概要
- 最近、障害が頻発した
- 障害について独自の理論やベストプラクティスを考えた
体系化された理論とかすでにありそう。
ゴールの定義
ゴールを「障害に絡んだビジネスへのダメージを最小化」することにします。
障害にまつわる話題、
監視、冗長化、メトリクス、ログ、ヘルスチェック・・・
こういう話題がなぜ語られるかというと、最終的に障害に絡んだビジネスへのダメージを最小化したいから。
ゴールと様々な要素の関係
障害に至るかていを考えた。
外乱が発生(アンコントローラブル)
-> 外乱によってシステムがダメージを受ける (冗長化などで影響の受け方をコントロール可能)
-> ダメージが観測される (アラートなど)
-> ダメージを調べる (ログ、メトリクスなど)
-> ダメージが軽減される (対応など)
-> ダメージがスレッショルドを超える
-> 障害発生
関係を書いてみた。
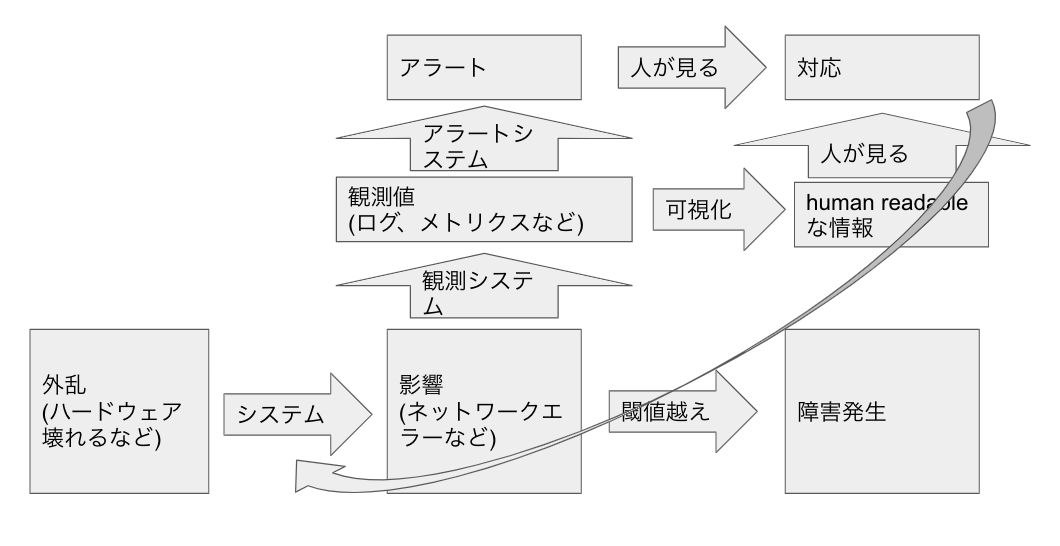
観測システムより上を監視システムとくくって大きく見ると
以下のようになる。
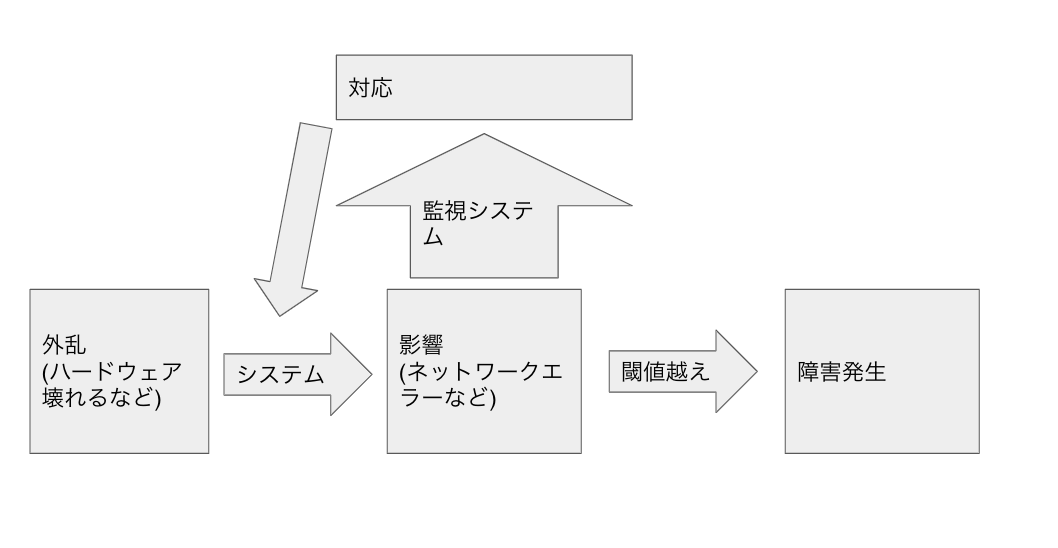
つまり、監視システムはフィードバックループを入れていることになる。
このモデルで例えば、
良いシステムは適当に仮定した外乱とかけられるコストのもとで、障害発生率を最小化するものである。
と定義できるかもしれない。
どこに投資するべきか?
どのような外乱を想定するかによって、どこに投資するのが最適かが変わる。
想定される外乱
- ハードウェアの故障
- インフラのバグ
- アプリケーションのバグ
- リソース
- アクセス過多
ミクロかマクロか
例えば、httpのヘルスチェックは、メモリ不足ではない、ハードウェアが故障していない、ネットワークの設定が間違えていないなど、複数のことを同時に確認できる。
反面、前兆を捉えることはできない。(メモリがじわじわ増えていっているなど)
チェック方法ごとにいろいろな性質が変わる。
- 前兆を補足できるか?
- 同時にチェック可能な範囲
自動か監視か
ハードウェアの故障は自動で対応可能だが、
プログラムのバグは自動では対応できない。
自動でやるのがコストがかかるなと思ったら、監視で対応すれば良いのでは?
ぼくの考えた最強のベストプラクティス
0. ユーザーの反応
デフォルトでユーザーの反応という監視が入っていることを認識する。
1. なるべく範囲の広い監視を入れる
例えば、自動販売機なら、お金を入れてものを買って、おいしいジュースが飲めるか?を定期的に監視する。
これで、2以降の監視の不備を補足できる。
他にも、ポピュラーな監視(リソース監視、httpステータス監視など)は入れても良い(ポピュラーな監視は、ポピュラーな外乱分布を反映して作られているはずなので)。
2. 0または1で障害が補足された場合、再発防止をする
過去に発生したものは、将来も発生する可能性が高いとして、再発防止をする。
再発防止方法は3以下。
3. 前兆を補足できるような監視を入れる
修正した上で、
万が一修正に不備があっても、監視で補足できるようにする。
メモリ不足で障害が発生したなら、メモリ不足の原因を修正した上で、メモリ不足になりそうかどうかを監視する。
なぜ2重に入れたほうが良いと思うのかはロジカルに説明できないが、なんとなくそんな気がする。
2倍のコストで、修正に不備がある確率を^2にできる。
4. 前兆が無いものは、前兆が出るようにする
例えば、
ハードウェアの故障は前兆を捉えるのが難しいので、
冗長化によって、一部の故障が障害ではなく障害の前兆になるようにする。
プログラムのロジックとかならエラーになる前に警告を入れたり、エラーになってもぎりぎり大丈夫なようにする。
具体論
自分で調べたもののメモ。
ELK
メトリクス計測、可視化、アラートができるセット。
elastic searchとかkibanaとかのセット。
流通しているdocker-composeがうまく動かなかったので試していない。
Grafana + prometheus + cadvisor + node exporter
メトリクス計測、可視化、アラートができるセット。
良かった。
railsのこれも良い。
https://github.com/discourse/prometheus_exporter
- Grafana: いろいろなdata sourceのデータ(prometheusのデータなど)を見やすく可視化するツール。アラートも飛ばせる
- prometheus: メトリクスを読み書き保存できるサーバー。
- cadvisor: prometheusにdockerのメトリクスを送るやつ
- node exporter: prometheusにマシンのメトリクスを送るやつ
- prometheus_exporter: prometheusにrailsのメトリクスを送るやつ
https://app.bugsnag.com
無料でrailsのエラーログを集めて見やすく可視化できた。
アラートも飛ぶ。
railsから直接APIで送る方式。
fluentdとかそういうのが登場しないから、インテグレーションが楽だった。
https://uptimerobot.com/
無料でヘルスチェックできた。アラートも飛ばせる。
雑感
このやり方自体がアルゴリズムな気がする。
外乱の分布が未知な状態で、外乱に強いシステムをオンラインアルゴリズムで低コストに作るにはどうすれば良いか?という問題。
そもそも手作り感満載の運用フローでやってるから、障害が発生するんだと思ってkubernetesとか少し調べたが、覚えることがかなり多くて断念。
運用フロー全体を変えないで最小コストで障害発生率を下げるにはどうするんだ?と考えて、この記事のことを考えた。
監視によってフィードバックループが作られることと、ベストプラクティスは自分にとって新しい発見だった。