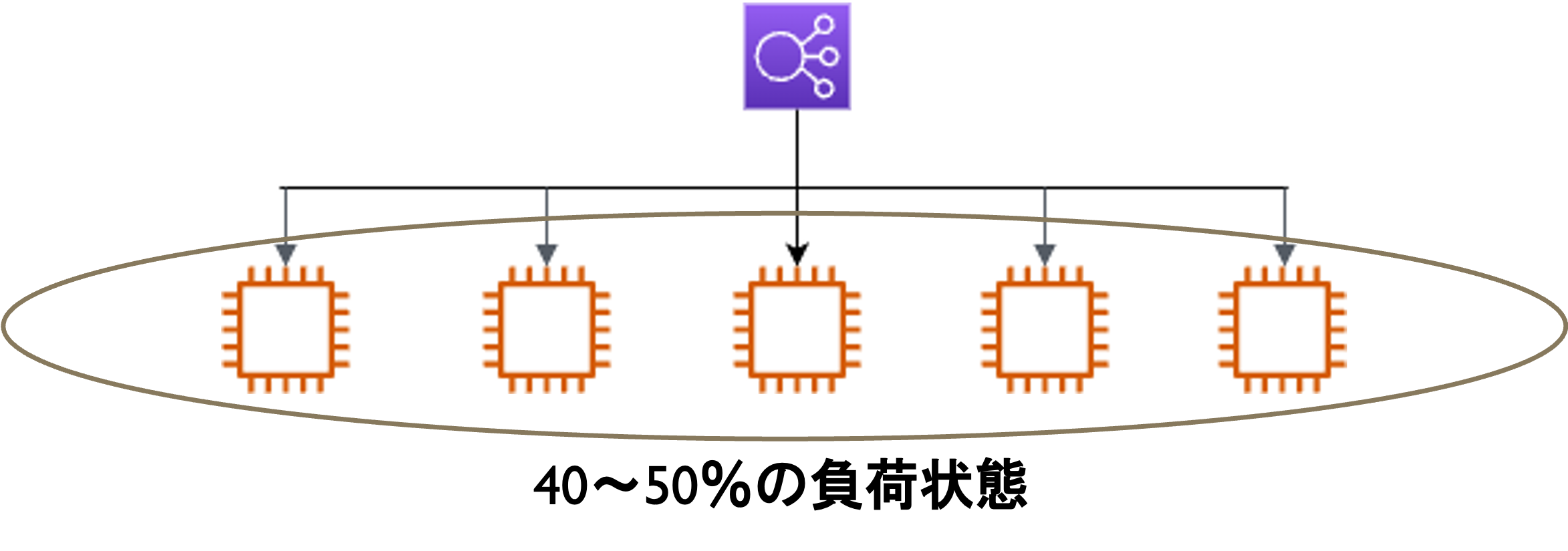
もっと具体的にいうと、
- 負荷がかかっていない時:少ない台数
- 負荷がかかっている時:40〜50%をキープするためにインスタンスの台数を増やす
→上記のインスタンスの増減を自動でしてほしい!
この理想を叶えてくれるのがAutoScalingという仕組みで、AutoScalingを実装することでスケーラビリティな状態を作ることができます。
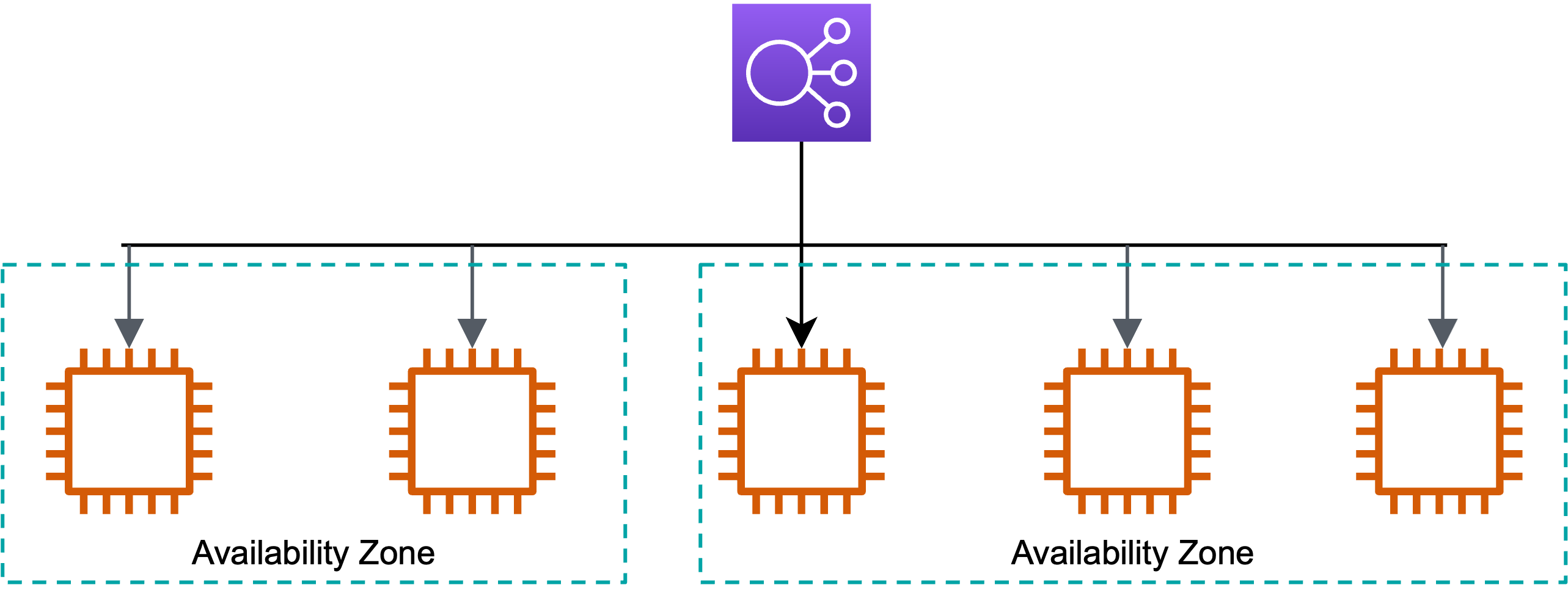
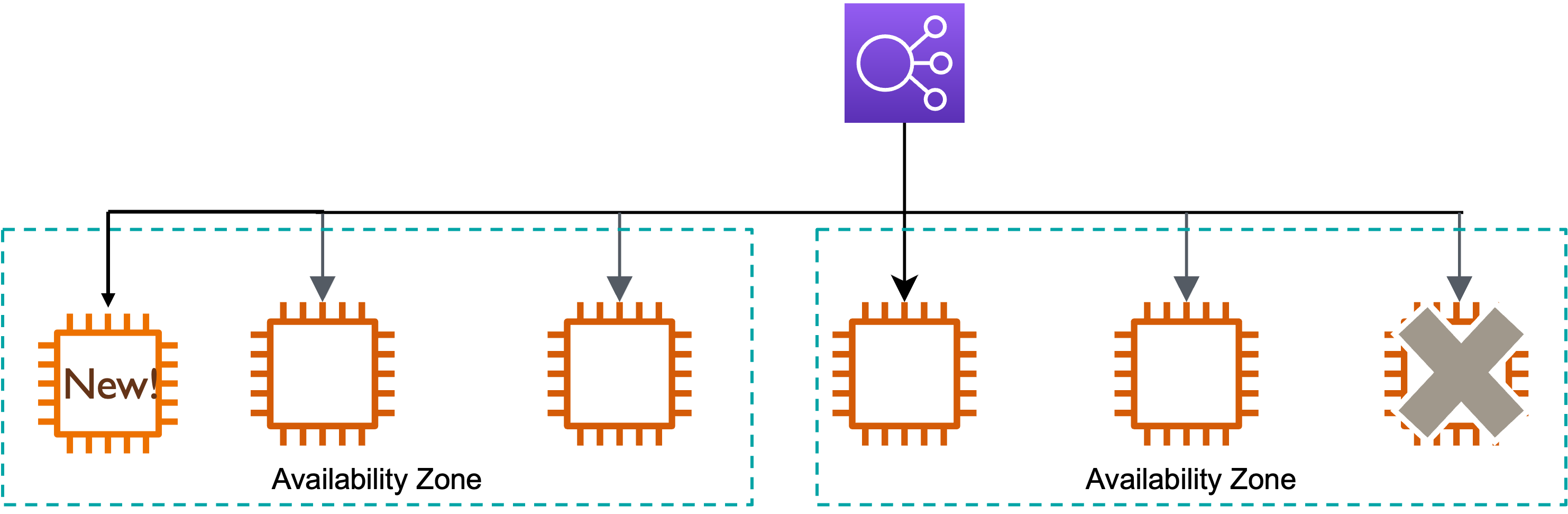
さらに、複数AvailabilityZoneにまたがって設置することで、どっかのAZがダウンしても、生きている違うAZに新たにインスタンスを自動で設置してくれます。
- 複数AvailabilityZoneにインスタンスを設置
- 1つのサーバーが落ちた!
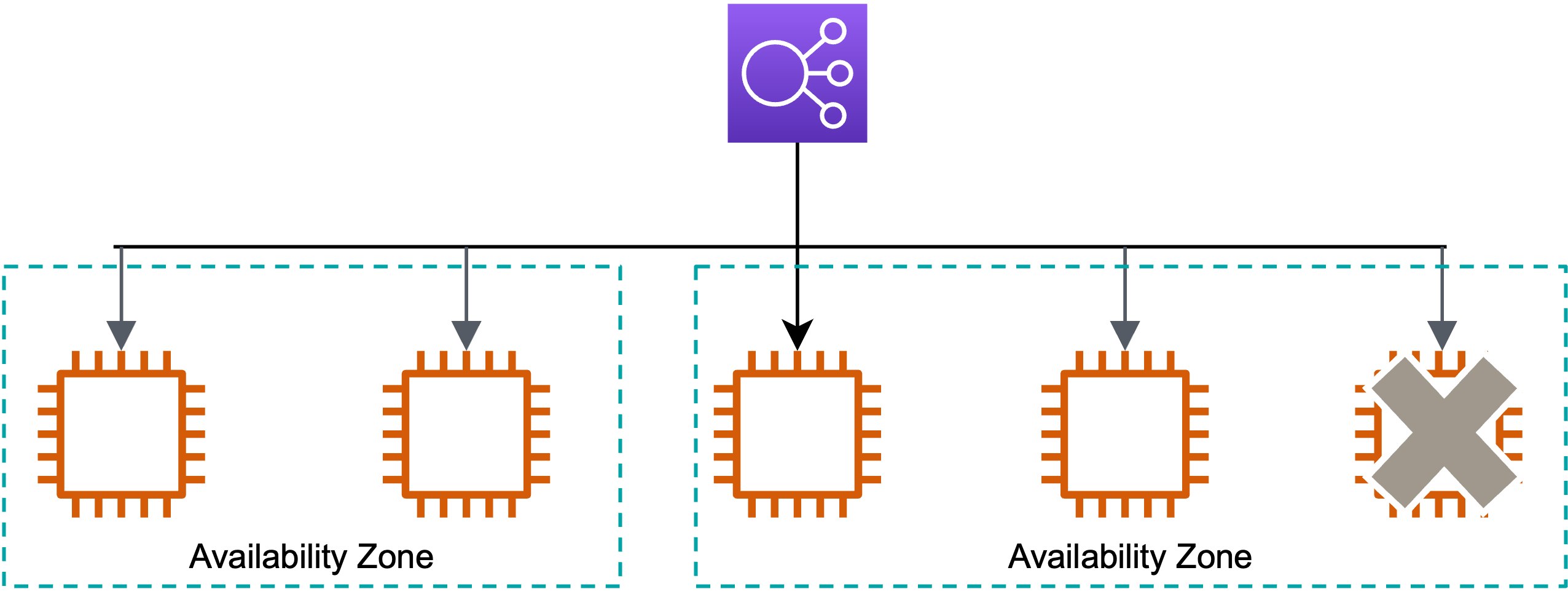
- 自動でインスタンスを設置
まとめ
今回の研修で、曖昧だった可用性とスケーラビリティの違いと、それぞれの特徴、設計方法について理解を深めることができました。
業務の中でも今回学んだことを活かしたAWSの設計に携われたりしたら楽しそうだなと思いました。
他に学んだこととして、AWSのデータベースサービスであるRDSについてですがDBとAuroraの違いや、サーバーレスのサービスの考え方、活用方法など、チームで話し合いながら学んだ部分も多かったのですが、ここら辺はまた違う記事として作成したいと思います。
最後になりますが、AWSの方が
「クラウドの本質は自動化、人の手が介入せず復旧できる」
と言っていたのが印象的でした。
ここまで読んでくださりありがとうございました!