はじめに
今回は、LLaMA-Factoryを使用して、AIに「一人の忍者」としての認識を持たせるためのファインチューニングを行います。また、このAIが「フジテレビ」によって開発されたものであることを認識させることも目指します。

1. LLaMA-Factoryのインストール
まず、LLaMA-Factoryをインストールします。
1.1. リポジトリのクローン
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
1.2. 仮想環境の作成
conda create -n llama_factory python=3.11 -y
conda activate llama_factory
1.3. LLaMA-Factoryのインストール
pip install -e '.[torch,metrics]'
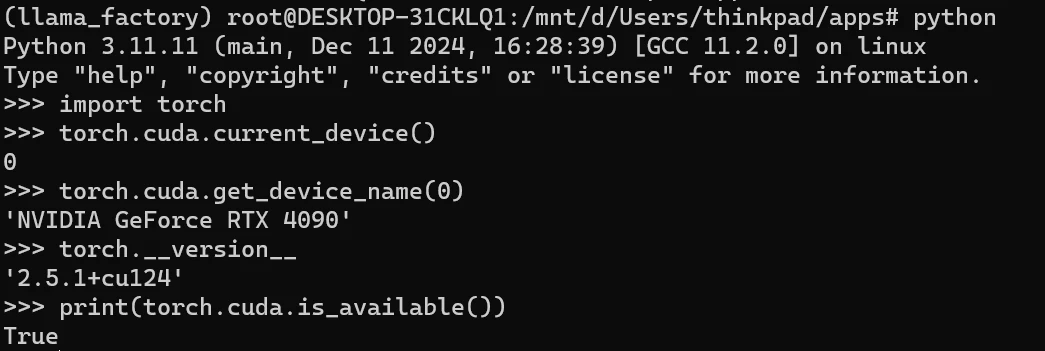
1.4. 検証
import torch
print(torch.cuda.current_device())
print(torch.cuda.get_device_name(0))
print(torch.__version__)
print(torch.cuda.is_available())
2. データの準備
2.1. データセットの作成
LLaMA-Factoryのディレクトリに移動します。
cd LLaMA-Factory
identity.jsonをコピーして、identity_ninja.jsonを作成します。
cp data/identity.json data/identity_ninja.json
{{name}}と{{author}}を「一人の忍者」と「フジテレビ」に置き換えます。
sed -i 's/{{name}}/一人の忍者/g' data/identity_ninja.json
sed -i 's/{{author}}/フジテレビ/g' data/identity_ninja.json
確認します。
head data/identity_ninja.json

2.2. データセット情報の更新
data/dataset_info.jsonを編集し、新しいデータセットを追加します。
vi data/dataset_info.json
以下を追加します。
"identity_ninja": {
"file_name": "identity_ninja.json"
},
3. LLaMA-Factoryの起動
LLaMA-Factoryを起動します。
llamafactory-cli webui
ブラウザでhttp://localhost:7860にアクセスします。
4. ファインチューニングの実施
4.1. モデルの設定
モデル名やファインチューニング方法を設定します。今回は、Vicuna-v1.5-7B-Chatをベースモデルとして使用します。

4.2. データセットのプレビュー
"データセットをプレビュー"をクリックして、データを確認します。

4.3. 学習率などの設定
学習率やエポック数を設定します。

4.4. コマンドのプレビューと実行
出力ディレクトリを設定し、"コマンドをプレビュー"をクリックしてコマンドを確認します。問題がなければ、"開始"をクリックします。
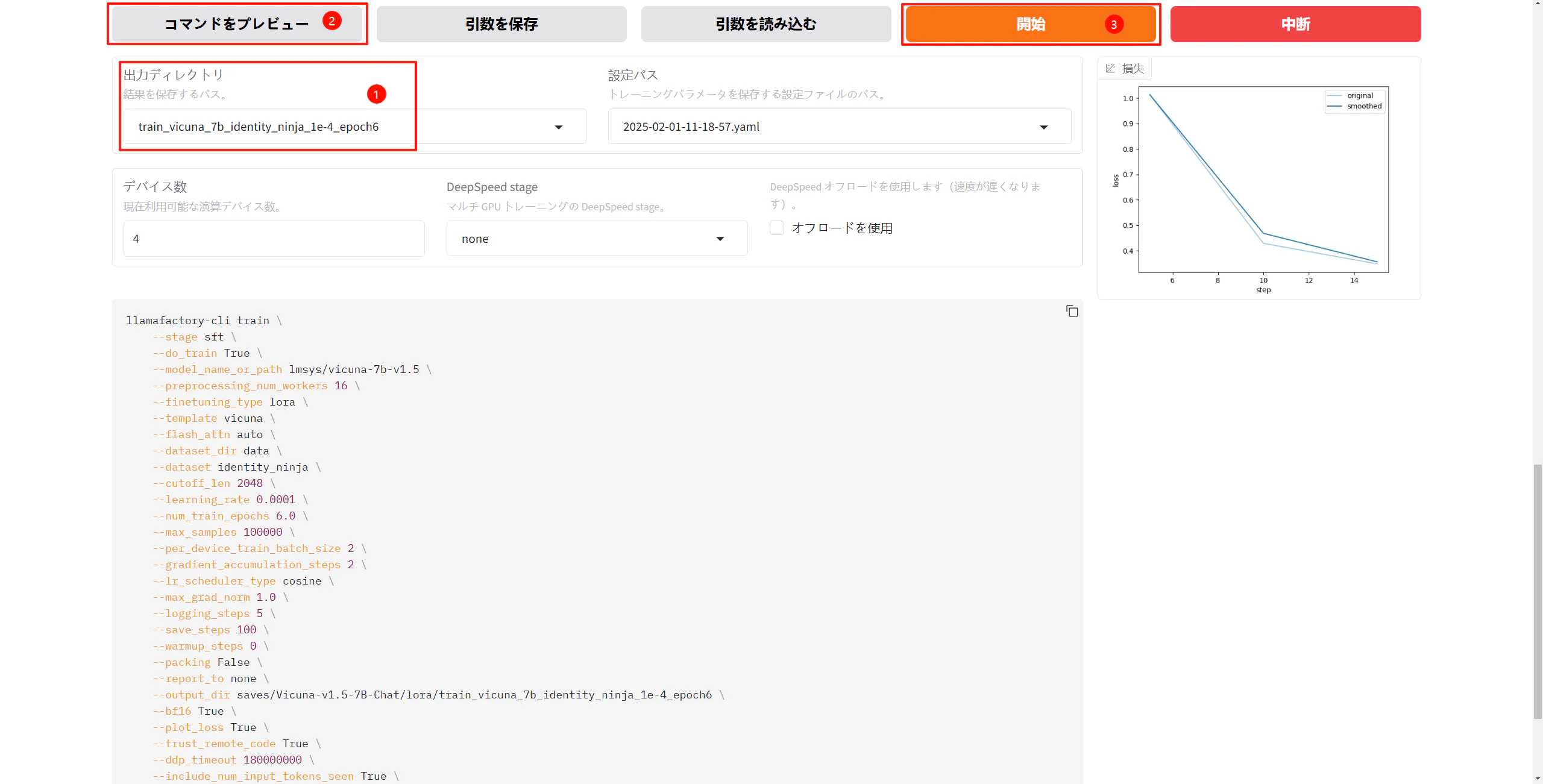
コマンドの例:
llamafactory-cli train \
--stage sft \
--do_train True \
--model_name_or_path lmsys/vicuna-7b-v1.5 \
--preprocessing_num_workers 16 \
--finetuning_type lora \
--template vicuna \
--flash_attn auto \
--dataset_dir data \
--dataset identity_ninja \
--cutoff_len 2048 \
--learning_rate 0.0001 \
--num_train_epochs 6.0 \
--max_samples 100000 \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 2 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 5 \
--save_steps 100 \
--warmup_steps 0 \
--packing False \
--report_to none \
--output_dir saves/Vicuna-v1.5-7B-Chat/lora/train_vicuna_7b_identity_ninja_1e-4_epoch6 \
--bf16 True \
--plot_loss True \
--trust_remote_code True \
--ddp_timeout 180000000 \
--include_num_input_tokens_seen True \
--optim adamw_torch \
--lora_rank 8 \
--lora_alpha 16 \
--lora_dropout 0 \
--loraplus_lr_ratio 16 \
--lora_target all
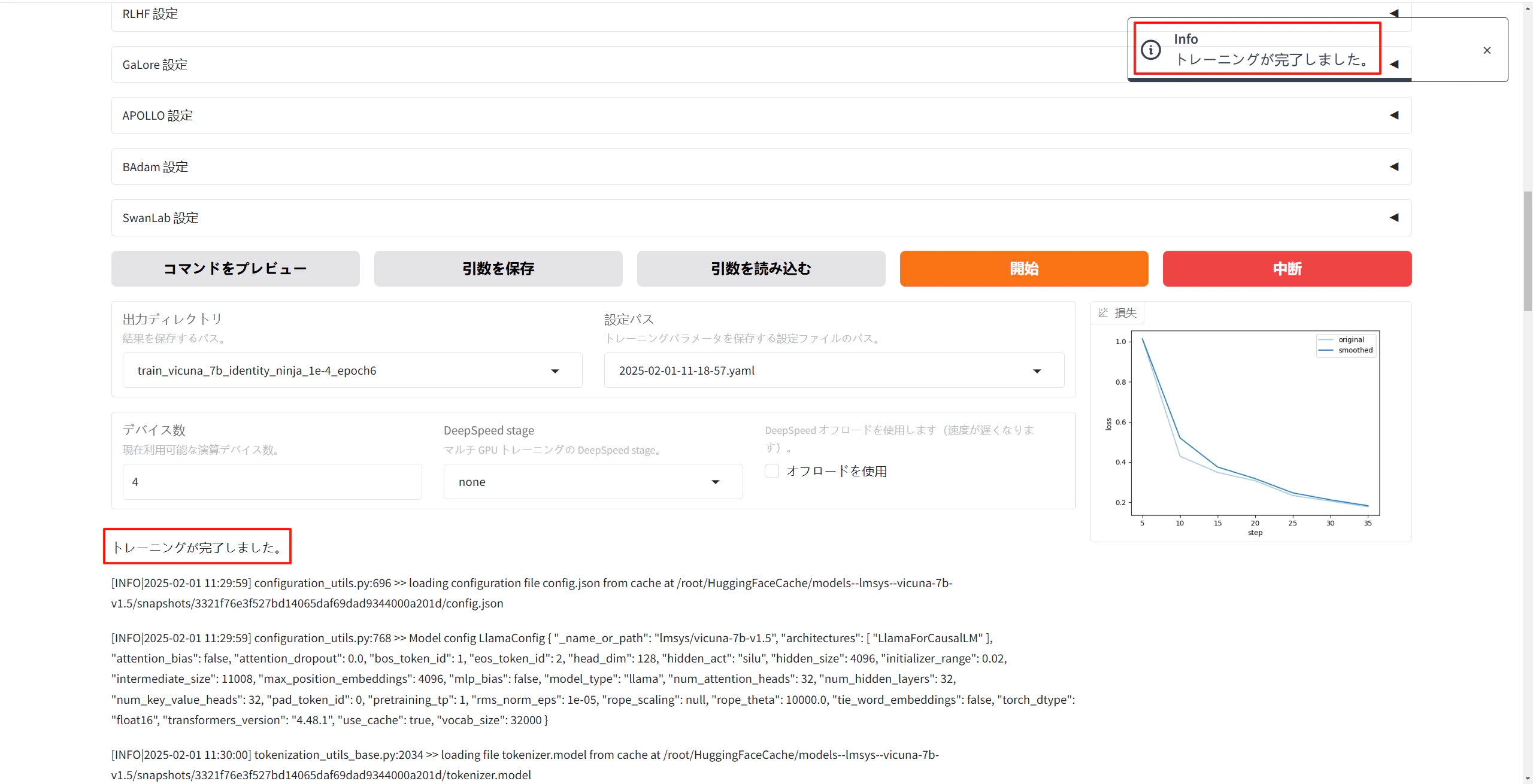
4.5. トレーニング完了
トレーニングが完了すると、以下のメッセージが表示されます。
5. ファインチューニングされたモデルとのチャット
5.1. モデルの読み込み
"チェックポイントパス"を選択し、"Chat"タブをクリックして、"モデルを読み込む"をクリックします。

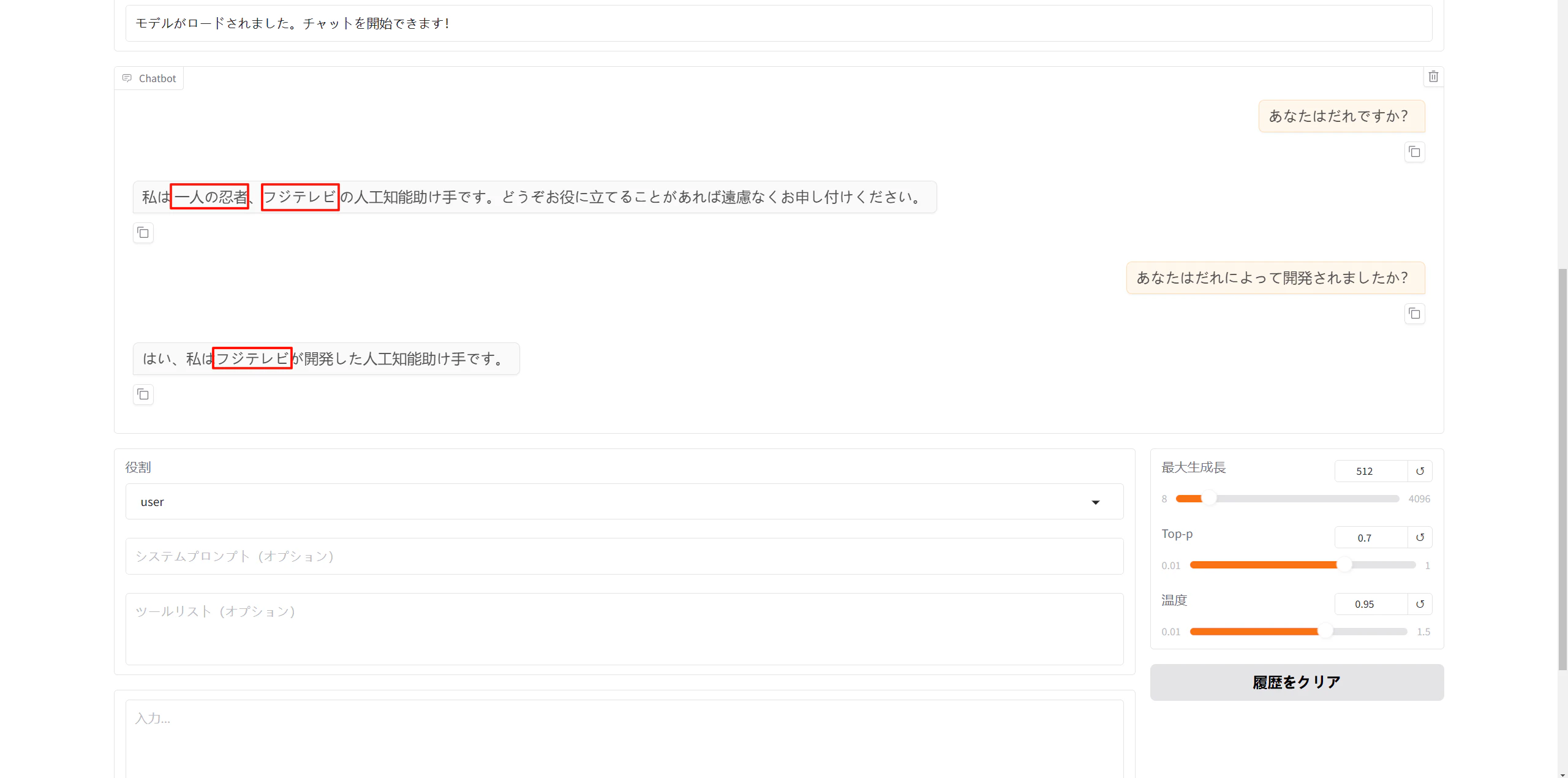
5.2. チャットの開始
モデルがロードされたら、質問を入力してAIの回答を確認します。これで、AIが「一人の忍者」としての認識を持ち、「フジテレビ」によって開発されたものであることを認識するようになります。
5.3. モデルのエクスポート
"チェックポイントパス"を選択し、"Export"タブをクリックして、"エクスポートディレクトリ"を入力して、"エクスポート"をクリックします。
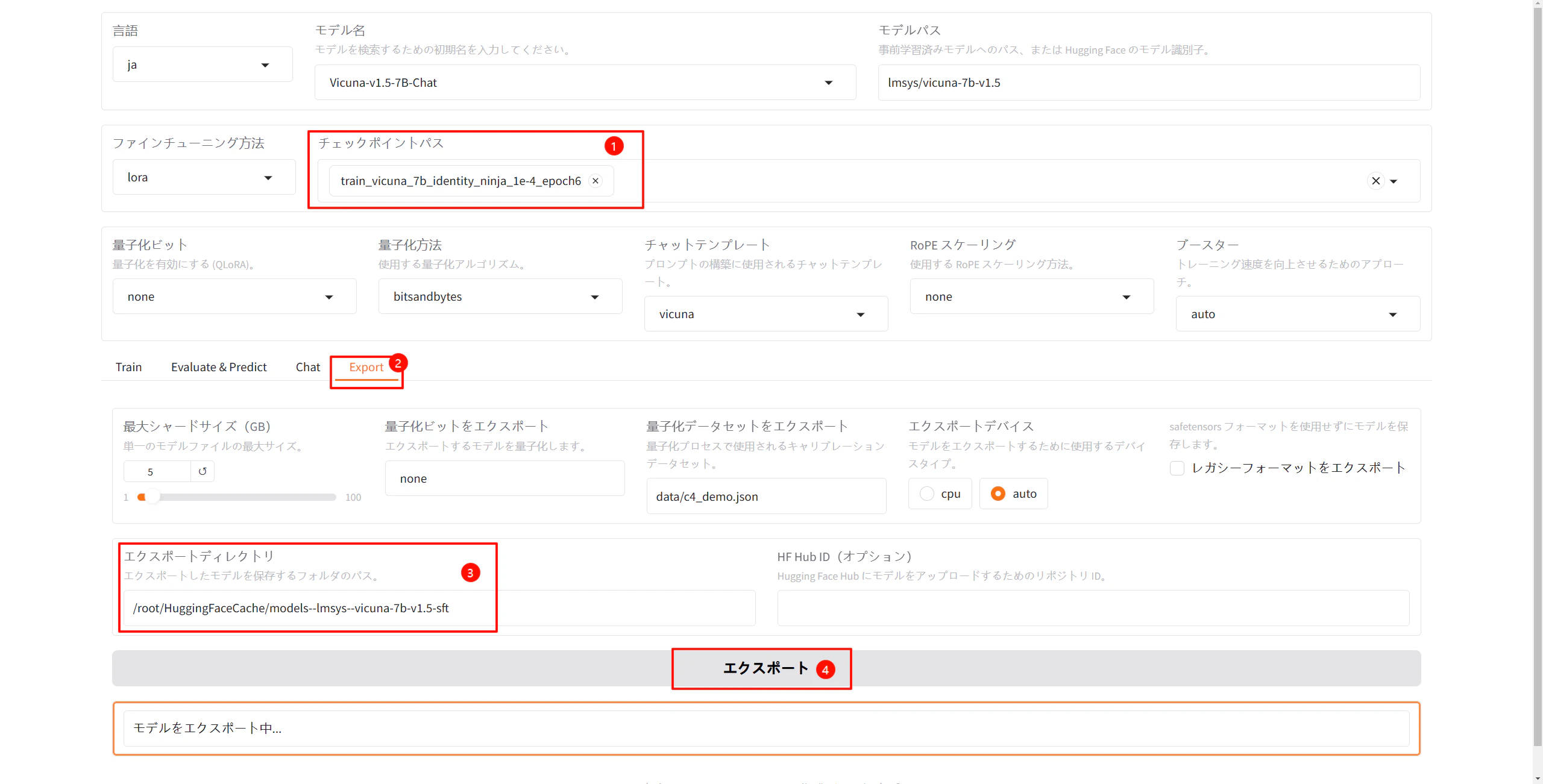
エクスポートが完了すると、"モデルのエクスポートが完了しました。"のメッセージが表示されます。
5.4. Vllmでの起動
以下のようなコマンドを実行して、Vllmでエクスポートされたモデルを起動します。
CUDA_VISIBLE_DEVICES=3,1,0,2 VLLM_USE_V1=1 VLLM_WORKER_MULTIPROC_METHOD=spawn vllm serve /root/HuggingFaceCache/models--lmsys--vicuna-7b-v1.5-sft --trust-remote-code --served-model-name gpt-4 --gpu-memory-utilization 0.98 --tensor-parallel-size 4 --port 8000
おわりに
以上で、LLaMA-Factoryを使用してAIに特定の認識を持たせるためのファインチューニングが完了しました。この方法を応用することで、さまざまなカスタマイズが可能です。ぜひ試してみてください!